(2.1.8)Java之集合类:set、list、hashmap、hashtable等和迭代器iterator
一、容器
常见的集合类有这些种:
实现Collection接口的:Set、List以及他们的实现类。
实现Map接口的:HashMap及其实现类
编程爱好者学习,下面我我们通过一个图来整体描述一下:
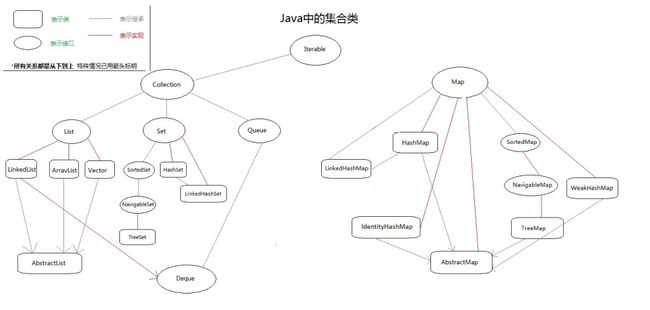
这个图片没法显示的很清楚,所以我将原始图片上传到了我的资源里:http://download.csdn.net/detail/zhangerqing/4711389。愿意看清楚的就去下吧。
下面的表格也许可以更直接的表现出他们之间的区别和联系:
| 接口 |
简述 |
实现 |
操作特性 |
成员要求 |
| Set |
成员不能重复 |
HashSet |
外部无序地遍历成员 |
成员可为任意Object子类的对象,但如果覆盖了equals方法,同时注意修改hashCode方法。 |
| TreeSet |
外部有序地遍历成员;附加实现了SortedSet, 支持子集等要求顺序的操作 |
成员要求实现caparable接口,或者使用 Comparator构造TreeSet。成员一般为同一类型。 |
||
| LinkedHashSet |
外部按成员的插入顺序遍历成员 |
成员与HashSet成员类似 |
||
| List |
提供基于索引的对成员的随机访问 |
ArrayList |
提供快速的基于索引的成员访问,对尾部成员的增加和删除支持较好 |
成员可为任意Object子类的对象 |
| LinkedList |
对列表中任何位置的成员的增加和删除支持较好,但对基于索引的成员访问支持性能较差 |
成员可为任意Object子类的对象 |
||
| Map |
保存键值对成员,基于键找值操作,compareTo或compare方法对键排序 |
HashMap |
能满足用户对Map的通用需求 |
键成员可为任意Object子类的对象,但如果覆盖了equals方法,同时注意修改hashCode方法。 |
| TreeMap |
支持对键有序地遍历,使用时建议先用HashMap增加和删除成员,最后从HashMap生成TreeMap;附加实现了SortedMap接口,支持子Map等要求顺序的操作 |
键成员要求实现caparable接口,或者使用Comparator构造TreeMap。键成员一般为同一类型。 |
||
| LinkedHashMap |
保留键的插入顺序,用equals 方法检查键和值的相等性 |
成员可为任意Object子类的对象,但如果覆盖了equals方法,同时注意修改hashCode方法。 |
||
| IdentityHashMap |
使用== 来检查键和值的相等性。 |
成员使用的是严格相等 |
||
| WeakHashMap |
其行为依赖于垃圾回收线程,没有绝对理由则少用 |
|
(上图来源于网友的总结,已不知是哪位的原创,恕不贴出地址,如原作者看到请联系我,必将贴出链接!)
实现Collection接口的类,如Set和List,他们都是单值元素(其实Set内部也是采用的是Map来实现的,只是键值一样,从表面理解,就是单值),不像实现Map接口的类一样,里面存放的是key-value(键值对)形式的数据。这方面就造成他们很多的不同点,如遍历方式,前者只能采用迭代或者循环来取出值,但是后者可以使用键来获得值得值。
1、HashMap和HashTable
相同点:二者都实现了Map接口,因此具有一系列Map接口提供的方法。
不同点:
1、HashMap继承了AbstractMap,而HashTable继承了Dictionary。
2、HashMap非线程安全,HashTable线程安全,到处都是synchronized关键字。
3、因为HashMap没有同步,所以处理起来效率较高。
4、HashMap键、值都允许为null,HashTable键、值都不允许有null。
5、HashTable使用Enumeration,HashMap使用Iterator。
1-1、HashMap和ConcurrentHashMap
ConcurrentHashMap是线程安全的HashMap的实现。同样是线程安全的类,它与HashTable在同步方面有什么不同呢?
