推荐几款优秀的开源数据挖掘工具
IDMer:本文只对几种流行的开源数据挖掘平台进行了检视,比如Weka和R等。如果您想找寻更多的开源数据挖掘软件,可以到KDnuggets和Open Directory上查看。为了评测这些软件,我们用了UCI Machine Learning Repository上的心脏病诊断数据集。
R
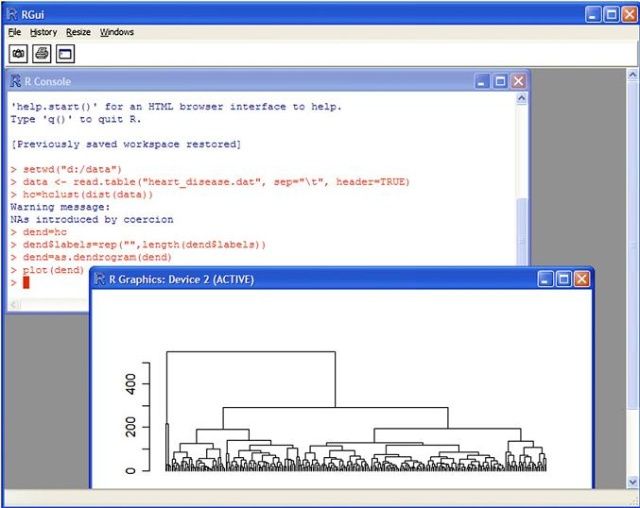
R (http://www.r-project.org) 是用于统计分析和图形化的计算机语言及分析工具,为了保证性能, 其核心计算模块是用C、C++和Fortran编写的。同时为了便于使用,它提供了一种脚本语言,即R语言。R语言和贝尔实验室开发的S语言类似。R支持 一系列分析技术,包括统计检验、预测建模、数据可视化等等。在CRAN(http://cran.r-project.org) 上可以找到众多开源的扩展包。
R软件的首选界面是命令行界面,通过编写脚本来调用分析功能。如果缺乏编程技能,也可使用图形界面,比如使用R Commander(http://socserv.mcmaster.ca/jfox/Misc/Rcmdr/)或Rattle(http://rattle.togaware.com)。
Tanagra
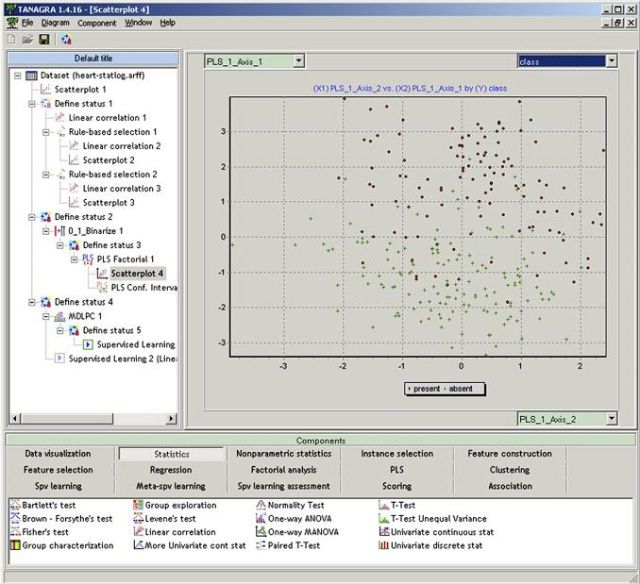
Tanagra (http://eric.univ-lyon2.fr/wricco/tanagra/) 是使用图形界面的数据挖掘软件,采用了类似Windows资源管理器中的树状结构来组织分析组件。Tanagra缺乏高级的可视化能力,但它的强项是统计 分析,提供了众多的有参和无参检验方法。同时它的特征选取方法也很多。
Weka
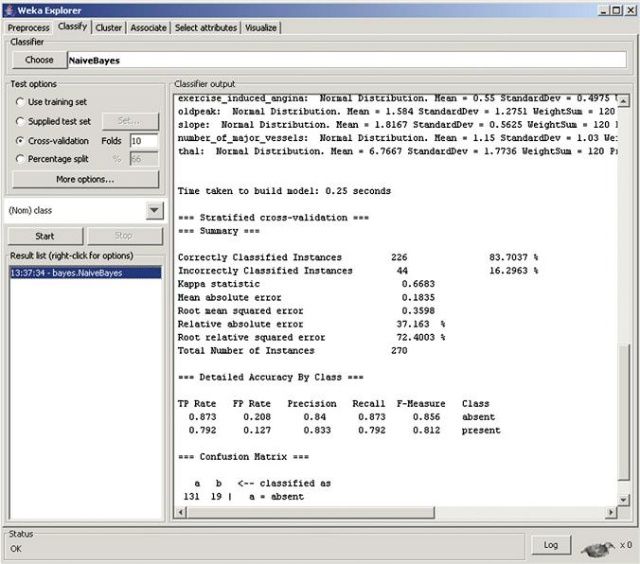
Weka (Waikato Environment for Knowledge Analysis, http://www.cs.waikato.ac.nz/ml/weka/) 可能是名气最大的开源机器学习和数据挖掘软件。高级用户可以通过Java编程和命令行来调用其分析组件。同时,Weka也为普通用户提供了图形化界面,称 为Weka KnowledgeFlow Environment和Weka Explorer。和R相比,Weka在统计分析方面较弱,但在机器学习方面要强得多。在Weka论坛 (http://weka.sourceforge.net/wiki/index.php/Related_Projects) 可以找到很多扩展包,比如文本挖掘、可视化、网格计算等等。很多其它开源数据挖掘软件也支持调用Weka的分析功能。

