Spark学习
Spark运行原理自我理解:

(1) 首先程序有RDD Objects分解为DAG有向无环图
(2) 提交DAGScheduler,根据shuffer将DAG分解为一组taskset,即stages
(3) Taskset提交TaskScheduler,每个taskset在分解为多个task,即一个task就是一个split分区
(4) Task就运行在worker上
Spark运行原理
(1)用户创建SparkContext对象,新创建的SparkContext会根据用户在编程的时候指定的参数或者系统默认的配置连接到ClusterManager。
(2)Cluster Manager会根据用户提交时的设值,(程序占用CPU的个数,内存的信息等等)来为我们具体的本次的程序分配计算资源,启动具体的Executor。Driver会根据用户程序来进行这种调度级别的一种Stage划分,但这边谈的stage的划分是高层调度器,Saprk在具体执行时分为高层调度和底层调度。高层调度是基于RDD的依赖。RDD的产生一般由前面RDD的具体某个操作中产生,第一次也可以从文件系统中读取一个内容就自动产生,也就是SparkContxt中产生,而后面总是依赖于前面的RDD产生,构成了继承和依赖关系。如果说遇见宽依赖的时候,就划分成不同的Stage,每一个Stage会有一组完全相同的任务组成,这些任务分别作用待处理数据的不同分区。
(3)在Stage划分完成和Task具体创建之后,Driver端会向具体的Executor发送具体的任务,Executor收到任务就会下载Task运行时依赖的库,包,准备好Task的
执行环境之后开始执行Task,执行时就是线程池中的线程执行的。
(4)在执行Task的过程中,会把执行状态汇报给Driver。Driver会根据收到的Task运行状态来处理不同的状态更新。Task本身根据我们之前不同的Stage划分,会把Task分为两种类型,一种是ShuffleMapTask,这个是对数据进行Shuffle,Shuffle的结果会保存在Executor所在节点的本地文件系统中;另外一种是ResultTask,就是最后一个Stage,负责生成结果数据。Driver会不断地调用Task,将Task发送到Executor中执行,所有的Task都正确执行,或者超过执行次数的限制没有成功是会停止。正确执行了就会进入下一个Stage。高层调度器DAGScheduler会帮助我们进行一定次数的重试,如果我们重试一定次数还没成功,那整个作业失败。
===================================================================================================================================
spark是一个分布式,基于内存的适合迭代计算的大数据计算框架。
基于内存,在一些情况下也会基于磁盘,spark计算时会优先考虑把数据放到内存中,应为数据在内存中就具有更好的数据本地性;如果内存放不下时,也会将少量数据放到磁盘上,它的计算既可以基于内存也可以基于磁盘,它适于任何规模的数据的计算。
Spark想用一个技术堆栈解决所有的大数据计算问题。大数据计算问题主要包括:交互式查询(基于shell和sql)、流处理(数据流入后直接进行处理)和批处理(基于Spark内核进行的一个RDD级别的编程,同时还包含图计算、机器学习的内容)。目前Spark支持的5中计算范式:流处理、SQL、R、图计算、机器学期等。
我们可以从三个方面去理解Spark,
1. 分布式
在生产环境下,是在分布式多台机器下去运行的。它会有几个特征:(1)我们的Spark会有一个Driver端,也就是所谓的客户端,我们自己编写的程序,要提交给集群;而在集群中有很多机器,
整作业的运行实际上是运行在分布式的节点(默认一台机器是一个节点)中的。
 Spark程序提交到Spark集群上进行运行,运行时要处理一批数据,由于它是分布式的,所以运行时不同的节点会处理一部分数据。各个部分节点处理数据互不干扰。所以,在做分布式时,就可以并行化。所以他就可以处理数据更快。
Spark程序提交到Spark集群上进行运行,运行时要处理一批数据,由于它是分布式的,所以运行时不同的节点会处理一部分数据。各个部分节点处理数据互不干扰。所以,在做分布式时,就可以并行化。所以他就可以处理数据更快。
1. (主要)基于内存
Spark优先考虑使用内存,其实是是对计算机资源最大化利用的一个物理基石。在内存中可以放下时,最先考虑到内存中,放不下时放在磁盘上。