之前我们说,synchronized关键字加锁的原理,其实是对对象加锁,不论你是在方法前加synchronized还是语句块前加,锁住的都是对象整体,但是ConcurrentHashMap的同步机制和这个不同,它不是加synchronized关键字,而是基于lock操作的,这样的目的是保证同步的时候,锁住的不是整个对象。
2、Set接口和List接口
相同点:都实现了Collection接口
不同点:
1、Set接口不保证维护元素的顺序,而且元素不能重复。List接口维护元素的顺序,而且元素可以重复。
2、关于Set元素如何保证元素不重复,我将在下面的博文中给出。
3、ArrayList和LinkList
相同点:都实现了Collection接口
不同点:ArrayList基于数组,具有较高的查询速度,而LinkedList基于双向循环列表,具有较快的添加或者删除的速度,二者的区别,其实就是数组和列表的区别。上文有详细的分析。
4、SortedSet和SortedMap
二者都提供了排序的功能。 来看一个小例子:
5、TreeMap和HashMap
HashMap具有较高的速度(查询),TreeMap则提供了按照键进行排序的功能。
6、HashSet和LinkedHashSet
HashSet,为快速查找而设计的Set。存入HashSet的对象必须实现hashCode()和equals()。
LinkedHashSet,具有HashSet的查询速度,且内部使用链表维护元素的顺序(插入的次序),于是在使用迭代器遍历Set时,结果会按元素插入的次序显示。
7、TreeSet和HashSet
TreeSet: 提供排序功能的Set,底层为树结构 。相比较HashSet其查询速度低,如果只是进行元素的查询,我们一般使用HashSet。
8、ArrayList和Vector
同步性:Vector是线程安全的,也就是说是同步的,而ArrayList是线程序不安全的,不是同步的。
数据增长:当需要增长时,Vector默认增长为原来一培,而ArrayList却是原来的一半
9、Collection和Collections
Collection是一系列单值集合类的父接口,提供了基本的一些方法,而Collections则是一系列算法的集合。里面的属性和方法基本都是static的,也就是说我们不需要实例化,直接可以使用类名来调用。下面是Collections类的一些功能列表:
二、迭代器
迭代器是一种设计模式,它是一个对象,它可以遍历并选择序列中的对象,而开发人员不需要了解该序列的底层结构。迭代器通常被称为“轻量级”对象,因为创建它的代价小。
Java中的Iterator功能比较简单,并且只能单向移动:
(1) 使用方法iterator()要求容器返回一个Iterator。第一次调用Iterator的next()方法时,它返回序列的第一个元素。注意:iterator()方法是java.lang.Iterable接口,被Collection继承。
(2) 使用next()获得序列中的下一个元素。
(3) 使用hasNext()检查序列中是否还有元素。
(4) 使用remove()将迭代器新返回的元素删除。
Iterator是Java迭代器最简单的实现,为List设计的ListIterator具有更多的功能,它可以从两个方向遍历List,也可以从List中插入和删除元素。
list l = new ArrayList();
l.add("aa");
l.add("bb");
l.add("cc");
for (Iterator iter = l.iterator(); iter.hasNext();) {
String str = (String)iter.next();
System.out.println(str);
}
/*迭代器用于while循环
Iterator iter = l.iterator();
while(iter.hasNext()){
String str = (String) iter.next();
System.out.println(str);
}
*/
注意:使用iterator时候,不能同时对容器进行删减,否则会丢出异常concurrentdificationexception