日志分析项目
日志数据分析案例
1.背景
1.1 某论坛日志,数据分为两部分组成,原来是一个大文件,是56GB;以后每天生成一个文件,大约是150-200MB之间;
1.2 日志格式是apache common日志格式;
1.3 分析一些核心指标,供运营决策者使用;
1.4 开发该系统的目的是分了获取一些业务相关的指标,这些指标在第三方工具中无法获得的;
2.开发步骤
2.1 把日志数据上传到HDFS中进行处理
如果是日志服务器数据较小、压力较小,可以直接使用shell命令把数据上传到HDFS中;
如果是日志服务器数据较大、压力较答,使用NFS在另一台服务器上上传数据;
如果日志服务器非常多、数据量大,使用flume进行数据处理;
2.2 使用MapReduce对HDFS中的原始数据进行清洗;
2.3 使用Hive对清洗后的数据进行统计分析;
2.4 使用Sqoop把Hive产生的统计结果导出到mysql中;
2.5 如果用户需要查看详细数据的话,可以使用HBase进行展现;
3、详细代码
3.1、使用shell命令把数据从linux磁盘上传到HDFS中
![]()
3.1.1 在hdfs中创建目录,命令如下
[root@node1 hadoop-2.5.1]# hadoop fs -mkdir -p /tbbs_logs
![]()
得到前一天的时间
[root@node1 apache_logs]# date --date='1 days ago' +%Y_%m_%d
[root@node1 apache_logs]# date --date='2 days ago' +%Y_%m_%d
3.1.2 写一个shell脚本,叫做upload_to_hdfs.sh,内容大体如下
yesterday=`date --date='1 days ago' +%Y_%m_%d`
hadoop fs -put /opt/modules/hive-1.2.1/data/apache_logs/access_${yesterday}.log /tbbs_logs

3.1.3 把脚本upload_to_hdfs.sh配置到crontab中,执行命令crontab -e, 写法如下
[root@node1 data]# crontab -e
![]()
* 1 * * * upload_to_hdfs.sh

3.2、使用MapReduce对数据进行清洗,把原始处理清洗后,放到hdfs的/hmbbs_cleaned目录下,每天产生一个子目录。
3.3、使用hive对清洗后的数据进行统计
3.3.1、建立一个外部分区表,脚本如下
hive> CREATE EXTERNAL TABLE tbbs(ip string, atime string, url string)
> PARTITIONED BY (logdate string)
> ROW FORMAT DELIMITED
> FIELDS TERMINATED BY '\t'
> LOCATION 'hdfs://node1:8020/tbbs_cleaned/';
3.3.2、增加分区,脚本如下
hive> ALTER TABLE tbbs
> ADD PARTITION(logdate='2016_03_25')
> LOCATION '/tbbs_cleaned/2016_03_25';

3.3.3、加载数据到表中(即建立外部表与在HDFS上存放的数据地址的链接)
hive> LOAD DATA INPATH 'hdfs://node1:8020/tbbs_cleaned/tbbs.dat' INTO TABLE tbbs partition(logdate='2016_03_25');
![]()
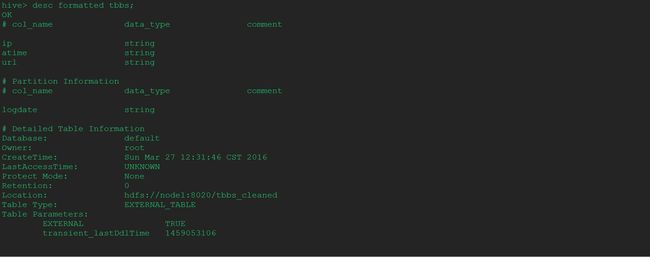
3.3.4、查看表结构
hive> desc formatted tbbs;
![]()
把代码增加到upload_to_hdfs.sh中,内容如下
hive -e "ALTER TABLE tbbs ADD PARTITION(logdate='${yesterday}') LOCATION '/tbbs_cleaned/${yesterday}';"
![]()
3.3.5、统计每日的pv,代码如下
hive> CREATE TABLE tbbs_pv_2016_03_25 AS SELECT COUNT(1) AS PV FROM tbbs WHERE logdate='2016_03_25';
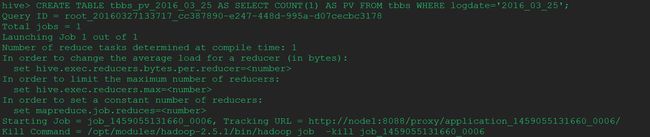
hive> select * from tbbs_pv_2016_03_25;

3.3.6、统计每日的注册用户数,代码如下
CREATE TABLE tbbs_reguser_2016_03_25 AS SELECT COUNT(1) AS REGUSER FROM tbbs WHERE logdate='2016_03_25'
AND INSTR(url,'member.php?mod=register')>0;
hive> select * from tbbs_reguser_2016_03_25;
![]()
3.3.7、统计每日的独立ip,代码如下
CREATE TABLE tbbs_ip_2016_03_25 AS SELECT COUNT(DISTINCT ip) AS IP FROM tbbs WHERE logdate='2016_03_25';

hive> select * from tbbs_ip_2016_03_25;

3.3.8、统计每日的跳出用户,代码如下
hive> CREATE TABLE tbbs_jumper_2016_03_25 AS SELECT COUNT(1) AS jumper FROM (SELECT COUNT(ip) AS times FROM tbbs WHERE logdate='2016_03_25' GROUP BY ip HAVING times=1) e;

hive> select * from tbbs_jumper_2016_03_25;

3.3.9、把每天统计的数据放入一张表
hive> CREATE TABLE tbbs_2016_03_25 AS SELECT '2016_03_25', a.pv, b.reguser, c.ip, d.jumper FROM tbbs_pv_2016_03_25 a JOIN tbbs_reguser_2016_03_25 b ON 1=1 JOIN tbbs_ip_2016_03_25 c ON 1=1 JOIN tbbs_jumper_2016_03_25 d ON 1=1;
hive> select * from tbbs_2016_03_25;