论文阅读:A Critical Review of Recurrent Neural Networks for Sequence Learning
作者:
Zachary C. Lipton UCSD
一、论文所解决的问题
现有的关于RNN这一类网络的综述太少了,并且论文之间的符号并不统一,本文就是为了RNN而作的综述
二、论文的内容
(0)整体一览
由前馈神经网络-》RNN的早期历史以及发展-》现代RNN的结构-》现代RNN的应用
(1)前馈神经网络
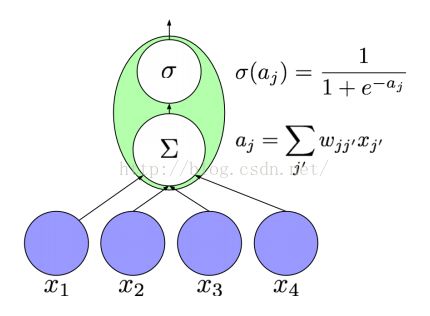
图1 一个神经元

图2 一个神经网络
传统的前馈神经网络虽然能够进行分类和回归,但是这些都是假设数据之间是iid(独立同分布的),因为无法胜任那些数据之间是依赖的序列问题。
如图3中的5中情况分别为:
(a)表示前馈神经网络,固定输入,固定输出
(b)表示序列-》单个输出或者多个固定输出
(c)表示单个输入-》序列的映射
(d)表示序列-》序列的映射(长度不一样)
(e)表示序列-》序列的映射(长度一样)
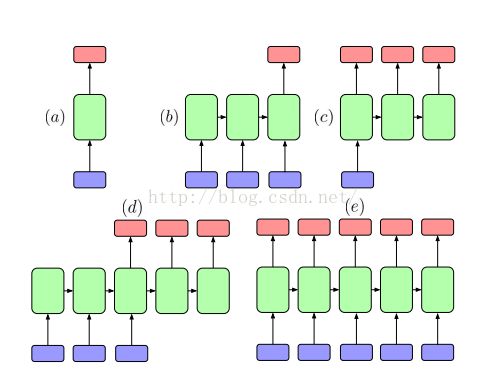
图3 5个不同的应用
以上5个不同的应用分别对应于使用普通的分类或者回归的前馈神经网络、RNN来进行分类或者回归、使用RNN来生成图像的描述 、使用RNN来进行语言翻译、使用RNN来学习对应的映射。
1)前馈神经网络中,常用的激活主要就是Sigmoid、tanh、ReLU了,如果多分类就是接一个softmax,如果回归,就是最后接一个线性输出即可。
ReLU可以给网络的隐藏层引入稀疏性。
此外给定稀疏的输入到带有正则化项的线性模型,虽然发现最终的权重并没有稀疏性,但是却能够很好地运用稀疏稀疏性
2)前馈神经网络的精确计算是NP难问题,只能采用启发式算法来进行优化,最常用的是SGD、然后是SGD的一些变种,主要有AdaDelta、RMSprop、AdaGrad,加入动量能够媲美使用Hessian-Free优化方法进行优化。
AdaGrad,能够自动调整学习率,会使得函数快速到达凸的误差表面(convex error surface),但是学习率确实一直递减的,这在高度非凸的误差表面是不行的。因此RMSprop应运而生,能够改善这个情况。
(2)RNN
①首先需要知道,有很多对序列建模的算法,最著名的应该就是HMM,但是HMM的计算量太大,即使使用动态规划去实现该算法(viterbi算法),在状态过多的时候计算量就指数级增长了,这完全不可行,RNN就有了机会。
②其次RNN与C语言以及其他编程语言之间相比是不是表达能力太强了?答案是RNN是图灵完备的,可以模拟通用图灵机,但是C语言并不存在一个损失函数,并且可以计算损失函数的偏导,来进行优化。所以说,RNN相比C语言有
1)RNN是端到端可导
2)RNN是图灵完备(RNN的特定架构是固定大小的,不会像C语言那样输出任意的程序)
3)RNN可以通过正则化的方法改善过拟合(比如权重衰减、dropout、限制自由度等)
(3)早期的RNN(RNN这类网络的早期发展)
1)最简单的RNN
如图4所示,最简单的RNN就是隐藏层的单元与自己进行连接,并且与同层的隐藏单元进行连接。

