引言 Context Manager对应的进程为servicemanager,它先于Service Server与服务客户端运行,首先进入接收IPC数据的状态,处理来自Service Server或服务客户端的请求。在init.rc脚本文件中也可以看到Context Manager在mediaserver与system_server之前运行了。
每当Service Server注册服务时,Context Manager都会把服务的名称与Binder节点编号注册到自身的服务目录中,该服务目录通过根文件系统下的/system/service程序即可查看。 下图即为在华为某型号手机上使用service list命令查看到的服务列表:
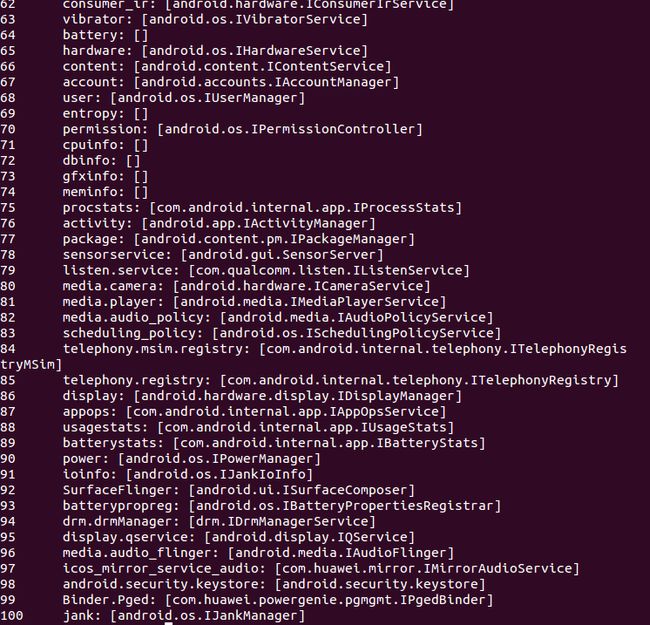
可以看到MediaPlayer Service以及Camera Service等。
1.启动运行Context Manager的main()函数
Context Manager与其他Android服务不同,它采用C语言编写,以便使其与Binder Driver紧密衔接。Context Manager的源码在/frameworks/base/cmds/servicemanager目录下的service_manager.c中。main()函数如下所示:
service_manager.c
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
int main(int argc, char**argv) { struct binder_state *bs; void *svcmgr=BINDER_SERVICE_MANAGER; bs=binder_open(128*1024); if(binder_become_context_manager(bs)){ LOGE("cannot become context manager (%s)\n",strerror(errno)); return -1; } svcmgr_handle=svcmgr; binder_loop(bs,svcmgr_handler); return 0; }
|
上面的代码按功能可以分为以下3部分:
-
调用binder_open()函数,将引起open()与mmap()函数调用,调用open()函数打开Binder Driver,而调用mmap()函数则生成接收IPC数据的Buffer. Context Manager使用大小为128KB的Buffer来接收IPC数据;
-
与Service Server和服务客户端不同,这是Context Manager特有的语句,用于访问Binder Driver,并将自身的Binder节点设置为0号节点。在binder_become_context_manager()中,仅有一条调用ioctl()函数的语句,如下所示:
binder_become_context_manager()
1
2
3
4
|
int binder_become_context_manager(struct binder_state*bs) { return ioctl(bs->fd,BINDER_SET_CONTEXT_MGR,0); }
|
- Context Manager将自身的Binder节点设置好后,就进入循环,不断等待接收IPC数据,那就是binder_loop()的作用。
下面将详细讲解这3个部分。
2.binder_open()函数分析
2.1 驱动函数注册
在分析binder_open()方法之前,我们先了解一下驱动函数是如何被调用的,我们先看一下下面的代码:
binder.c
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
static const struct file_operations binder_fops={ .owner=THIS_MODULE, .poll=binder_poll, .unlocked_ioctl=binder_ioctl, .mmap=binder_mmap, .open=binder_open, .flush=binder_flush, .release=binder_release, }; static struct miscdevice binder_miscdev={ .minor=MISC_DYNAMIC_MINOR, .name="binder", .fops=&binder_fops, } static int __init binder_init(void) { ... ret=misc_register(&binder_miscdev); ... } device_initcall(binder_init);
|
上面的代码在drivers/staging/android/binder.c中。我们知道,Android是基于Linux 2.6内核开发的,所以驱动的注册和Linux中也一样。
-
device_initcall(binder_init)的作用是将binder_init()函数注册到kernel的初始化函数列表中。当kernel启动后,会按照一定的次序调用初始化函数列表,也就会执行binder_init()函数,执行binder_init()时便会加载Binder驱动;
-
binder_init()函数中会通过misc_register(&binder_miscdev)将Binder驱动注册到文件节点/dev/binder上。在Linux中,一切都是文件。将Binder驱动注册到文件节点上之后,就可以通过操作文件节点进而对Binder驱动进行操作。而该文件节点/dev/binder的设备信息是binder_miscdev这个结构体对象。
-
binder_miscdev变量是struct miscdevice类型。minor是次设备号,这个我们不关心;name是Binder驱动对应在/dev虚拟文件系统下的设备节点名称,也就是/dev/binder中的"binder";fops是该设备节点的文件操作对象,它是我们需要重点关注的.
