【sql查询与优化】3.操作多个表
注:以下所有sql案例均取自"oracle查询优化改写技巧与案例"丛书。
EMP表的详细:
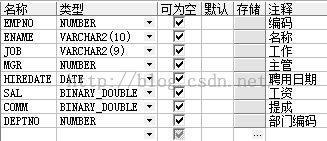
查询所有信息,
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO
---------- -------------------- ------------------ ---------- -------------- ---------- ---------- ----------
1110 张三 主管 3322 12-3月 -14 5200 20
1111 李四 销售 3321 03-11月-15 3400 500 30
1112 王五 销售 3321 25-4月 -12 4400 800 30
1113 赵二 后勤 3320 30-5月 -11 3450 40
1114 李磊磊 会计 3319 22-12月-15 2500 50
1115 张少丽 销售 3321 11-3月 -16 3400 1400 30
1116 林建国 主管 3322 22-1月 -16 5700 20
1117 马富邦 后勤 3320 22-7月 -13 2800 40
1118 沈倩 会计 3319 06-5月 -10 2100 50
已选择9行。
DEPT表的详细:

查询所有信息
DEPTNO DNAME
-------- --------
3322 管理部门
3321 销售部门
3320 后勤部门
3319 金融部门
1.union all与空字符串
union all通常用于合并多个数据集
例子:
编码 名称 上级编码
---------- ------- -----------
1110 张三 3322
1111 李四 3321
1112 王五 3321
1113 赵二 3320
1114 李磊磊 3319
1115 张少丽 3321
1116 林建国 3322
1117 马富邦 3320
1118 沈倩 3319
3322 管理部门
3321 销售部门
3320 后勤部门
3319 金融部门
已选择13行。
可以看到,当一个数据集列不够时,可以用null来填充该列的值,而空字符串在oracle中常常相当于null:
-
null
空字符串不等价与null
2.union 与 or
执行下面的查询
EMPNO ENAME
---------- --------------------
1116 林建国
如果改写为union all,则结果就是错的
EMPNO ENAME
---------- --------------------
1116 林建国
1116 林建国
因为原语句中用的条件是or,是两个结果的合集而非并集,所以一般改写时要改为union来去掉重复的数据。
EMPNO ENAME
---------- --------------------
1116 林建国
注意:
(1)不仅两个数据集间重复的数据会被去重,而且单个数据集里重复的数据也会被去重。
(2)有重复数据的数据集用union后得到的数据与预期会不一样。
用union all来模拟union语句的过程:
DEPTNO
----------
40
其实就是合并->去重->排序这三步。
想要保留住单个数据集中重复的数据,在去重前加一个唯一标识各行的列即可。
例如,我们可以加入“empno”,再利用union,效果如下:
EMPNO DEPTNO
---------- ----------
1113 40
1117 40
除了用唯一列,主键列外,还可以使用rowid。
DEPTNO
----------
40
40
3.组合相关的行
显示部门30的员工编码、姓名及所在部门名称
EMPNO ENAME DNAME
---------- ------------- -------------
1115 张少丽 销售部门
1112 王五 销售部门
1111 李四 销售部门
另有写法如下
其中,join的写法是SQL-92的标准,当有多个表关联时,join方式的写法能更清楚地看清各表之间的关系,因此,建议大家写查询语句的时候优先使用join写法。
4.in、exists和inner join
下面先创建一个表emp2。
表已创建。
要求返回与表emp2(empno,job,sal)中数据相匹配的emp(empno,ename,job,sal,deptno)信息。
有in、exists、inner join三种写法。
(1)in写法
EMPNO ENAME JOB SAL DEPTNO
---------- -------------------- ------------------ ---------- ----------
1111 李四 销售 3400 30
1112 王五 销售 4400 30
1115 张少丽 销售 3400 30
(2)exists写法
---------- -------------------- ------------------ ---------- ----------
1111 李四 销售 3400 30
1112 王五 销售 4400 30
1115 张少丽 销售 3400 30
(3)inner join
因为子查询的join列(emp2.ename,emp2.job,mep2.sal)没有重复行,所以这个查询可以直接改为inner join。
EMPNO ENAME JOB SAL DEPTNO
---------- -------------------- ------------------ ---------- ----------
1111 李四 销售 3400 30
1112 王五 销售 4400 30
1115 张少丽 销售 3400 30
5.inner join、left join、right join和full join解析
很多人对这几种连接方式,特别是left join与right join分不清,下面通过案例来解析一下。
首先建立两个测试用表:
建好的表
STR V
------------ --
left_1 1
left_2 2
left_3 3
left_4 4
STR V STATUS
-------------- -- ----------
right_3 3 1
right_4 4 0
