hive存储格式
hive文件的存储格式:textfile、sequencefile、rcfile、自定义格式
1. textfile
textfile,即是文本格式,默认格式,数据不做压缩,磁盘开销大,数据解析开销大
对应hive API为org.apache.hadoop.mapred.TextInputFormat和org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat。
2.sequencefile
sequencefile,是Hadoop提供的一种二进制文件格式是Hadoop支持的标准文件格式(其他生态系统并不适用),
可以直接将对序列化到文件中,所以sequencefile文件不能直接查看,可以通过Hadoop fs -text查看。
具有使用方便,可分割,可压缩,可进行切片。压缩支持NONE, RECORD, BLOCK(优先)等格式,可进行切片。
对应hive API为org.apache.hadoop.mapred.SequenceFileInputFormat和org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat。

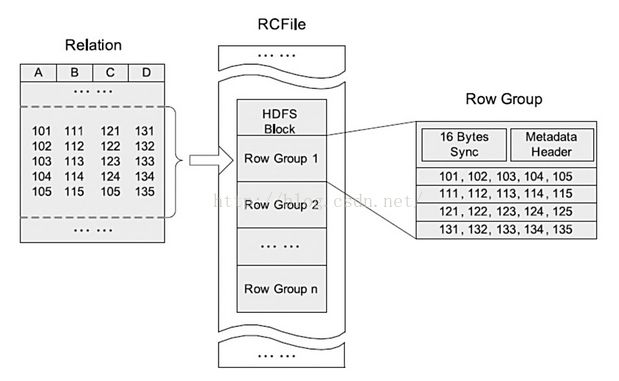
3.rcfile
大多数的Hadoop和hive存储是行式储存,在大多数环境下比较高效,因为大多数表具有的字段个数都不会很大,
且文件按块压缩对于需要处理重复数据的情况比较高效,同时处理和调试工具(more、head、awk)都能很好的适应行式存储的数据。
但当需要操作的表有成百上千个字段,而操作只有一小部分字段时,这往往会造成很大的浪费。
而此时若是采取列式存储只操作需要的列便可以大大提高性能。
rcfile 是一种行列存储相结合的存储方式,先将数据按行分块再按列式存储,保证同一条记录在一个块上,避免读取多个块,
有利于数据压缩和快速进行列存储。
对应hive API为org.apache.hadoop.hive.ql.io.RCFileInputFormat和org.apache.hadoop.hive.ql.io.RCFileOutputFormat。
行存储
基于Hadoop系统行存储结构的优点在于快速数据加载和动态负载的高适应能力,这是因为行存储保证了相同记录的所有域
都在同一个集群节点,即同一个HDFS块。不过,行存储的缺点也是显而易见的,它不能支持快速查询处理,
因为当查询仅仅针对多列表中的少数几列时,它不能跳过不必要的列读取;此外由于混合着不同数据值的列,
行存储不易获得极高的压缩比,即空间利用率不易大幅提高。尽管通过熵编码和利用列相关性能够获得一个较好的压缩比,
但是复杂数据存储实现会导致解压开销增大。
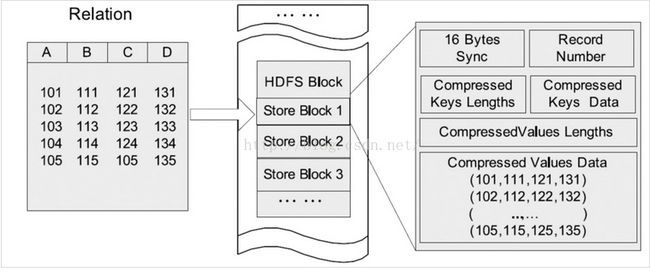
下图显示了在HDFS上按照列组存储表格的例子。在图中,列A和列B存储在同一列组,而列C和列D分别存储在单独的列组。