-
binder_fops变量是struct file_operations类型。其中owner标明了该文件操作变量的拥有者,就是该驱动;poll则指定了poll函数指针,当我们对/dev/binder文件节点执行poll操作时,实际上调用的就是binder_poll()函数;同理,mmap()对应binder_mmap(),open()对应binder_open(),ioctl()对应binder_ioctl
2.2 binder_open()
binder_open()方法的主要代码如下:
binder_open()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
struct binder_state *binder_open(unsigned mapsize) { struct binder_state *bs; bs = malloc(sizeof(*bs)); ... bs->fd = open("/dev/binder", O_RDWR); ... bs->mapsize = mapsize; bs->mapped = mmap(NULL, mapsize, PROT_READ, MAP_PRIVATE, bs->fd, 0); ... return bs; }
|
该代码在/frameworks/base/cmds/servicemanager/binder.c中.
2.2.1 驱动中的binder_oepn()
通过2.1的分析,我们知道open(“/dev/binder”,O_RDWR);其实就是调用Binder驱动中的binder_open(),其代码如下:
binder_open()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
static int binder_open(struct inode *nodp, struct file *filp) { struct binder_proc *proc; binder_debug(BINDER_DEBUG_OPEN_CLOSE, "binder_open: %d:%d\n", current->group_leader->pid, current->pid); //为proc分配内存 proc = kzalloc(sizeof(*proc), GFP_KERNEL); if (proc == NULL) return -ENOMEM; get_task_struct(current); //将proc->tsk指向当前线程 proc->tsk = current; //初始化proc的待处理事务列表 INIT_LIST_HEAD(&proc->todo); //初始化proc的待处理事务列表 init_waitqueue_head(&proc->wait); //设置proc的进程优先级设置为当前线程的优先级 proc->default_priority = task_nice(current); mutex_lock(&binder_lock); binder_stats_created(BINDER_STAT_PROC); //将该进程上下文信息proc保存到binder_procs中 hlist_add_head(&proc->proc_node, &binder_procs); //设置进程id proc->pid = current->group_leader->pid; INIT_LIST_HEAD(&proc->delivered_death); //将proc设置为flip的私有数据中,从而 使mmap(),ioctl()等函数都可以通过私有数据获取到proc,即该进程的context信息 filp->private_data = proc; mutex_unlock(&binder_lock); if (binder_debugfs_dir_entry_proc) { char strbuf[11]; snprintf(strbuf, sizeof(strbuf), "%u", proc->pid); proc->debugfs_entry = debugfs_create_file(strbuf, S_IRUGO, binder_debugfs_dir_entry_proc, proc, &binder_proc_fops); } return 0; }
|
tips: 结构体binder_proc用于记录进程上下文信息。它的详细介绍可参考博客Android Binder机制中的数据结构分析.