right_5 5 0
right_6 6 0
(1)inner join的特点
该方式返回两表相匹配的数据
join写法
LEFT_STR RIGHT_STR
------------ --------------
left_3 right_3
left_4 right_4
左表的“1、2”以及右表的“5、6”都没有显示。
加where条件后的写法
LEFT_STR RIGHT_STR
------------ --------------
left_3 right_3
left_4 right_4
(2)left join的特点
该方式的左表为主表,左表返回所有的数据,右表只返回与左表相匹配的数据。
join写法
LEFT_STR RIGHT_STR
------------ --------------
left_1
left_2
left_3 right_3
left_4 right_4
“5、6”都没有显示。
加(+)后的写法
LEFT_STR RIGHT_STR
------------ --------------
left_1
left_2
left_3 right_3
left_4 right_4
注:
SELECT *FROM TABLE1 A,TABLE2 B WHERE A.ID=B.ID(+);左链接=LEFT JOIN
SELECT *FROM TABLE1 A,TABLE2 B WHERE A.ID(+)=B.ID;右链接=RIGHT JOIN
(3)right join的特点
该方式的右表为主表,左表中只返回与右表匹配的数据“3、4”,而“1、2”都没有显示,右表返回所有的数据。
join写法
LEFT_STR RIGHT_STR
------------ --------------
left_3 right_3
left_4 right_4
right_5
right_6
加(+)后的写法
LEFT_STR RIGHT_STR
------------ --------------
left_3 right_3
left_4 right_4
right_5
right_6
(4)full join 的特点
该方式的左右表均返回所有的数据,但只有相匹配的数据显示在同一行,非匹配的行只显示一个表的数据。
join写法
LEFT_STR RIGHT_STR
------------ --------------
left_1
left_2
left_3 right_3
left_4 right_4
right_5
right_6
注:full join无(+)的写法
6.自关联
创建表
创建表成功。
看一下表内容:
EMPNO ENAME MGR
---------- -------------- ----------
7839 tom 1
7566 jean 7839
7788 jack 7566
7902 allen 7788
7369 adams 7902
7698 jeckson 7839
表emp3中有一个字段mgr,其中是主管的编码(对应于emp.empno):
可以看到,jeckson的MGR是7839,对应tom的EMPNO值,所以tom是jeckson的主管。
如何根据这个信息返回主管的姓名呢?这里用到的就是“自关联”。也就是两次查询表emp3,分别取不同的别名,这样就可以当做是两个表,后面的任务就是将这两个表和join链接起来就可以。
为了便于理解,这里用汉字做别名,并把相关列一起返回。
职工编码 职工姓名 员工表_主管编码 主管表_主管编码 主管姓名
---------- -------------- --------------- --------------- --------------
7369 adams 7902 7902 allen
7566 jean 7839 7839 tom
7698 jeckson 7839 7839 tom
7788 jack 7566 7566 jean
7839 tom 7777
7902 allen 7788 7788 jack
已选择6行。
通过这张表我们可以大致推测出各个职工的上下级情况
tom>jeckson=jean>jack>allen>adams
7.not in、not exists和left join
查询在dept不存在于emp的mgr中的值。
未选定行
8.外连接中的条件不要乱放
对于5节中介绍的左联语句,见下面的数据
LEFT_STR RIGHT_STR STATUS
------------ -------------- ----------
left_1
left_2
left_3 right_3 1
left_4 right_4 0
对于其中的L表,四条数据都返回了。
下面对于R表,我们现在只要求显示其中的status=1,也就是R.v=4的部分。
结果应为:
LEFT_STR RIGHT_STR STATUS
------------ -------------- ----------
left_1
left_2
left_3 right_3 1
left_4
对于这种需求,很多人会这么写
left join用法
(+)用法
这样查询的结果为:
LEFT_STR RIGHT_STR STATUS
------------ -------------- ----------
left_3 right_3 1
很明显,与我们期望得到的结果不一样,这是很多人在写查询或更改查询时常遇到的一种错误。问题就在于所加条件的位置及写法,正确的写法分别如下:
left join用法
9.检测两个表中的数据以及对应数据的条数是否相同
我们首先建立视图如下:
要求用查询找出视图V与表emp中不同的数据。
注意:视图V中员工“李磊磊”有两行数据,而emp表中只有一条数据。
ROWNUM EMPNO ENAME
---------- ---------- --------------------
1 1114 李磊磊
2 1114 李磊磊
ROWNUM EMPNO ENAME
---------- ---------- --------------------
1 1114 李磊磊
比较两个数据集的不同时,通常用类似下面的full join语句
EMPNO ENAME EMPNO ENAME
---------- -------------------- ---------- --------------------
