关于hadoop2.x(2.7.1 2.7.2)集群配置和测试运行中Ubuntu虚拟机VM设置nat方式导致节点传输问题
集群配置都大同小异,在这里我简单说下我的配置:
主节点系统是Ubuntu 14.04 LTS x64其他两个节点在VM中系统为Centos 6.4 x64
JVM为jdk1.7_80
hadoop版本2.7.1和2.7.2都尝试了
出现的问题是:
启动hdfs系统正常,都启动起来了,jps查看如下
主节点 SecondaryNameNode和 NameNode
从节点:DataNode
但使用hfds命令dfsadmin -report发现live的datanode只有1个,而且当你不同时间report,这个存活的节点是交替改变的,一会是datanode1,一会是datanode2
如下
hadoop@hadoop:modules$ hdfs dfsadmin -report Configured Capacity: 16488800256 (15.36 GB) Present Capacity: 13008093184 (12.11 GB) DFS Remaining: 13008068608 (12.11 GB) DFS Used: 24576 (24 KB) DFS Used%: 0.00% Under replicated blocks: 0 Blocks with corrupt replicas: 0 Missing blocks: 0 Missing blocks (with replication factor 1): 0 ------------------------------------------------- Live datanodes (1): Name: 192.168.2.3:50010 (hadoop) Hostname: hadoop1 Decommission Status : Normal Configured Capacity: 16488800256 (15.36 GB) DFS Used: 24576 (24 KB) Non DFS Used: 3480969216 (3.24 GB) DFS Remaining: 13007806464 (12.11 GB) DFS Used%: 0.00% DFS Remaining%: 78.89% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 1 Last contact: Mon May 09 17:30:08 CST 2016
再次report
hadoop@hadoop:modules$ hdfs dfsadmin -report Configured Capacity: 16488800256 (15.36 GB) Present Capacity: 13008007168 (12.11 GB) DFS Remaining: 13007982592 (12.11 GB) DFS Used: 24576 (24 KB) DFS Used%: 0.00% Under replicated blocks: 0 Blocks with corrupt replicas: 0 Missing blocks: 0 Missing blocks (with replication factor 1): 0 ------------------------------------------------- Live datanodes (1): Name: 192.168.2.3:50010 (hadoop) Hostname: hadoop2 Decommission Status : Normal Configured Capacity: 16488800256 (15.36 GB) DFS Used: 24576 (24 KB) Non DFS Used: 3480793088 (3.24 GB) DFS Remaining: 13007982592 (12.11 GB) DFS Used%: 0.00% DFS Remaining%: 78.89% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 1 Last contact: Mon May 09 17:34:06 CST 2016
奇怪了..同时,通过web ui 50070查看datanode存活的节点时候,只能有1个.而且当你刷新页面,这个存活的节点是变化的,同上
一开始我没这样看,我是通过dfs -mkdir /test,然后put文件,出现IO传输异常..主要异常内容如下
<pre name="code" class="html">hdfs.DFSClient: org.apache.hadoop.ipc.RemoteException: Java.io.IOException:could only be replicated to 0 nodes, instead of 1
我就纳闷了,先是检验每个机器的防火墙,Selinux,然后互ping,然后ssh连接测试都没有问题..
一切都正常啊,为何会报传输异常...
截取一部分日志如下;
2016-05-10 01:29:54,148 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Block pool Block pool BP-1877985316-192.168.2.3-1462786104060 (Datanode Uuid c31e3853-b15e-46d8-abd0-ac1d1ed4572b) service to hadoop/192.168.2.3:9000 successfully registered with NN 2016-05-10 01:29:54,151 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Successfully sent block report 0x44419c23fe, containing 1 storage report(s), of which we sent 1. The reports had 0 total blocks and used 1 RPC(s). This took 0 msec to generate and 2 msecs for RPC and NN processing. Got back one command: FinalizeCommand/5. 2016-05-10 01:29:54,152 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Got finalize command for block pool BP-1877985316-192.168.2.3-1462786104060 2016-05-10 01:29:57,150 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: DatanodeCommand action : DNA_REGISTER from hadoop/192.168.2.3:9000 with active state 2016-05-10 01:29:57,153 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Block pool BP-1877985316-192.168.2.3-1462786104060 (Datanode Uuid c31e3853-b15e-46d8-abd0-ac1d1ed4572b) service to hadoop/192.168.2.3:9000 beginning handshake with NN
这段日志一直在重复,每2-3秒重复一次,另一个节点也是.
另外我查看了虚拟机右下角的网络传输信号灯,也是基本没隔1秒闪一下,说明每一秒主节点和从节点进行了一次ssh交互,起初没在意..以为是心跳..
其实如果是正常情况下,只有每一次ssh 提出一个requets的时候,才会闪烁一下,我是这么理解的
然后查阅官方文档,参考其他网上资源和问题,都试了都不行...纳闷死了..