结合注释,很容易发现该函数的主要伤脑筋其实就是新建了一个binder_proc指针,并为其分配内存,再设置其属性(如tsk,todo,default_priority等),最后将其赋值给flip的private_data属性,这样以后就可以通过flip->private_data访问到进程上下方信息了。
2.2.2 mmap()分析
mmap()函数对应Binder驱动中的binder_mmap()函数,其主要代码如下:
binder_mmap()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
|
static int binder_mmap(struct file *filp, struct vm_area_struct *vma) { int ret; struct vm_struct *area; struct binder_proc *proc = filp->private_data; const char *failure_string; struct binder_buffer *buffer; //有效性检查,确保映射的内存不能大于4M if ((vma->vm_end - vma->vm_start) > SZ_4M) vma->vm_end = vma->vm_start + SZ_4M; ... vma->vm_flags = (vma->vm_flags | VM_DONTCOPY) & ~VM_MAYWRITE; if (proc->buffer) { ret = -EBUSY; failure_string = "already mapped"; goto err_already_mapped; } //获取空闲的内核空间地址 area = get_vm_area(vma->vm_end - vma->vm_start, VM_IOREMAP); ... //将内核地址空间地址赋值给proc->buffer,即保存到进程上下文中 proc->buffer = area->addr; //计算进程虚拟地址(vma->vm_start)和内核空间地址(proc->buffer)的偏移值 proc->user_buffer_offset = vma->vm_start - (uintptr_t)proc->buffer; ... //为proc->pages分配内存 proc->pages = kzalloc(sizeof(proc->pages[0]) * ((vma->vm_end - vma->vm_start) / PAGE_SIZE), GFP_KERNEL); ... //内核空间的内存大小=进程虚拟地址区域(用户空间)的内存大小 proc->buffer_size = vma->vm_end - vma->vm_start; vma->vm_ops = &binder_vm_ops; //将proc赋值给vma私有数值 vma->vm_private_data = proc; //通过调用binder_update_page_range()来分配物理页面。即物理内存映射到内核空间和用户空间 if (binder_update_page_range(proc, 1, proc->buffer, proc->buffer + PAGE_SIZE, vma)) { ret = -ENOMEM; failure_string = "alloc small buf"; goto err_alloc_small_buf_failed; } buffer = proc->buffer; INIT_LIST_HEAD(&proc->buffers); //将物理内存添加到proc->buffers链表中进行管理 list_add(&buffer->entry, &proc->buffers); buffer->free = 1; binder_insert_free_buffer(proc, buffer); proc->free_async_space = proc->buffer_size / 2; barrier(); proc->files = get_files_struct(current); //将用户空间地址信息保存到proc中 proc->vma = vma; return 0; ... }
|
-
函数首先通过flip->private_data得到在打开设备文件/dev/binder时创建的struct binder_proc结构体
-
内存映射信息放在vma中。读者可能注意到了vma类型是struct vm_area_struct,它表示一块连续的虚拟地址空间区域。而函数中的area类型是struct vm_struct,它表示的也是一块连续的虚拟地址空间。那么它们的区别是什么呢?
在Linux中,struct vm_aream_struct表示的虚拟地址是给进程使用的,而struct vm_struct表示的虚拟地址是给内核使用的,它们对应的物理页面都可以是不连续的。
2.2.3 binder_update_page_range()
其源码如下:
binder_update_page_range()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
static int binder_update_page_range(struct binder_proc *proc, int allocate, void *start, void *end, struct vm_area_struct *vma) { void *page_addr; unsigned long user_page_addr; struct vm_struct tmp_area; struct page **page; struct mm_struct *mm; ... for (page_addr = start; page_addr < end; page_addr += PAGE_SIZE) { int ret; struct page **page_array_ptr; page = &proc->pages[(page_addr - proc->buffer) / PAGE_SIZE]; BUG_ON(*page); *page = alloc_page(GFP_KERNEL | __GFP_ZERO); ... tmp_area.addr = page_addr; tmp_area.size = PAGE_SIZE + PAGE_SIZE /* guard page? */; page_array_ptr = page; ret = map_vm_area(&tmp_area, PAGE_KERNEL, &page_array_ptr); ... user_page_addr = (uintptr_t)page_addr + proc->user_buffer_offset; ret = vm_insert_page(vma, user_page_addr, page[0]); ... } ... return 0; ... }
|
tips: binder_update_range()既可用于分配物理页面,也可用于释放物理页面,这取决于allocate的值。这里先只讨论分配物理页面的情形。