1116 林建国
1110 张三
我们发现这种语句在这个案例中查不到“李磊磊”的区别。
这时我们就要对数据进行处理,增加一列显示相同数据的条数,再进行比较。
正确结果如下:
EMPNO ENAME CNT EMPNO ENAME CNT
---------- ----------- ---------- ---------- ----------- ----------
1114 李磊磊 2
1116 林建国 1
1110 张三 1
1114 李磊磊 1
也就是通过员工“李磊磊”的数量不同导致cnt不同从而发现的不同。
10.聚集与内连接
首先建立案例用表如下:
其中
EMPNO RECEIVED TYPE
---------- -------------- ----------
1111 17-5月 -16 1
1112 15-2月 -16 2
1115 15-2月 -16 3
EMPNO ENAME SAL
---------- -------------------- ----------
1111 李四 3400
1112 王五 4400
1115 张少丽 3400
员工的奖金根据TYPE计算,TYPE=1的奖金为员工工资的10%,TYPE=2的奖金为员工工资的20%,TYPE=3的奖金为员工工资的30%。
现在要求返回上述员工(也就是部门30的所有员工)的工资及奖金。
我们首先想到的是使用join语句,先关联,然后对结果做聚集。
那么在做聚集之前,我们先先看一下关联后的结果。
EMPNO ENAME SAL BONUS
---------- -------------------- ---------- ----------
1111 李四 3400 340
1112 王五 4400 880
1115 张少丽 3400 1020
对这样的关联结果进行聚集后的数据如下:
DEPTNO TOTAL_SAL TOTAL_BONUS
---------- ---------- -----------
30 11200 2240
我们核对一下,工资总额和奖金总额都没有问题。
11.聚集与外连接
如果我们要分别返回所有部门的工资及奖金怎么办?因上述奖金数据只含部门30,那么改为left join就可以。
---------- ---------- -----------
20 10900
30 11200 2240
40 6250
50 4600
先做聚集操作,然后外连接。
转载请注明出处:http://blog.csdn.net/acmman/article/details/51062195
EMP表的详细:
查询所有信息,
SQL> select * from emp;
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO
---------- -------------------- ------------------ ---------- -------------- ---------- ---------- ----------
1110 张三 主管 3322 12-3月 -14 5200 20
1111 李四 销售 3321 03-11月-15 3400 500 30
1112 王五 销售 3321 25-4月 -12 4400 800 30
1113 赵二 后勤 3320 30-5月 -11 3450 40
1114 李磊磊 会计 3319 22-12月-15 2500 50
1115 张少丽 销售 3321 11-3月 -16 3400 1400 30
1116 林建国 主管 3322 22-1月 -16 5700 20
1117 马富邦 后勤 3320 22-7月 -13 2800 40
1118 沈倩 会计 3319 06-5月 -10 2100 50
已选择9行。
DEPT表的详细:
查询所有信息
SQL> select * from dept t;
DEPTNO DNAME
-------- --------
3322 管理部门
3321 销售部门
3320 后勤部门
3319 金融部门
1.union all与空字符串
union all通常用于合并多个数据集
例子:
SQL> select empno as 编码, ename as 名称, nvl(mgr,deptno) as 上级编码
from emp
union all
select deptno as 编码,dname as 名称,NULL as 上级编码
from dept;
编码 名称 上级编码
---------- ------- -----------
1110 张三 3322
1111 李四 3321
1112 王五 3321
1113 赵二 3320
1114 李磊磊 3319
1115 张少丽 3321
1116 林建国 3322
1117 马富邦 3320
1118 沈倩 3319
3322 管理部门
3321 销售部门
3320 后勤部门
3319 金融部门
已选择13行。
可以看到,当一个数据集列不够时,可以用null来填充该列的值,而空字符串在oracle中常常相当于null:
SQL> select '' as cl from dual;C
-
null
空字符串不等价与null
2.union 与 or
执行下面的查询
SQL> select empno,ename from emp where empno = 1116 or ename = '林建国';
EMPNO ENAME
---------- --------------------
1116 林建国
如果改写为union all,则结果就是错的
SQL> select empno,ename from emp where empno = 1116
union all
select empno,ename from emp where ename = '林建国';
EMPNO ENAME
---------- --------------------
1116 林建国
1116 林建国
因为原语句中用的条件是or,是两个结果的合集而非并集,所以一般改写时要改为union来去掉重复的数据。
SQL> select empno,ename from emp where empno = 1116
union