图4 最简单的RNN
对应的在时间上的展开如图5
图5 RNN在时间上的展开
发现了什么,在时间上展开后发现隐藏层的单元的连接在下一个时刻与自己进行连接了,并且与下一个时刻的该层的其他单元也进行连接了。
2)Jordan网络和Elman网络(LSTM出现前的铺垫)
Jordan网络和Elman网络的区别就在于究竟在那一层进行Recurrent,Jordan选择了在输出层、而Elman选择了在隐藏层。

图6 Jordan网络

图7 Elman网络
Jordan网络和Elman网络是为LSTM的出现做了铺垫。为啥叫铺垫,因为知道要将隐藏层作为输入了。
3)早期的训练算法
问题1:梯度消失和爆炸
梯度消失和爆照的问题一直困扰着RNN。|W_{jj'}|>1就会梯度爆炸,|W_{jj'}|<1则会梯度消失,W_{jj'}表示从j'到j的连接的权重。
解决方法是:
1)使用Sigmoid会使该问题恶化。使用ReLU可以使得权重不爆炸也不消失。
2)使用Truncated BPTT,能够缓解这一问题(LSTM就是用了BP和TBPTT进行训练的)。
3)LSTM是通过设计好的含有回复式的结点以及固定的权重来解决这个问题的。LSTM论文中叫CEC(恒定误差传送带)
注:LSTM同时用了设定恒定的权重以及TBPTT来缓解梯度爆炸或者消失这个问题并不冲突哈
问题2:容易陷入到局部极值点
有人就研究了,发现在结构较大的网络中,许多关键点是存在于误差表面的,鞍点相对局部极小值点的比例会随着网络的大小的增大而增大。在算法中是可以逃离鞍点的,因此,结构较大的网络不会陷入到局部极值点。
(4)现代RNN网络
主要就是LSTM,BRNNs,NTM(神经图灵机)。
1)LSTM
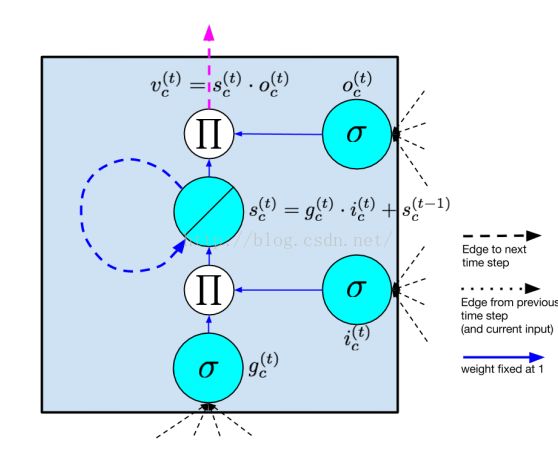
图8 最原始的LSTM结构图
早期的LSTM的cell的输入是用的sigmoid,后来发现用tanh函数更好。
早期的LSTM输出没有使用任何函数直接就是S_c*O_c了,后来使用的tanh函数,这样可以提高动态范围,后来发现用ReLU更好,能够进一步提高动态范围(dynamic range)
LSTM及其变种一般有以下几个部分:
cell的输入:用tanh函数
输入门:用sigmoid函数控制输入
输出门:用sigmoid函数控制输出
遗忘门:用sigmoid函数控制遗忘
cell的输出:用tanh函数或者ReLU函数
此外还有窥视孔,窥视孔是将记忆S_c作为输入门和输出门的输入的一部分。窥视孔的加入可以实现精确的计时。
直觉上的解释就是:假设需要进行精确计时,时间间隔是n,窥视孔可以在输入前n-1个数据之后在第n个数据的时候学习到打开输出门,然后产生激活值,而在前n-1个数据进行输入的时候输入门学习到打开输入门加入到记忆中去。
数学上的描述:
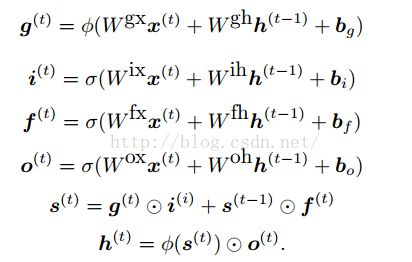
g表示lstm中cell的输入激活
i输入lstm中cell的输入门激活
f表示lstm中cell的遗忘门激活
o表示lstm中cell的输出门激活
s表示记忆,圈圈中带一点的是元素之间的相乘
h是最终的lstm中一个cell的输出
一个lstm可以有若干个cell,然后每个cell的输出h,连接到一个softmax,就可以用LSTM做多分类。
如图9 所示就是LSTM的变种
图9 带有遗忘门、输入门、输出门的LSTM变种
如图10所示为LSTM在时间上的展开,注意其中的recurrent连接(只有cell的output才会作为输入)。
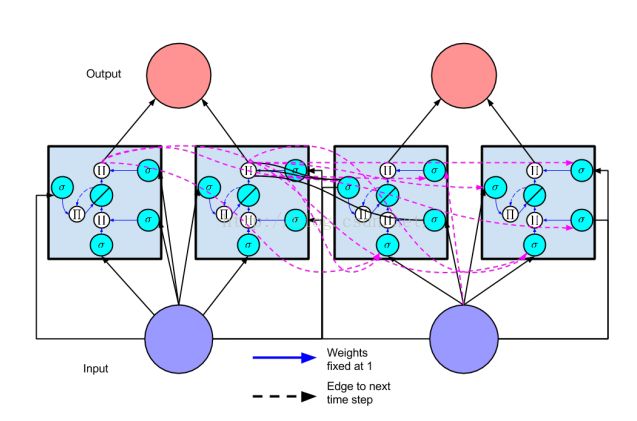
图10 LSTM在时间上的展开
2)BRNNs双向的RNN
首先给出架构图,如图11所示
图11 BRNNs在时间上的展开
对应的公式如下:

