机器学习---支持向量机(SVM)
很久之前就学了SVM,总觉得不就是找到中间那条线嘛,但有些地方模棱两可,真正编程的时候又是一团浆糊,参数随意试验,毫无章法。既然又重新学到了这一章节,那就要把之前没有搞懂的地方都整明白,再也不要做无用功了~算法很简单,如果学不会,只是因为懒~写下这段话,只为提醒自己
以下使用到的图片来自上海交大杨旸老师的课件,网址如下:http://bcmi.sjtu.edu.cn/~yangyang/ml/
支持向量机就是一种分类方法,只是起的这个名字,看起来很复杂而已。
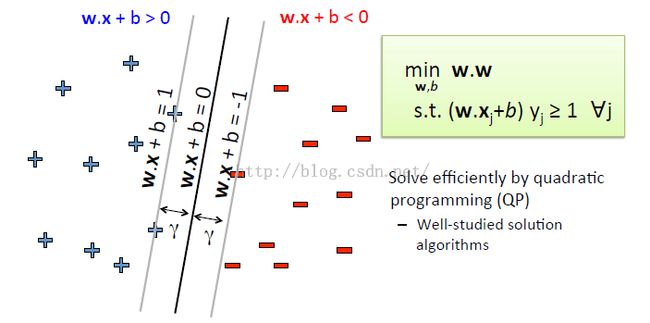
中间一条线:分类用的,需要求出系数W , b
支持向量:线性超平面上的点,可以理解为两边的线上的点
要求:中间那条线到两边的线的距离相等。支持向量(可以想象成那两条线上每条线上的点)的个数<= m +1,m为特征 x 的维数。
目的:找的中间那条线的参数 w 和 b 。
线性SVM
这个图我看了很久,一直没有搞懂 y 在哪里,根据公式明明就直接求出所有的 x 了啊,难道 y = a ?y = a - b ?
其实 y 在这里不是坐标轴啦,是分类0,1,2,...,1,-1之类的,坐标轴上全都是 x1,x2,x3,....这样的啦
搞清楚这个概念,接下来就很好理解了:
两条线之间的距离就直接拿 wx1 + b = a 和 wx2 + b = -a 相减就好啦(x1是上边直线上的点,x2是下边直线上的点),至于为神马这样 2r 就刚好是垂直距离,很简单,两个点坐标相减就是两点之间的向量,膜就是距离,找两个连线与分类直线垂直的点就OK拉。真正用公式推导是这样的:
w(x1-x2)=2a
||w|| ||x1-x2|| cos<w, x1-x2> = 2a
||x1-x2|| cos<w, x1-x2> = 2a/||w||
公式左边就是距离啦。
证明的第一问也好理解了,这里的在线上指的是 x1 和 x2 都在 wx + b =0 这条线上,相减刚好就是<w, x1- x2> = 0
解释一下:
理想情况下,所有正样本(y=1)都在 wx + b = a 这条线的上边,所有负样本(y=-1)都在 wx + b = -a 这条线的下边,但是两个公式太麻烦啦,那就把 y 当作正负号乘到前边好啦,刚好把上下两条直线公式改编合成这样: (wx + b)y = a ,这样的点是在线上的,但是我们要求正负样本在两侧就好啦,所以改 = 为 >=
max 那句就是说仅仅满足下边的公式还不够,我们需要的是两条线中间的距离最大
总之:就是对于任意的点 j 求使得两条线的距离最大的 w 和 b
总是带着 a 不太方便,所以我们把等式两边都除以 a ,就有了新的 w 和 b,无所谓啦,反正都是符号,所以就没改啦。
由于a都变成1了,所以最大化 2a / || w || 倒过来就成了 || w || / 2,也就可以简化为求 w . w = || w || 的最小值了~
非线性SVM
一切看起来进展非常顺利,然而!真实的数据很有可能出现一些不太友好的点哦!
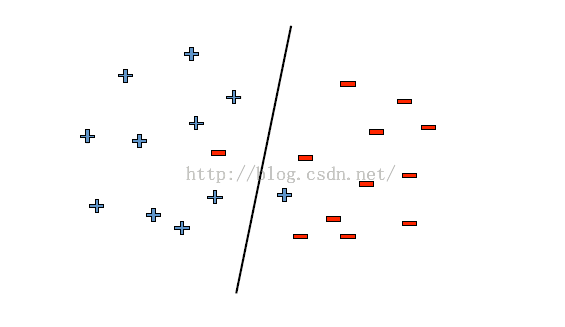
于是,我们就需要容忍这些错误~
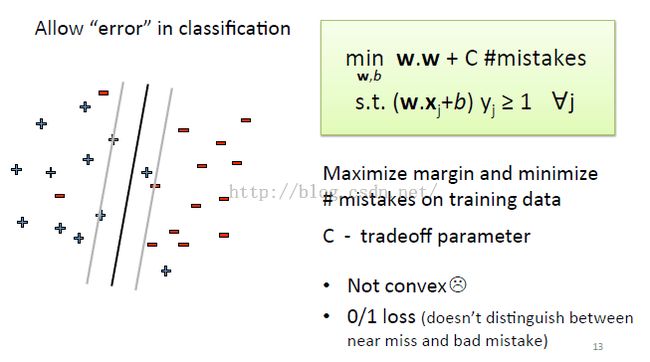
c:tradeoff parameter 其实就是一个系数
#mistake:错误数,对于每一个错误的点都为1,正确点都取0,最后加到一起(公式为了让总错误最小)
c和#mistake都是变量,可以合在一起成为一个的,但不便于理解
#mistake是算出来的,系数C是根据交叉验证得到的——(交叉验证。。不大懂,之后再说咯)
上边这个公式有个缺点:对于不在分类线外侧的全都定义为错的(也就是非黑即白,0/1 loss),没有考虑偏离大小的问题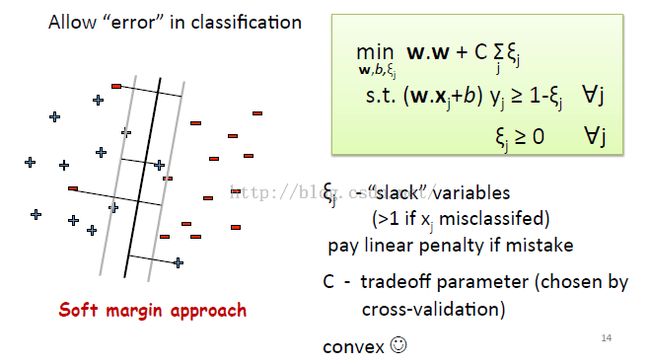
公式把#mistake改成这样,就相当于对于每一个错误的样本都算出其对应的偏离量,这样放在公式里就是所有偏离量加起来最小。
偏离量是算出来的,系数C是根据交叉验证得到的——(交叉验证。。不大懂,之后再说咯)
规范化损失变量
直接套公式吧。。
hinge loss 我想多解释一下,因为这个样本在它应在的范围(如 >=1 ),那么它其实是没有损失的,也就是全为0就好,所以或许这个损失函数蛮符合SVM的特点~
多分类问题
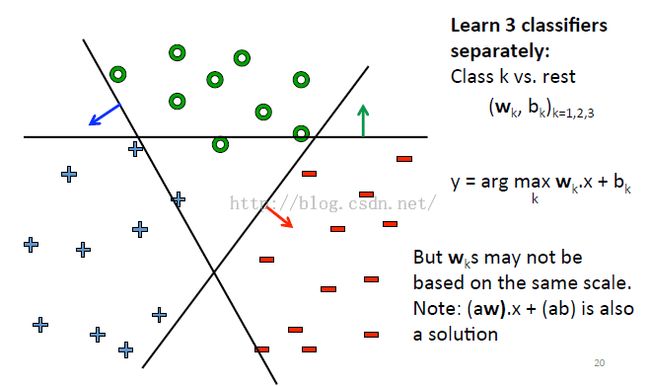
方法一:
如上图所示——每次把一个类别拿出来,其他类别合成一个大类,当作二分类问题来做。重复n次就OK
缺点:分类的那条线会偏向训练数据量比较小的那一类
方法二:同时求
解释一下公式:
左边是分类在 j 的一个点 xj 乘以它自己的系数,需要满足 w(yj) . xj + b(yj) > = 1
参考方法一,如果这个点用在其他的分类公式中的时候,需要满足 w(y‘) . xj + b(y’) < = 1
所以两个公式放在一起就是: w(yj) . xj + b(yj) > = 1 > = w(y') . xj + b(y')
至于非要加上的那个1~~我也不知道为神马,莫非是为了和之前的公式看起来差不多?0.0
加上松弛变量和损失变量就变成了这样:
约束优化(Constrained Optimized)
剧透下:以下主要介绍了一种用于解上边那个有关SVM的优化问题方法~(没学过最优化伤不起,得补啊)
首先举个有关求最小值的例子