select empno,ename from emp where ename = '林建国';
EMPNO ENAME
---------- --------------------
1116 林建国
注意:
(1)不仅两个数据集间重复的数据会被去重,而且单个数据集里重复的数据也会被去重。
(2)有重复数据的数据集用union后得到的数据与预期会不一样。
用union all来模拟union语句的过程:
SQL> select distinct deptno
from (select deptno from emp where mgr = 3320
union all
select deptno from emp where job = '后勤')
order by 1;
DEPTNO
----------
40
其实就是合并->去重->排序这三步。
想要保留住单个数据集中重复的数据,在去重前加一个唯一标识各行的列即可。
例如,我们可以加入“empno”,再利用union,效果如下:
SQL> select empno,deptno from emp where mgr = 3320
union
select empno,deptno from emp where job = '后勤';
EMPNO DEPTNO
---------- ----------
1113 40
1117 40
除了用唯一列,主键列外,还可以使用rowid。
SQL> select deptno
from
(select ROWID,deptno from emp where mgr = 3320
union
select ROWID,deptno from emp where job = '后勤')
order by 1;
DEPTNO
----------
40
40
3.组合相关的行
显示部门30的员工编码、姓名及所在部门名称
SQL> select e.empno,e.ename,d.dname
from emp e
inner join dept d on (e.mgr = d.deptno)
where e.deptno = 30;
EMPNO ENAME DNAME
---------- ------------- -------------
1115 张少丽 销售部门
1112 王五 销售部门
1111 李四 销售部门
另有写法如下
select e.empno,e.ename,d.dname
from emp e,dept d
where e.mgr = d.deptno
and e.deptno = 30;
其中,join的写法是SQL-92的标准,当有多个表关联时,join方式的写法能更清楚地看清各表之间的关系,因此,建议大家写查询语句的时候优先使用join写法。
4.in、exists和inner join
下面先创建一个表emp2。
SQL> create table emp2 as 2 select ename,job,sal,comm from emp where job = '销售';
表已创建。
要求返回与表emp2(empno,job,sal)中数据相匹配的emp(empno,ename,job,sal,deptno)信息。
有in、exists、inner join三种写法。
(1)in写法
SQL> select empno,ename,job,sal,deptno
from emp
where (ename,job,sal) in (select ename,job,sal from emp2);
EMPNO ENAME JOB SAL DEPTNO
---------- -------------------- ------------------ ---------- ----------
1111 李四 销售 3400 30
1112 王五 销售 4400 30
1115 张少丽 销售 3400 30
(2)exists写法
SQL> select empno,ename,job,sal,deptno
from emp a
where exists (select null
from emp2 b
where b.ename = a.ename
and b.job = a.job
and b.sal = a.sal); EMPNO ENAME JOB SAL DEPTNO
---------- -------------------- ------------------ ---------- ----------
1111 李四 销售 3400 30
1112 王五 销售 4400 30
1115 张少丽 销售 3400 30
(3)inner join
因为子查询的join列(emp2.ename,emp2.job,mep2.sal)没有重复行,所以这个查询可以直接改为inner join。
SQL> select a.empno,a.ename,a.job,a.sal,a.deptno
from emp a
inner join emp2 b on (b.ename = a.ename and b.job = a.job and b.sal = a.sal);
EMPNO ENAME JOB SAL DEPTNO
---------- -------------------- ------------------ ---------- ----------
1111 李四 销售 3400 30
1112 王五 销售 4400 30
1115 张少丽 销售 3400 30
5.inner join、left join、right join和full join解析
很多人对这几种连接方式,特别是left join与right join分不清,下面通过案例来解析一下。
首先建立两个测试用表:
/*左表*/ create table L as select 'left_1' as str,'1' as v from dual union all select 'left_2','2' as v from dual union all select 'left_3','3' as v from dual union all select 'left_4','4' as v from dual; /*右表*/ create table R as select 'right_3' as str,'3' as v,1 as status from dual union all select 'right_4' as str,'4' as v,0 as status from dual union all select 'right_5' as str,'5' as v,0 as status from dual union all select 'right_6' as str,'6' as v,0 as status from dual;
