编译.java文件时的编码问题
最新版本,见《编译.java文件时的编码问题》更新版本
如《编码解码模型和实现》所述
在编译.java文件生成.class文件的时候,首先要解码.java文件存储的字节流,这需要我们正确指定编码字符流生成该字节流过程中使用的编码方案,否则会出现意想不到的错误。一、现在有如下Java代码片段:
public class Main {
public static void main(String[] args) {
String hello = "好";
System.out.println(hello);
}
}
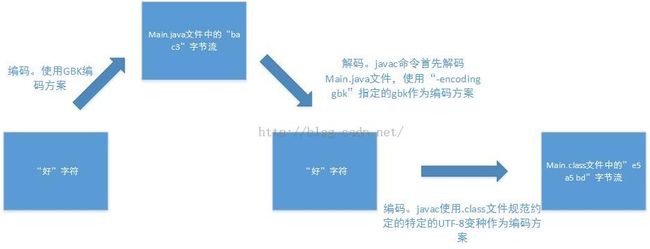
保存以上代码所在的Main.java文件,编码字符流生成字节流的时候采用GBK编码方案
现在要正确编译Main.java文件,需要执行以下命令:
"javac -encoding gbk Main.java"
能够生成正确的Main.class文件
以“好”这个字符为线索,从写入Main.java文件,到编译生成Main.class文件中的相应字节流的整个过程如下图所示:
如果执行以下命令
"javac -encoding utf8 Main.java"
会有警告产生,并且会生成错误的Main.class文件
以“好”这个字符为线索,从写入Main.java文件,到编译生成Main.class文件中的相应字节流的整个过程如下图所示:
二、现在有如下Java代码片段:
public class Main {
public static void main(String[] args) {
String hello = "好";
System.out.println(hello);
}
}
保存以上代码所在的Main.java文件,编码字符流生成字节流的时候采用UTF-8编码方案
现在要正确编译Main.java文件,需要执行以下命令:
"javac -encoding utf8 Main.java"
能够生成正确的Main.class文件
以“好”这个字符为线索,从写入Main.java文件,到编译生成Main.class文件中的相应字节流的整个过程如下图所示:
如果执行以下命令
"javac -encoding gbk Main.java"
编译就直接会报错,错误提示是“未结束的字符串字面值”
备注:
从以上可见,在碰到不能解码的字节序列时:这里的UTF-8字符编码方案实现使用特定的字符'�'作为解码值,而这里的GBK字符编码方案实现直接报错。