发现了什么,回复式的连接,存在与t-1时刻和t+1时刻,也就是通晓古今和未来了。
这在直觉上是并不合理的,因为我们一般不知道未来是什么样子的,但是有一个情况,就是我们在自然语言中作词性标注的时候是需要词的上下文来进行判断的,因此在这种场合,该网络可以很好滴完成任务。
3)其他变种
其实还有双向的LSTM,称为BLSTM。
此外还有通过开关门来模拟LSTM的变种GRU(相当于简化的LSTM)
4)NTM(神经图灵机)
神经图灵机的出现实际上证明了,RNN如果带有外部可以访问的记忆的话,是能够处理较长的依赖问题的。
举个例子:啥叫较长的依赖问题,比如在客服系统中,需要对用户的问题进行回答,客户的问题比较长,有时候会非常长,如果超过一个极限,普通的LSTM根本无法胜任,所以就出现了如何使用外部记忆的研究,早期的典型就是NTM,其次就是Momeory Network,然后就是End To End Memory Network。
(5)现代RNN的应用
最广泛的就是自然语言上的应用,毕竟自然语言是序列嘛。
为了处理自然语言,最开始的问题就是一个句子或者一个单词或者一个字母如何表示的问题。
1)自然语言的输入和输出的表示
①一般用神经网络学习到一个word embeding(单词的表示)
②用word2vec(单词的表示)
③用GloVe(单词的表示)
④用one of k coding shcema(特别适用于字母的表示)
⑤用BOW(句子的表示,在Memory Network那篇论文就是这样表示句子的)
2)评价指标
语言学建模,就是给定前n个单词,预测n+1个单词是啥
①用BLUE

②MENTOR
首先需要计算F-Score

最终总结一下:
整体感受就是RNN的外部记忆能够处理较长的依赖关系这一点已经被不少人抓住做了。LSTM还是存在一定的局限性的,比如长时间依赖并没有很长,双向RNN在某些特定的场合会比较有用,但是并没有非常火。