建好的表
SQL> select * from L;
STR V
------------ --
left_1 1
left_2 2
left_3 3
left_4 4
SQL> select * from R;
STR V STATUS
-------------- -- ----------
right_3 3 1
right_4 4 0
right_5 5 0
right_6 6 0
(1)inner join的特点
该方式返回两表相匹配的数据
join写法
SQL> select L.str as left_str,R.str as right_str
from L
inner join R on L.v = R.v
order by 1,2;
LEFT_STR RIGHT_STR
------------ --------------
left_3 right_3
left_4 right_4
左表的“1、2”以及右表的“5、6”都没有显示。
加where条件后的写法
SQL> select L.str as left_str,R.str as right_str
from L,R
where L.v = R.v
order by 1,2;
LEFT_STR RIGHT_STR
------------ --------------
left_3 right_3
left_4 right_4
(2)left join的特点
该方式的左表为主表,左表返回所有的数据,右表只返回与左表相匹配的数据。
join写法
SQL> select L.str as left_str,R.str as right_str
from L
left join R on L.v = R.v
order by 1,2;
LEFT_STR RIGHT_STR
------------ --------------
left_1
left_2
left_3 right_3
left_4 right_4
“5、6”都没有显示。
加(+)后的写法
SQL> select L.str as left_str,R.str as right_str
from L,R
where L.v = R.v(+)
order by 1,2;
LEFT_STR RIGHT_STR
------------ --------------
left_1
left_2
left_3 right_3
left_4 right_4
注:
SELECT *FROM TABLE1 A,TABLE2 B WHERE A.ID=B.ID(+);左链接=LEFT JOIN
SELECT *FROM TABLE1 A,TABLE2 B WHERE A.ID(+)=B.ID;右链接=RIGHT JOIN
(3)right join的特点
该方式的右表为主表,左表中只返回与右表匹配的数据“3、4”,而“1、2”都没有显示,右表返回所有的数据。
join写法
SQL> select L.str as left_str,R.str as right_str
from L
right join R on L.v = R.v
order by 1,2;
LEFT_STR RIGHT_STR
------------ --------------
left_3 right_3
left_4 right_4
right_5
right_6
加(+)后的写法
SQL> select L.str as left_str,R.str as right_str
from L,R
where L.v(+) = R.v
order by 1,2;
LEFT_STR RIGHT_STR
------------ --------------
left_3 right_3
left_4 right_4
right_5
right_6
(4)full join 的特点
该方式的左右表均返回所有的数据,但只有相匹配的数据显示在同一行,非匹配的行只显示一个表的数据。
join写法
SQL> select L.str as left_str,R.str as right_str
from L
full join R on L.v = R.v
order by 1,2;
LEFT_STR RIGHT_STR
------------ --------------
left_1
left_2
left_3 right_3
left_4 right_4
right_5
right_6
注:full join无(+)的写法
6.自关联
创建表
create table emp3 as select 7839 as empno,'tom' as ename,1 as mgr from dual union all select 7566 as empno,'jean' as ename,7839 as mgr from dual union all select 7788 as empno,'jack' as ename,7566 as mgr from dual union all select 7902 as empno,'allen' as ename,7788 as mgr from dual union all select 7369 as empno,'adams' as ename,7902 as mgr from dual union all select 7698 as empno,'jeckson' as ename,7839 as mgr from dual;
创建表成功。
看一下表内容:
SQL> select * from emp3;
EMPNO ENAME MGR
---------- -------------- ----------
7839 tom 1
7566 jean 7839
7788 jack 7566