-
page用于指向物理页面,tmp_area用于描述内核空间,user_page_addr则代表相应的进程虚拟空间地址,由于在binder_mmap()函数中已经计算出了内核虚拟空间地址和进程虚拟空间地址的偏差值,所以这里只要用页面地址加上相应的偏差值即可;
-
在for循环中,每分配一个物理页面都会先通过map_vm_are()将该物理页面映射到内核虚拟地址中,然后再将该物理页面插入到进程虚拟地址空间。
至此,binder_open()函数就分析完了,总结起来它的作用就是打开/dev/binder,然后使进程虚拟空间和内核虚拟空间映射到同一块物理内存中,同时新建并初始化了binder_proc对象,保存了进程上下文信息。
3.binder_become_context_manager()
这个方法的代码非常简单:
binder_become_context_manager()
1
2
3
4
|
int binder_become_context_manager(struct binder_state*bs) { return ioctl(bs->fd,BINDER_SET_CONTEXT_MGR,0); }
|
前面说过,ioctl()对应Binder Driver中的binder_ioctl()方法,下面是其主要代码:
binder_ioctl()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
|
static long binder_ioctl(struct file *filp, unsigned int cmd, unsigned long arg) { int ret; struct binder_proc *proc = filp->private_data; struct binder_thread *thread; unsigned int size = _IOC_SIZE(cmd); void __user *ubuf = (void __user *)arg; ret = wait_event_interruptible(binder_user_error_wait, binder_stop_on_user_error < 2); if (ret) return ret; mutex_lock(&binder_lock); thread = binder_get_thread(proc); ... switch (cmd) { ... //由于我们只里只涉及到BINDER_SET_CONTEXT_MGR这种情形,所以将其它几种情况的代码省略了。 case BINDER_SET_CONTEXT_MGR: if (binder_context_mgr_node != NULL) { ... } if (binder_context_mgr_uid != -1) { ... } else binder_context_mgr_uid = current->cred->euid; binder_context_mgr_node = binder_new_node(proc, NULL, NULL); if (binder_context_mgr_node == NULL) { ret = -ENOMEM; goto err; } binder_context_mgr_node->local_weak_refs++; binder_context_mgr_node->local_strong_refs++; binder_context_mgr_node->has_strong_ref = 1; binder_context_mgr_node->has_weak_ref = 1; break; ... } ret = 0; err: if (thread) thread->looper &= ~BINDER_LOOPER_STATE_NEED_RETURN; mutex_unlock(&binder_lock); wait_event_interruptible(binder_user_error_wait, binder_stop_on_user_error < 2); ... return ret; }
|
tip:为了更好地分析代码逻辑,将debug输出,异常处理以及其他几种case情况的代码省略了。
在分析这个函数之前,先看下下struct binder_thread和struct binder_node这两个结构体类型。
3.1 struct binder_thread分析
struct binder_thread
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
struct binder_thread{ struct binder_proc*proc; struct rb_node rb_node; int pid; int looper; struct binder_transaction*transaction_stack; struct list_head todo; /*Write failed,return error code in read buf*/ uint32_t return_error; /*Write failed,return error code in read buffer.Used when sending a reply to a dead process that we are also waiting on*/ uint32_t return_error2; wait_queue_head_t wait; struct binder_stats stats; }
|
1
2
3
4
5
6
7
8
|
enum{ BINDER_LOOPER_STATE_REGISTERED=0x01; BINDER_LOOPER_STATE_ENTERED=0x02; BINDER_LOOPER_STATE_EXITED=0x04; BINDER_LOOPER_STATE_INVALID=0x08; BINDER_LOOPER_STATE_WAITING=0x10; BINDER_LOOPER_STATE_NEED_RETURN=0x20 }
|
3.2 struct binder_node分析
struct binder_node代表一个binder实体,所有Service Server都会有一个对应的binder_node. 其定义如下:
struct binder_node
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
