Lucene分词对象
一、Analyzer类
Analyzer是一个抽象类,我们可以理解为Lucene分析器的基类。
分析器使用分词器和过滤器构成一个“管道”,文本在流经这个管道后成为可以进入索引的最小单位。因此,一个标准的分析器有两个部分组成.。
一个是分词器Tokenizer,另外一个是TokenFilter。
为了便于观察不同的分词器对文本的分词效果,我们首先有个公共的方法来打印出每个分词器对象接收到文本进行分词后的效果。
/**
*
* @author tanjie 创建时间: 2015-11-4 上午9:56:45
描述: 不同的分词器对象处理相同的文本后的处理效果
* @param str 传入的测试字符串
* @param anlyzer 分词器对象
*/
public static void displayToken(String str, Analyzer anlyzer) {
TokenStream tokenStream = null;
try {
//tokenStream 是从文本的域中或者是查询条件中抽取出来的一个个分词组成的数据流
tokenStream = anlyzer.tokenStream("", new StringReader(str));
CharTermAttribute cta = tokenStream
.addAttribute(CharTermAttribute.class);
//调用reset()方法,设置tokenStream的状态
tokenStream.reset();
//调用incrementToken()方法,来获取下一个分词
while (tokenStream.incrementToken()) {
System.out.print("[" + cta + "]");
}
System.out.println();
//调用end()方法来完成一些收尾工作
tokenStream.end();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (null != tokenStream) {
try {
tokenStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
二、Lucene常用分词器介绍
Lucene的分词器有很多,这里只介绍常用的分词器。
-
StandardAnalyzer:StandardAnalyzer标准分词器,是Lucene内置的分词器,它会将所有的语汇词都转为小写,并去除所有的停顿词和相应的标点符号,很明显,标准分词器不适合中文分词。
-
StopAnalyzer:StopAnalyzer是停顿词分词器,停顿词分析器会去除一些常有a,the,an等无关紧要的词。
-
SimpleAnalyzer:SimpleAnalyzer分词器是以非字母符来分割文本信息,并将语汇单元统一为小写形式,并去掉数字类型的字符,很明显也不适用于中文环境。
-
WhitespaceAnalyzer:WhitespaceAnalyzer是空格分词器,它以空格作为切词的标准,不对语汇单元进行其它规范化的处理。
下面,我们来写一个测试类,传入不同的分词器对象处理相同的文本,看下它们有什么不同。
@Test
public void testAnalyzer() {
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_4_9);
Analyzer analyzer2 = new StopAnalyzer(Version.LUCENE_4_9);
Analyzer analyzer3 = new SimpleAnalyzer(Version.LUCENE_4_9);
Analyzer analyzer4 = new WhitespaceAnalyzer(Version.LUCENE_4_9);
String content= "I am from chongqing,My name is zhangsan,I am age is 18 haha";
//调用上面的方法
AnalyzerUtils.displayToken(content, analyzer);
AnalyzerUtils.displayToken(content, analyzer2);
AnalyzerUtils.displayToken(content, analyzer3);
AnalyzerUtils.displayToken(content, analyzer4);
}
执行该测试方法,运行结果如下,可以看到不同的分词器,对相同的文本处理结果不一样。
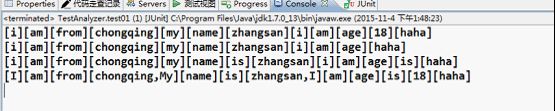
三、Lucene的中文分词器
Lucene支持的中文分词器有很多,但是目前活跃度最高且用的最多的中文分词器是IKAnalyzer。
下面来看效果:
先在本地建几个txt,随意输入几个中文,读取指定目录txt文件里面的内容,建立相应的索引,将索引放在本地文件中。
public class testChineseIk{
// 本地文件,每个文件存储不同的中文
private static final String INDEX_DATA = "E:\\luceneData";
// 索引的文件的存放路径
private static final String INDEX_DIR = "E:\\luceneIndex";
@Test
public void testIndex() throws Exception {
// 索引文件的保存位置
Directory dir = FSDirectory.open(new File(INDEX_DIR));
// 分析器
Analyzer analyzer = new IKAnalyzer();
// 配置类
IndexWriterConfig iwc = new IndexWriterConfig(Version.LUCENE_4_9,analyzer);
iwc.setOpenMode(OpenMode.CREATE_OR_APPEND);
IndexWriter indexWriter = new IndexWriter(dir, iwc);
long start = System.currentTimeMillis();
File file = new File(INDEX_DATA);
if (file.listFiles().length > 0) {
for (int i = 0; i < file.listFiles().length; i++){
File f = file.listFiles()[i];
Document doc = new Document();
Field nameField = new TextField("name", f.getName(),Field.Store.YES);
Field pathField = new TextField("path", f.getAbsolutePath(),Field.Store.YES);
Field contenField = new TextField("content",LuceneUtils.txt2String(f),Field.Store.YES);
doc.add(nameField);
doc.add(contenField);
doc.add(pathField);
indexWriter.addDocument(doc);
indexWriter.commit();
}
}
long end = System.currentTimeMillis();
System.out.println("建立索引用时" + (end - start) + "毫秒");
}
}
在执行上面的代码之后,通过工具Luke(Luck是一个可执行的jar包),我们可以看到索引内容
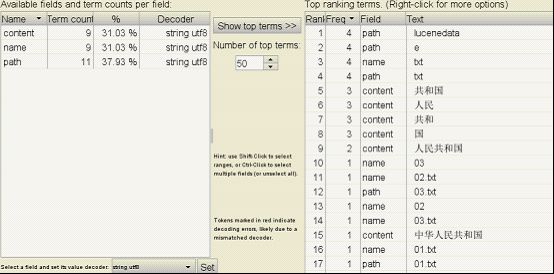
可以发现,域(Field)包含中文字‘共和国’的有3个结果,写测试类来执行中文搜索
@Test
public void testChineseQuery() throws Exception {
long start = System.currentTimeMillis();
LuceneIKSearch luceneIKIndex = new LuceneIKSearch(INDEX_DIR);
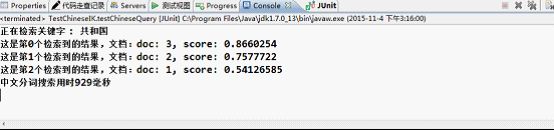
TopDocs topDocs = luceneIKIndex.search("共和国");
luceneIKIndex.printResult(topDocs);
long end = System.currentTimeMillis();
System.out.println("中文分词搜索用时" + (end - start) + "毫秒");
}
四、总结
Lucene的分词很强大,但是在实际开发中,往往是我们自己根据不同的业务场景来自定义分词的实现方式。比如,在100G的文档里面,我们需要搜索 ‘北京’,而北京和大陆,首都的意思差不多,就好像同义词一样,我们就可以自定义分词的实现方式,来同时搜索出包含这些内容的文本。