2. 擅长迭代式计算
擅长迭代式计算是Spark的真正精髓。在实际如果要对数据进行稍有价值的挖掘或是对数据进行稍有复杂度的一些挖掘,一定是要对数据进行具有多步奏的计算。这时候就要用到迭代式的计算,而Spark天生就是适用于分布式的主要基于内存的迭代式计算。Spark基于磁盘的迭代式计算会比hadoop快10x倍,而Spark基于内存的迭代式计算要比hadoop快100x倍。这里要提一下,当作业计算完第一个阶段,然后移动另一个节点中进行计算,也就是所谓为的shuffle,而且可以反复的shuffle,并形成一个链条,这就是迭代。
我们写好的本地程序,提交到Driver上,他会提供一个接口即SparkContext,然后Driver会将我们的程序提交到集群上,各个work会并行计算处理我们的程序。Hadoop和Spark最根本的不同是迭代模型的不同,hadoop主要是两步map阶段和reduce阶段,进行完计算之后,就没有以后的阶段了,而Spark可以在计算完第一个阶段后,进行第二阶段计算,第二阶段计算完后进行第三阶段…也就是说,我们进行完一个阶段后,后面可以有很多阶段的计算来完成任务,而不是hadoop只有map和reduce两个阶段这么僵硬。由于它的这种迭代式模型使得Spark更加强大和灵活。构造复杂算法时也更加容易。
在读取文件时,hadoop每次都是都是读取磁盘和写入磁盘,而Spark是基于内存的,大部分中间计算结果是保存在内存中,下一次计算是基于内存的计算结果的,所以节省了读取磁盘的时间。
Spark的高速运行除了基于内存,主要原因还是因为他的调度器(基于DAG之上的调度器,有高层调度器和底层调度器和容错)。
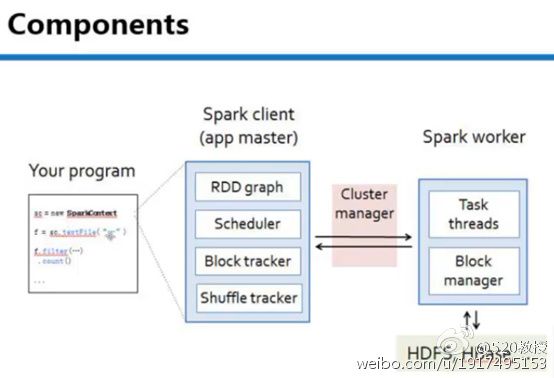 我们在本地开发好Spark文件,具体在单独的机器上提交程序,如上图圆圈中的都是Driver级别的,这些都是驱动整个程序运行的,Spark程序是会提交到集群中去运行的,他具体运行时是要靠Driver驱动来运行的。而具体节点(如Spark worker)是一各个计算的节点work,而在计算时,要读取具体的数据,读取数据可以从HDFS,HBase,Hive或是传统的DB来源读取数据,处理数据时主要是利用线程池、线程复用的方式,处理完成后,数据可以放在HDFS,HBase,Hive,DB,还可以直接返回直接给客户端,也就是正在运行程序的机器上的进程。
我们在本地开发好Spark文件,具体在单独的机器上提交程序,如上图圆圈中的都是Driver级别的,这些都是驱动整个程序运行的,Spark程序是会提交到集群中去运行的,他具体运行时是要靠Driver驱动来运行的。而具体节点(如Spark worker)是一各个计算的节点work,而在计算时,要读取具体的数据,读取数据可以从HDFS,HBase,Hive或是传统的DB来源读取数据,处理数据时主要是利用线程池、线程复用的方式,处理完成后,数据可以放在HDFS,HBase,Hive,DB,还可以直接返回直接给客户端,也就是正在运行程序的机器上的进程。
RDD
RDD:弹性分布式数据起,本生是对分布式计算一个抽象。首先它是一个数据集(DataSet),它会代表我们要处理的数据,但是它是分布式的,也就是分成很多分片,分布在几百台或上千台机器上的。在每个节点上存储时默认这些数据都是放在内存中的。RDD代表了一些列的分片,而这些分片是在具体的不同节点上存储,默认优先在内存中存储,如果内存放不下,他会把一部分放在磁盘上进行存储,而这些对于我们用户来说是透明的。我们只需要针对RDD进行计算和处理就行了。RDD本生会自动进行内存和磁盘的权衡和切换,这就是弹性之一,其次,它基于Lineage的高效容错(他会更具血统继承关系来恢复运行出错情况,可以从上一个步奏进行重新计算,而不会从第一个步奏重新计算,效率非常高,以为不需要重头开始重新计算),第三,task如果失败,会自动进行特定次数的重试(默认4次),第四,Stage如果失败会自动进行特定次数的重试(默认3次,只计算失败的分片)。
下面我们讲下缓存的时机:
(1)计算特别耗时
(2)计算链条已经很长了
(3)Shuffle之后(冲其他地方抓数据后)
(4)ChechPoint之前(chechPoint是当前作业执行后,再触发一个作业)
RDD 本生会有一些列的数据分片,一个 RDD 在逻辑上就代表了顶层的一个文件或文件夹,但实际上它是按照分区( partition )分为多个分区,分区会放在 Spark 集群中不同的机器的节点上。而 RDD 本生又包含了对函数的计算。