上图例子说明,b 取不同的值的时候我们得到的最小值是不一样的
第一个图没有约束,第二个图约束没有起到作用,第三个图约束起作用啦
上图说的是拉格朗日对偶:
首先给定初始问题,求满足<= 和 = 那两个条件(这是概括讲的,所有的约束条件都可以转换为这两种形式),并且 f(w) 取最小值的时候 w 的值
其中 Alpha 和 Beta 是拉格朗日乘数(就是起了个名)
Lemma(引理):
这时候把这些式子加起来,最大也就是 f(w) 了,因为 g h要么小于等于0,要么等于0,并且要求 Alpha(i) > 0, 所以他们总的和 L 不会比 f(w) 再大了~
o/w是otherwise的意思,此时 max L 取值为无穷的解释如下:
如果有一个样本不符合限制条件g-i(w) = 0,即存在一个g-i(w) > 0,那么max L(w, alpha, beta) —>无穷。
因为Alpha-i为任意参数,Alpha-i > 0, g-i(w) > 0,当Alpha-i 趋向于无穷的时候,max Alpha-i g-i(w)也趋向于无穷,所以此时的 max L 趋向于无穷~
其实大括号后边第一行,我们还有一个条件也可以合进来,这个条件就是满足 min(w) f(w),也就是让 L 的最大值 f(w) 最小然后求 w 嘛,就在前边加个min,就是最后一个式子啦