小修改了一些自己的配置文件,但只要基本的东西配置的没错,小改动的都是没多大关系的.这个是我配置的文件:
core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/modules/hadoop-2.7.2/data/tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
</configuration>hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/modules/hadoop-2.7.2/data/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/modules/hadoop-2.7.2/data/dfs/data</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
这里只关系到hdfs文件系统,所以mapred-site.xml和yarh-sitexml在这里就不累述了.
经过无数次的namnode format和删除data, /tmp目录下的文件,都无济于事,后来我开始怀疑是hadoop版本问题,试了试从一开始hadoop2.7.1改为2.7.2,还一样,然后开始怀疑Ubuntu的问题..我接着转到我Win7系统上,在虚拟机里运行三个节点,上传一个文件成功,十分顺利啊,,我就纳闷了..这是unbutu哪里的问题,,,
说来说去都是关系这节点ssh传输问题..我就开始想会不会是虚拟机的网络问题..我就换了几个DNS,从VM中Net适配器在Ubuntu中的ip xx.xx.xx.1换到我Ubunt接入外网的路由器ip,xx.xx.xx.1,都没啥问题啊,各个节点ping自己,网关,互ping和外网,都很顺..说明不是这里的问题..
最后一个尝试了.这里我设的是VM Net链接方式...改成桥接模式..配置一个外网的DNS,,.然后重新format Namenode,启动hdfs...检查Datanode报告,上传文件测试,,,一切顺利..终于改成功了..
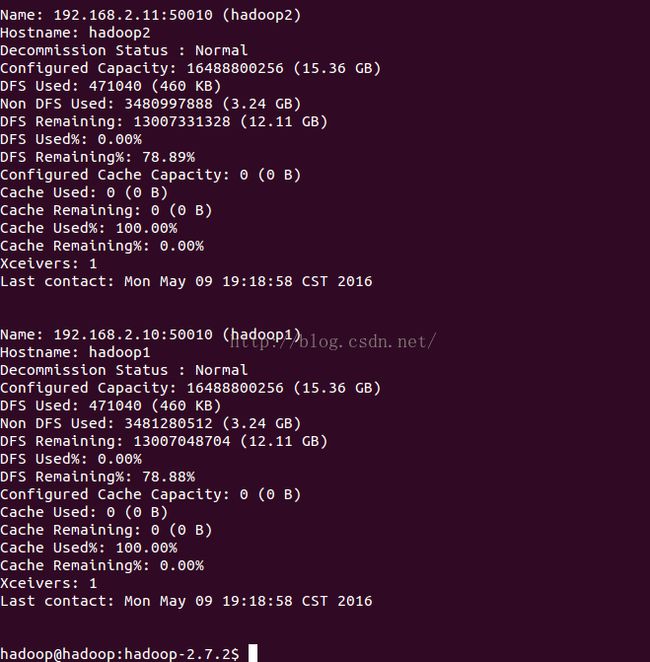
put一个文件
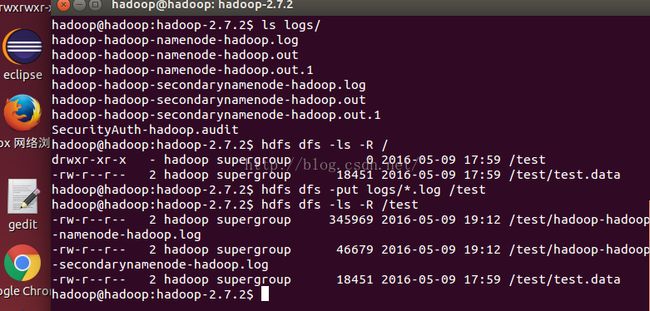
web ui查看,存活的两个节点都显示出来了,不会跟之一样只出现一个..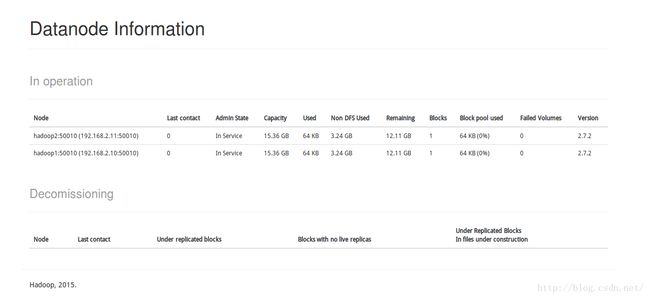
个人总结;
启动hdfs文件系统,启动节点启动正常,但是datanode个数不正常,put文件时报IO错.
无外乎
1配置的slave或者hdfs-site.xml有问题
2ssh传输有问题..
3 网络传输比如网关,DNS,ip配置,hosts文件出现了问题..
4 以上都设置正常,在换一种方式测试链接.比如改变虚拟机的Net或者桥接方式,
要从这里着手,像这种比较少见的问题,只能自己一个个试着调了..
关于Ubuntu下的Vm虚拟机Net方式连接为何会导致这种单线传输的问题,我也不是很了解..希望了解的补充以下..
毕竟只有hadoop传输有问题,其他的比如虚拟机中ping,联网,传文件,ssh访问之类的,都很顺利