struct binder_node { int debug_id; struct binder_work work; union { struct rb_node rb_node; struct hlist_node dead_node; }; struct binder_proc *proc; struct hlist_head refs; int internal_strong_refs; int local_weak_refs; int local_strong_refs; void __user *ptr; void __user *cookie; unsigned has_strong_ref:1; unsigned pending_strong_ref:1; unsigned has_weak_ref:1; unsigned pending_weak_ref:1; unsigned has_async_transaction:1; unsigned accept_fds:1; unsigned min_priority:8; struct list_head async_todo; };
|
-
rb_node和dead_node组成一个联合体,如果这个Binder实体还在正常使用,则使用rb_node来连入proc->nodes所表示的红黑树的节点,这棵红黑树用来组织属于这个进程的所有Binder实体;如果这个Binder实体所属的进程已经被销毁,而这个Binder实体又被其他进程所使用,则它通过dead_node进入到一个哈希表中去存放。
-
proc当然是指这个Binder实体所属的进程了
-
refs成员变量则是所有引用了该Binder实体的Binder引用构成的链表
-
internal_strong_refs,local_weak_refs,local_strong_refs表示这个Binder实体的引用计数
-
ptr和cookie分别表示这个Binder实体在用户空间的地址和附加数据
剩下的成员变量比较简单,等用到的时候再进行说明。
3.3 binder_ioctl()逻辑分析
3.3.1 binder_get_thread()方法
回到binder_ioctl()函数中,首先是通过flip->private_data获得proc变量,然后通过调用binder_get_thread()函数获得线程信息,该方法的代码如下:
binder_get_thread()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
static struct binder_thread *binder_get_thread(struct binder_proc *proc) { struct binder_thread *thread = NULL; struct rb_node *parent = NULL; struct rb_node **p = &proc->threads.rb_node; while (*p) { parent = *p; thread = rb_entry(parent, struct binder_thread, rb_node); if (current->pid < thread->pid) p = &(*p)->rb_left; else if (current->pid > thread->pid) p = &(*p)->rb_right; else break; } if (*p == NULL) { thread = kzalloc(sizeof(*thread), GFP_KERNEL); if (thread == NULL) return NULL; binder_stats_created(BINDER_STAT_THREAD); thread->proc = proc; thread->pid = current->pid; init_waitqueue_head(&thread->wait); INIT_LIST_HEAD(&thread->todo); rb_link_node(&thread->rb_node, parent, p); rb_insert_color(&thread->rb_node, &proc->threads); thread->looper |= BINDER_LOOPER_STATE_NEED_RETURN; thread->return_error = BR_OK; thread->return_error2 = BR_OK; } return thread; }
|
代码很好理解,由于当前线程是第一次进入这里,所以*p==NULL成立,从而为当前线程创建一个线程上下文信息结构binder_thread,并初始化各成员变量,并插入到proc->threads所代表的红黑树中。另外,注意这里的thread->looper=BINDER_LOOPER_STATE_NEED_RETURN.
3.3.2 binder_new_node()方法
回到binder_ioctl()函数,继续往下看可以看到两个全局变量,它们的定义如下:
1
2
|
static struct binder_node *binder_context_mgr_node; static uid_t binder_context_mgr_uid=-1;
|
其中binder_context_mgr_node代表Context Manager实体,binder_context_mgr_uid代表Context Manager守护进程的uid.由于是首次进入binder_ioctl(),所以将binder_context_mgr_uid赋值为current->cred->euid,这样,当前线程就成为Binder机制的守护进程了;然后调用binder_new_node()函数为Context Manager创建新的Binder实体,该方法的代码如下:
binder_new_node()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
static struct binder_node *binder_new_node(struct binder_proc *proc, void __user *ptr, void __user *cookie) { struct rb_node **p = &proc->nodes.rb_node; struct rb_node *parent = NULL; struct binder_node *node; //根据ptr在红黑树中查找是否已经存在相应的binder节点,如果已经存在则返回NULL,否则最终跳出循环并新建节点 while (*p) { parent = *p; node = rb_entry(parent, struct binder_node, rb_node); if (ptr < node->ptr) p = &(*p)->rb_left; else if (ptr > node->ptr) p = &(*p)->rb_right; else return NULL; } node = kzalloc(sizeof(*node), GFP_KERNEL); if (node == NULL) return NULL; binder_stats_created(BINDER_STAT_NODE); rb_link_node(&node->rb_node, parent, p); rb_insert_color(&node->rb_node, &proc->nodes); node->debug_id = ++binder_last_id; node->proc = proc; node->ptr = ptr; node->cookie = cookie; node->work.type = BINDER_WORK_NODE; INIT_LIST_HEAD(&node->work.entry); INIT_LIST_HEAD(&node->async_todo); ... return node; }