这就是又写了一遍引理,第二个是它的对偶问题,弱对偶和强对偶可以看下图理解下:
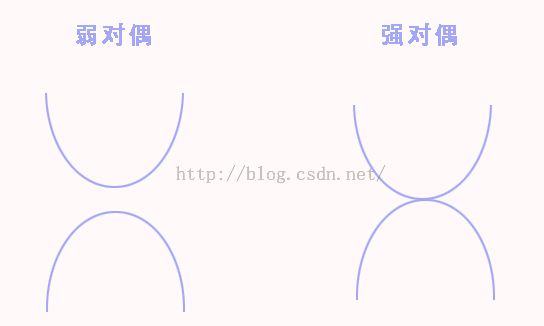
就是先求最大再求最小,和先求最小再求最大能不能对上,有没有交点的问题。没有就是弱对偶,有就是强对偶
根据上图我们就可以看出来,其实找到最优值就是找鞍点(最大or最小,看起来像马鞍的形状,所以那个点就叫鞍点)的过程。

求鞍点,就是求各种一阶导为0,第三个式子是因为之前说了 g 代表 <= 0 那一堆公式,那么取得鞍点的时候,它必须取极值点 = 0,最后两个公式是之前就规定好的~
这五个式子就是KKT条件,如果 w , Alpha , Beta 满足KKT条件,那么它们就是那个引理和它对偶问题的一个解
讲了这么一堆,终于把解法讲好了,然后就要用到我们的SVM上了