YALE (IDMer:现在已经更名为RapidMiner)
YALE (Yet Another Learning Environment, http://rapid-i.com) 提供了图形化界面,采用了类似Windows资源管理器中的树状结构来组织分析组件,树上每个节点表示不同的运算符(operator)。YALE中提供 了大量的运算符,包括数据处理、变换、探索、建模、评估等各个环节。YALE是用Java开发的,基于Weka来构建,也就是说它可以调用Weka中的各 种分析组件。

KNIME
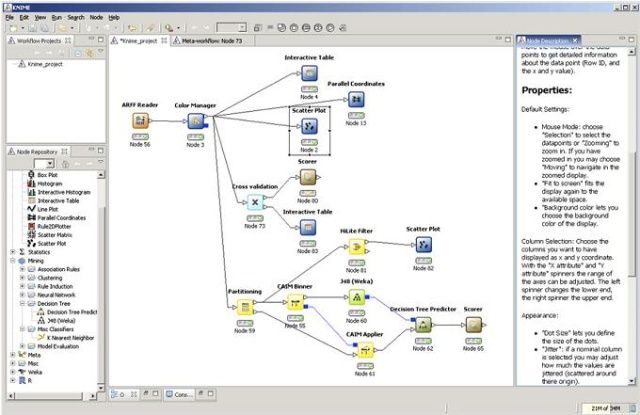
KNIME (Konstanz InformationMiner, http://www.knime.org)是基于Eclipse开发环境来精心开发的数据挖掘工具。无需安装,方便使用(IDMer:呵呵,大家喜欢的绿色版)。和YALE一样,KNIME也是用Java开发的,可以扩展使用Weka中的挖掘算法。和YALE不同点的是,KNIME采用的是类似数据流(data flow)的方式来建立分析挖掘流程(IDMer:这个我喜欢,和SAS EM或SPSS Clementine等商用数据挖掘软件的操作方式类似)。挖掘流程由一系列功能节点(node)组成,每个节点有输入/输出端口(port),用于接收数据或模型、导出结果。(IDMer:感觉KNIME比Weka的KnowledgeFlow更好用,连接节点时很方便,直接用鼠标拖拽连接端口即可。而Weka中则需要在节点上按鼠标右键,再选择后续节点,比较麻烦,刚开始使用时找了半天才知道怎么连)
KNIME中每个节点都带有交通信号灯,用于指示该节点的状态(未连接、未配置、缺乏输入数据时为红灯;准备执行为黄灯;执行完毕后为绿灯)。在KNIME中有个特色功能——HiLite,允许用户在节点结果中标记感兴趣的记录,并进一步展开后续探索。

Orange
Orange (http://www.ailab.si/orange)是类似KNIME和Weka KnowledgeFlow的数据挖掘工具,它的图形环境称为Orange画布(OrangeCanvas),用户可以在画布上放置分析控件 (widget),然后把控件连接起来即可组成挖掘流程。这里的控件和KNIME中的节点是类似的概念。每个控件执行特定的功能,但与KNIME中的节点 不同,KNIME节点的输入输出分为两种类型(模型和数据),而Orange的控件间可以传递多种不同的信号,比如learners, classifiers, evaluation results, distance matrices, dendrograms等等。Orange的控件不象KNIME的节点分得那么细,也就是说要完成同样的分析挖掘任务,在Orange里使用的控件数量可 以比KNIME中的节点数少一些。Orange的好处是使用更简单一些,但缺点是控制能力要比KNIME弱。
除了界面友好易于使用的优点,Orange的强项在于提供了大量可视化方法,可以对数据和模型进行多种图形化展示,并能智能搜索合适的可视化形式,支持对数据的交互式探索。
Orange的弱项在于传统统计分析能力不强,不支持统计检验,报表能力也有限。Orange的底层核心也是采用C++编写,同时允许用户使用Python脚本语言来进行扩展开发(参见http://www.scipy.org)。


GGobi
数据可视化是数据挖掘的重要组成部分, GGobi (http://www.ggobi.org)就是用于交互式可视化的开源软件,它使用brushing的方法。GGobi可以用作R软件的插件,或者通过Perl、Python等脚本语言来调用。

结论
----
以 上介绍的几款软件都是优秀的开源数据挖掘软件,各有所长,同时也各有缺点。读者可以结合自己的需求来进行选择,或者组合使用多个软件。对于普通用户可以选 用界面友好易于使用的软件,对于希望从事算法开发的用户则可以根据软件开发工具不同(Java、R、C++、Python等)来选择相应的软件。以上这几 款软件(除了GGobi)基本上都提供了我们期望的大部分功能。
(IDMer:我尝试了以上这几种 开源软件,Weka很有名但用起来并不方便,界面也简单了点;RapidMiner现在流行的势头在上升,但它的操作方式和商用软件差别较大,不支持分析 流程图的方式,当包含的运算符比较多的时候就不容易查看了;KNIME和Orange看起来都不错,Orange界面看上去很清爽,但我发现它不支持中 文。我的推荐是KNIME,同时安装Weka和R扩展包。)
(IDMer:我的点评纯属个人意见,欢迎大家批评交流。在我的实际工作中使用开源挖掘工具并不多,大部分时候都是在使用SAS Enterprise Miner。)
来自: idmer.blog.sohu.com