|
至此,binder_become_context_manager()方法就基本分析完了,总结起来,它主要是完成了以下几件事:
1)告诉kernel驱动,当前进程即Binder上下文管理者
2)新建binder_thread对象并将其插入到binder_proc的threads红黑树中;
3)新建对应于Context Manager的binder_node;
- binder_loop()分析
下面分析servicer_manager.c中的main()函数中的第三部分:binder_loop(),该方法的代码如下:
binder_loop()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
void binder_loop(struct binder_state *bs, binder_handler func) { int res; struct binder_write_read bwr; unsigned readbuf[32]; bwr.write_size = 0; bwr.write_consumed = 0; bwr.write_buffer = 0; readbuf[0] = BC_ENTER_LOOPER; binder_write(bs, readbuf, sizeof(unsigned)); for (;;) { bwr.read_size = sizeof(readbuf); bwr.read_consumed = 0; bwr.read_buffer = (unsigned) readbuf; res = ioctl(bs->fd, BINDER_WRITE_READ, &bwr); if (res < 0) { LOGE("binder_loop: ioctl failed (%s)\n", strerror(errno)); break; } res = binder_parse(bs, 0, readbuf, bwr.read_consumed, func); if (res == 0) { LOGE("binder_loop: unexpected reply?!\n"); break; } if (res < 0) { LOGE("binder_loop: io error %d %s\n", res, strerror(errno)); break; } } }
|
4.1 binder_write()分析
首先通过binder_write()函数执行BC_ENTER_LOOPER命令告诉Binder Driver,Context Manager要进入循环了。binder_write()的代码如下:
binder_write()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
int binder_write(struct binder_state *bs, void *data, unsigned len) { struct binder_write_read bwr; int res; bwr.write_size = len; bwr.write_consumed = 0; bwr.write_buffer = (unsigned) data; bwr.read_size = 0; bwr.read_consumed = 0; bwr.read_buffer = 0; res = ioctl(bs->fd, BINDER_WRITE_READ, &bwr); if (res < 0) { fprintf(stderr,"binder_write: ioctl failed (%s)\n", strerror(errno)); } return res; }
|
其中结构体binder_write_read的定义如下:
struct binder_write_read
1
2
3
4
5
6
7
8
9
10
11
|
struct binder_write_read{ //bytes to write signed long write_size; //bytes consumed by driver unsigned long write_buffer; //bytes to read signed long read_size; //bytes consumed by driver signed long read_consumed; unsigned long read_buffer; }
|
4.1.1 binder_ioctl()分析
再回到binder_write()中,代码很简单,就是新建一个binder_write_read变量并且初始化,重点在于ioctl,由于此处传入的命令参数是BINDER_WRITE_READ,所以此时对应的binder_ioctl()主要代码如下:
binder_ioctl()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
|
static long binder_ioctl(struct file *filp, unsigned int cmd, unsigned long arg) { int ret; struct binder_proc *proc = filp->private_data; struct binder_thread *thread; unsigned int size = _IOC_SIZE(cmd); void __user *ubuf = (void __user *)arg; ret = wait_event_interruptible(binder_user_error_wait, binder_stop_on_user_error < 2); if (ret) return ret; mutex_lock(&binder_lock); thread = binder_get_thread(proc); ... switch (cmd) { case BINDER_WRITE_READ: { struct binder_write_read bwr; if (size != sizeof(struct binder_write_read)) { ret = -EINVAL; goto err; } if (copy_from_user(&bwr, ubuf, sizeof(bwr))) { ret = -EFAULT; goto err; } ... if (bwr.write_size > 0) { ret = binder_thread_write(proc, thread, (void __user *)bwr.write_buffer, bwr.write_size, &bwr.write_consumed); if (ret < 0) { bwr.read_consumed = 0; if (copy_to_user(ubuf, &bwr, sizeof(bwr))) ret = -EFAULT; goto err; } } if (bwr.read_size > 0) { ret = binder_thread_read(proc, thread, (void __user *)bwr.read_buffer, bwr.read_size, &bwr.read_consumed, filp->f_flags & O_NONBLOCK); if (!list_empty(&proc->todo)) wake_up_interruptible(&proc->wait); if (ret < 0) { if (copy_to_user(ubuf, &bwr, sizeof(bwr))) ret = -EFAULT; goto err; } } ... if (copy_to_user(ubuf, &bwr, sizeof(bwr))) { ret = -EFAULT; goto err; } break; } ... } ret = 0; err: if (thread) thread->looper &= ~BINDER_LOOPER_STATE_NEED_RETURN; mutex_unlock(&binder_lock); wait_event_interruptible(binder_user_error_wait, binder_stop_on_user_error < 2); ... return ret; }
|
1)switch前面的代码在之前已经解释过了,同前面是一样的,只不过这里调用binder_get_thread函数能够获取到之前创建的binder_thread,所以不需要再创建一个新的了
2)通过copy_from_user(&bwr,ubuf,sizeof(bwr))将用户传递过来的参数会的成struct binder_write_read结构体变量并保存在bwr中
3)由于bwr.write_size为4,故进入binder_thread_write()函数中,其主要代码如下:
binder_thread_write()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
int binder_thread_write(struct binder_proc *proc, struct binder_thread *thread, void __user *buffer, int size, signed long *consumed) { uint32_t cmd; void __user *ptr = buffer + *consumed; void __user *end = buffer + size; while (ptr < end && thread->return_error == BR_OK) { if (get_user(cmd, (uint32_t __user *)ptr)) return -EFAULT; ptr += sizeof(uint32_t); if (_IOC_NR(cmd) < ARRAY_SIZE(binder_stats.bc)) { binder_stats.bc[_IOC_NR(cmd)]++; proc->stats.bc[_IOC_NR(cmd)]++; thread->stats.bc[_IOC_NR(cmd)]++; } switch (cmd) { ... case BC_ENTER_LOOPER: ... if (thread->looper & BINDER_LOOPER_STATE_REGISTERED) { thread->looper |= BINDER_LOOPER_STATE_INVALID; binder_user_error("binder: %d:%d ERROR:" " BC_ENTER_LOOPER called after " "BC_REGISTER_LOOPER\n", proc->pid, thread->pid); } thread->looper |= BINDER_LOOPER_STATE_ENTERED; break; ... } *consumed = ptr - buffer; } return 0; }
|
吐槽一下:这个方法的完整代码有300多行,其实是十分不优雅的,很不利于阅读。
由于之前在binder_get_thread()函数中创建的binder_thread的looper值为0,所以这里的代码就异常简单了,就是改变thread的looper属性成员的值,使其变为BINDER_LOOPER_STATE_ENTERED;
4)再回到binder_ioctl()函数,由于bwr_read_size==0,所以函数不会再向下执行了。
4.2 binder_loop()中的for循环分析
回到binder_loop()函数,进入for循环,调用ioctl()之前的代码都很简单,就是给bwr的成员赋值。注意经过赋值之后bwr的各成员的值如下:
1
2
3
4
5
6
7
|
bwr.write_size=0; bwr.write_consumed=0; bwr.write_buffer=0; readbuf[0]=BC_ENTER_LOOPER; bwr.read_size=sizeof(readbuf); bwr.read_consumed=0; bwr.read_buffer=(unsigned)readbuf;
|
再次进入binder_ioctl()函数中:
binder_ioctl()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
|
static long binder_ioctl(struct file *filp, unsigned int cmd, unsigned long arg) { int ret; struct binder_proc *proc = filp->private_data; struct binder_thread *thread; unsigned int size = _IOC_SIZE(cmd); void __user *ubuf = (void __user *)arg; ret = wait_event_interruptible(binder_user_error_wait, binder_stop_on_user_error < 2); if (ret) return ret; mutex_lock(&binder_lock); thread = binder_get_thread(proc); ... switch (cmd) { case BINDER_WRITE_READ: { struct binder_write_read bwr; if (size != sizeof(struct binder_write_read)) { ret = -EINVAL; goto err; } if (copy_from_user(&bwr, ubuf, sizeof(bwr))) { ret = -EFAULT; goto err; } ... if (bwr.write_size > 0) { ret = binder_thread_write(proc, thread, (void __user *)bwr.write_buffer, bwr.write_size, &bwr.write_consumed); if (ret < 0) { bwr.read_consumed = 0; if (copy_to_user(ubuf, &bwr, sizeof(bwr))) ret = -EFAULT; goto err; } } if (bwr.read_size > 0) { ret = binder_thread_read(proc, thread, (void __user *)bwr.read_buffer, bwr.read_size, &bwr.read_consumed, filp->f_flags & O_NONBLOCK); if (!list_empty(&proc->todo)) wake_up_interruptible(&proc->wait); if (ret < 0) { if (copy_to_user(ubuf, &bwr, sizeof(bwr))) ret = -EFAULT; goto err; } } ... if (copy_to_user(ubuf, &bwr, sizeof(bwr))) { ret = -EFAULT; goto err; } break; } ... } ret = 0; err: if (thread) thread->looper &= ~BINDER_LOOPER_STATE_NEED_RETURN; mutex_unlock(&binder_lock); wait_event_interruptible(binder_user_error_wait, binder_stop_on_user_error < 2); ... return ret; }
|
跟上一次调用相比,其他的都相同,只是这次bwr.write_size等于0同时bwr.read_size等于32,所以这次不调用binder_thread_write()函数而是进入binder_thread_read()函数(其实就是上次写入了自己的状态,然后就开始读取驱动中的数据了),binder_thread_read()方法如下:
binder_thread_read()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
|
static int binder_thread_read(struct binder_proc *proc, struct binder_thread *thread, void __user *buffer, int size, signed long *consumed, int non_block) { void __user *ptr = buffer + *consumed; void __user *end = buffer + size; int ret = 0; int wait_for_proc_work; //若*consumed==0,则写入BR_NOOP到用户传进来的bwr.read_buffer缓冲区 if (*consumed == 0) { if (put_user(BR_NOOP, (uint32_t __user *)ptr)) return -EFAULT; //修改指针位置 ptr += sizeof(uint32_t); } retry: //等待proc进程的事务标记 //当线程的事务栈为空,待处理事务列表为空时,该标记为true wait_for_proc_work = thread->transaction_stack == NULL && list_empty(&thread->todo); ... //设置线程状态为等待 thread->looper |= BINDER_LOOPER_STATE_WAITING; if (wait_for_proc_work) proc->ready_threads++; mutex_unlock(&binder_lock); if (wait_for_proc_work) { ... //设置当前线程的优先级为进程的默认优先级 binder_set_nice(proc->default_priority); if (non_block) { //非阻塞式的读取,通过binder_has_proc_work()读取proc的事务;若没有则直接返回。 if (!binder_has_proc_work(proc, thread)) ret = -EAGAIN; } else ret = wait_event_interruptible_exclusive(proc->wait, binder_has_proc_work(proc, thread)); } else { if (non_block) { if (!binder_has_thread_work(thread)) ret = -EAGAIN; } else ret = wait_event_interruptible(thread->wait, binder_has_thread_work(thread)); } mutex_lock(&binder_lock); if (wait_for_proc_work) proc->ready_threads--; thread->looper &= ~BINDER_LOOPER_STATE_WAITING; ... return 0; }
|
-
由于传入的参数*consumed==0,所以写入一个值BR_NOOP到ptr指向的缓冲区(即用户传入的bwr_read_buffer缓冲区)中
-
由于thread->transaction_stack==NULL,而且thread->todo列表也为空,所以wait_for_proc_work为true,表示要去查看proc是否有未处理的事务
-
当前thread->return_error==BR_OK,这是前面创建binder_thread时设置的,所以继续往下执行,设置thread的状态为BINDER_LOOPER_STATE_WAITING,表示线程处于等待状态
-
调用binder_set_nice()函数设置当前线程的优先级与当前进程的默认优先级,这是因为thread要去处理属于proc的事务,因此要将thread的优先级设置得和proc一样
-
在当前场景中,proc没有事务需要处理,即binder_has_proc_work(proc,thread)为false. 如果文件打开模式为非阻塞式,即non_block为true,那么函数就直接返回-EAGAIN,要求用户重新执行ioctl();否则当前线程就通过wait_event_interruptible_exclusive()函数进入休眠状态,等待请求到来再被唤醒
5.总结
至此,我们就分析完了Context Manager(也可以称为Service Manager)是如何将自身注册到Binder Driver中并且成为守护进程的。总结起