经过上边一堆推导,我们终于把 w 和 b 去掉(用x y Alpha 表示)了,只剩下 Alpha 是未知的了~!
于是这就转变为了二次规划问题(这样就很好解么?木有学过最优化啊,不知道这是神马啊)
到目前,你只需要知道 w 被那个求和 替代了,SVM有个核是 x'x 就好

根据KKT条件,有一部分 Alpha 不为0,看图,支持向量就是 Alpha 不为 0 的点
根据我们已知的可以算出来的 w ,根据分类的那条线 wx + b = 0,就可以求出 b, 然后我们就可以测试新数据 z 啦
最优的 w 可以看作是一部分点的一个线性组合,这个稀疏表达可以看作是KNN分类器结构中的数据压缩(没懂,重要么?)
为了计算 Alpha ,我们只需要知道核(kernel,即x'x)就好啦
测试的时候使用下边的式子(sign表示取符号,可能这个式子在模拟二分类问题,所以只要符号就行了):
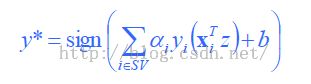
下边解释一下核(kernel)的作用
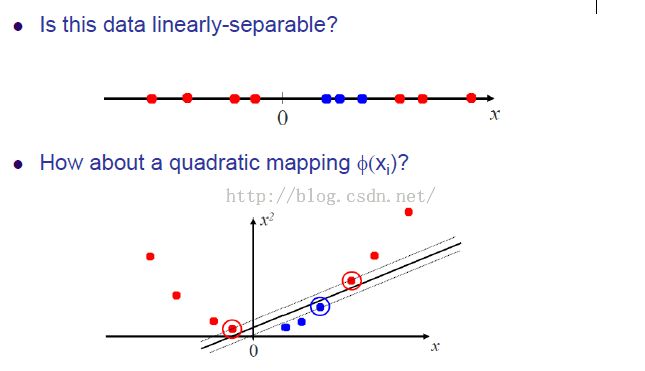
就是把 x 多加一个维度(or 没有增加维度 or 降维),使得原本非线性的问题成为线性的。
在之前的问题中,我们提到过,我们只需要提供x'x就可以了,所以这里把 x'x 替换一下,就是带进公式之前先行处理一下,也就是加了那个核运算,那么我们可能会得到更好的结果哦
下边这是几个核的例子:
关于选神马核比较好,编程的时候大胆试吧。。。
我本以为公式已经全了呢额。直到我看到了下边的改动,又对Alpha 加了个最大值C的约束,其他没变~

SMO算法
首先我们来了解一下神马是坐标上升(Coordinate Ascent)
一个无约束优化问题如下:
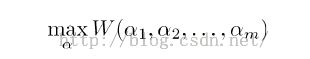
可以使用坐标上升算法来解
这个和梯度下降很像, 梯度下降是选下降最快的方向,但是坐标上升每次只改变一个维度(变量),而其他维度(变量)不变,如下图:
但是当我们遇到了SVM这种有约束的问题,它的不同之处在于有一个等式(即第三个等式:求和 Alpha . y =0),因此我们需要定义两个变量,Alpha(i)和Alpha(j)同时变,但是Alpha(i)可以用Alpha(j)表示出来,其实还是可以理解为一个变量哦~~
这时候坐标上升就转换为了SMO算法啦!
下边是解SVM那个式子的SMO算法的核心思想:

后边的课件是证明SMO收敛,数学问题就就不讲了哈,主要就是满足KKT条件吧~~
编程的话,libsvm不错,好像前边的博文有讲到用法哦~
如果博文中有任何问题,欢迎随时与我联系修正~在此感谢李凡师兄,邵志文同学,朱能军同学对本文存疑的解答^.^