7902 allen 7788
7369 adams 7902
7698 jeckson 7839
表emp3中有一个字段mgr,其中是主管的编码(对应于emp.empno):
可以看到,jeckson的MGR是7839,对应tom的EMPNO值,所以tom是jeckson的主管。
如何根据这个信息返回主管的姓名呢?这里用到的就是“自关联”。也就是两次查询表emp3,分别取不同的别名,这样就可以当做是两个表,后面的任务就是将这两个表和join链接起来就可以。
为了便于理解,这里用汉字做别名,并把相关列一起返回。
SQL> select 员工.empno as 职工编码,
员工.ename as 职工姓名,
员工.mgr as 员工表_主管编码,
主管.empno as 主管表_主管编码,
主管.ename as 主管姓名
from emp3 员工
left join emp3 主管 on (员工.mgr = 主管.empno)
order by 1;
职工编码 职工姓名 员工表_主管编码 主管表_主管编码 主管姓名
---------- -------------- --------------- --------------- --------------
7369 adams 7902 7902 allen
7566 jean 7839 7839 tom
7698 jeckson 7839 7839 tom
7788 jack 7566 7566 jean
7839 tom 7777
7902 allen 7788 7788 jack
已选择6行。
通过这张表我们可以大致推测出各个职工的上下级情况
tom>jeckson=jean>jack>allen>adams
7.not in、not exists和left join
查询在dept不存在于emp的mgr中的值。
SQL> select * from dept where deptno not in (select emp.mgr from emp where emp.m gr is not null);
未选定行
8.外连接中的条件不要乱放
对于5节中介绍的左联语句,见下面的数据
SQL> select L.str as left_str,R.str as right_str,R.status
from L
left join R on L.v = R.v
order by 1,2;
LEFT_STR RIGHT_STR STATUS
------------ -------------- ----------
left_1
left_2
left_3 right_3 1
left_4 right_4 0
对于其中的L表,四条数据都返回了。
下面对于R表,我们现在只要求显示其中的status=1,也就是R.v=4的部分。
结果应为:
LEFT_STR RIGHT_STR STATUS
------------ -------------- ----------
left_1
left_2
left_3 right_3 1
left_4
对于这种需求,很多人会这么写
left join用法
select L.str as left_str,R.str as right_str,R.status
from L
left join R on L.v = R.v
where R.status = 1
order by 1,2;
(+)用法
select L.str as left_str,R.str as right_str,R.status
from L
where L.v = R.v(+)
and R.status = 1
order by 1,2;
这样查询的结果为:
LEFT_STR RIGHT_STR STATUS
------------ -------------- ----------
left_3 right_3 1
很明显,与我们期望得到的结果不一样,这是很多人在写查询或更改查询时常遇到的一种错误。问题就在于所加条件的位置及写法,正确的写法分别如下:
left join用法
select L.str as left_str,R.str as right_str,R.status
from L
left join R on (L.v = R.v and r.status = 1)
order by 1,2;(+)用法
select L.str as left_str,R.str as right_str,R.status
from L,R
where L.v = R.v(+)
and status(+) = 1
order by 1,2;语句也可以像下面这样写,先过滤,再用join,这样会更加清晰。
select L.str as left_str,R.str as right_str,R.status
from L
left join (select * from R where R.status = 1)R on (L.v = R.v)
order by 1,2;
9.检测两个表中的数据以及对应数据的条数是否相同
我们首先建立视图如下:
create or replace view v as
select * from emp where deptno != 20
union all
select * from emp where ename = '李磊磊';
要求用查询找出视图V与表emp中不同的数据。
注意:视图V中员工“李磊磊”有两行数据,而emp表中只有一条数据。
SQL> select rownum,empno,ename from v where ename = '李磊磊';
ROWNUM EMPNO ENAME
---------- ---------- --------------------
1 1114 李磊磊
2 1114 李磊磊
SQL> select rownum,empno,ename from emp where ename = '李磊磊';
ROWNUM EMPNO ENAME
---------- ---------- --------------------
1 1114 李磊磊
比较两个数据集的不同时,通常用类似下面的full join语句
SQL> select v.empno,v.ename,b.empno,b.ename
from v
full join emp b on (b.empno = v.empno)
where (v.empno is null or b.empno is null);
EMPNO ENAME EMPNO ENAME
---------- -------------------- ---------- --------------------
1116 林建国
1110 张三
我们发现这种语句在这个案例中查不到“李磊磊”的区别。
这时我们就要对数据进行处理,增加一列显示相同数据的条数,再进行比较。
SQL> select v.empno,v.ename,v.cnt,emp.empno,emp.ename,emp.cnt
from (select empno,ename,COUNT(*) as cnt from v group by empno,ename) v
full join (select empno,ename,COUNT(*) as cnt from emp group by empno,ename) emp
on (emp.empno = v.empno and emp.cnt = v.cnt)
where (v.empno is null or emp.empno is null);
正确结果如下:
EMPNO ENAME CNT EMPNO ENAME CNT
---------- ----------- ---------- ---------- ----------- ----------
1114 李磊磊 2
1116 林建国 1
1110 张三 1
1114 李磊磊 1
也就是通过员工“李磊磊”的数量不同导致cnt不同从而发现的不同。
10.聚集与内连接
首先建立案例用表如下:
create table emp_bonus (empno INT,received DATE,type INT); insert into emp_bonus values( 1111,date '2016-5-17',1); insert into emp_bonus values( 1112,date '2016-2-15',2); insert into emp_bonus values( 1115,date '2016-2-15',3);
其中
SQL> select * from emp_bonus;
EMPNO RECEIVED TYPE
---------- -------------- ----------
1111 17-5月 -16 1
1112 15-2月 -16 2
1115 15-2月 -16 3
SQL> select e.empno,e.ename,e.sal
from emp e
where e.deptno = 30;
EMPNO ENAME SAL
---------- -------------------- ----------
1111 李四 3400
1112 王五 4400
1115 张少丽 3400
员工的奖金根据TYPE计算,TYPE=1的奖金为员工工资的10%,TYPE=2的奖金为员工工资的20%,TYPE=3的奖金为员工工资的30%。
现在要求返回上述员工(也就是部门30的所有员工)的工资及奖金。
我们首先想到的是使用join语句,先关联,然后对结果做聚集。
那么在做聚集之前,我们先先看一下关联后的结果。
SQL> select e.empno,
e.ename,
e.sal,
(e.sal * case
when eb.type = 1 then 0.1
when eb.type = 2 then 0.2
when eb.type = 3 then 0.3
end) as bonus
from emp e
inner join emp_bonus eb on (e.empno = eb.empno)
where e.deptno = 30
order by 1,2;
EMPNO ENAME SAL BONUS
---------- -------------------- ---------- ----------
1111 李四 3400 340
1112 王五 4400 880
1115 张少丽 3400 1020
对这样的关联结果进行聚集后的数据如下:
SQL> select e.deptno,
SUM(e.sal) as total_sal,
SUM(e.sal * case
when eb.type = 1 then 0.1
when eb.type = 2 then 0.2
when eb.type = 3 then 0.3
end) as total_bonus
from emp e
inner join emp_bonus eb on (e.empno = eb.empno)
where e.deptno = 30
group by e.deptno;
DEPTNO TOTAL_SAL TOTAL_BONUS
---------- ---------- -----------
30 11200 2240
我们核对一下,工资总额和奖金总额都没有问题。
11.聚集与外连接
如果我们要分别返回所有部门的工资及奖金怎么办?因上述奖金数据只含部门30,那么改为left join就可以。
SQL> select e.deptno,
SUM(e.sal) as total_sal,
SUM(e.sal * eb2.rate) as total_bonus
from emp e
left join (select eb.empno,
SUM(case
when eb.type = 1 then 0.1
when eb.type = 2 then 0.2
when eb.type = 3 then 0.3
end) as rate
from emp_bonus eb
group by eb.empno) eb2 on eb2.empno = e.empno
group by e.deptno
order by 1; DEPTNO TOTAL_SAL TOTAL_BONUS
---------- ---------- -----------
20 10900
30 11200 2240
40 6250
50 4600
先做聚集操作,然后外连接。
转载请注明出处:http://blog.csdn.net/acmman/article/details/51062195