查询时列存储能够避免读不 必要的列,并且压缩一个列中的相似数据能够达到较高的压缩比。然而由于元组重构的较高开销,
它并不能提供基于Hadoop系统的快速查询处理。列存储不 能保证同一记录的所有域都存储在同一集群节点,
记录的4个域存储在位于不同节点的3个HDFS块中。因此,记录的重构将导致通过集群节 点网络的大量数据传输。
尽管预先分组后,多个列在一起能够减少开销,但是对于高度动态的负载模式,它并不具备很好的适应性。
除非所有列组根据可能的查询预 先创建,否则对于一个查询需要一个不可预知的列组合,一个记录的重构或许需要2个或
多个列组。再者由于多个组之间的列交叠,列组可能会创建多余的列数据存 储,这导致存储利用率的降低。
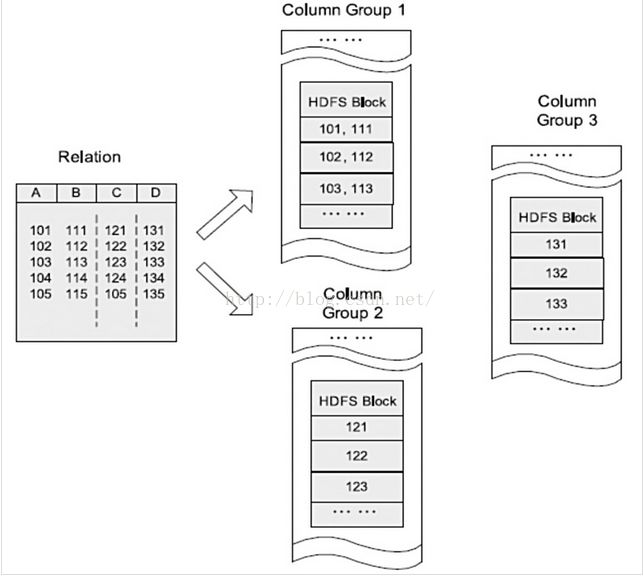
下图是一个 HDFS块内RCFile方式存储的例子。RCFile(Record Columnar File)存储结构遵循的是“先水平划分,
再垂直划分”的设计理念,它结合了行存储和列存储的优点:首先,RCFile保证同一行 的数据位于同一节点,
因此元组重构的开销很低;其次,像列存储一样,RCFile能够利用列维度的数据压缩,并且能跳过不必要的列读取。
四.ORCfile
orcfile是对rcfile的优化,可以提高hive的读、写、数据处理性能,提供更高的压缩效率。和RCFile格式相比,
ORC File格式有以下优点:
(1)、每个task只输出单个文件,这样可以减少NameNode的负载;
(2)、支持各种复杂的数据类型,比如: datetime, decimal, 以及一些复杂类型(struct, list, map, and union);
(3)、在文件中存储了一些轻量级的索引数据;
(4)、基于数据类型的块模式压缩:
1).integer类型的列用行程长度编码(run-length encoding);
2).String类型的列用字典编码(dictionaryencoding);
(5)、用多个互相独立的RecordReaders并行读相同的文件;
(6)、无需扫描markers就可以分割文件;
(7)、绑定读写所需要的内存;
(8)、metadata的存储是用 Protocol Buffers的,所以它支持添加和删除一些列。
ORCFile文件结构
ORC File包含一组组的行数据,称为stripes,除此之外,ORCFile的file footer还包含一些额外的辅助信息。
在ORC File文件的最后,
有一个被称为postscript的区,它主要是用来存储压缩参数及压缩页脚的大小。
在默认情况下,一个stripe的大小为250MB。大尺寸的stripes使得从HDFS读数据更高效。
在file footer里面包含了该ORC File文件中stripes的信息,每个stripe中有多少行,以及每列的数据类型。
当然,它里面还包含了列级别的一些聚合的结果,比 如:count, min, max, and sum。下图显示出可ORC File文件结构:
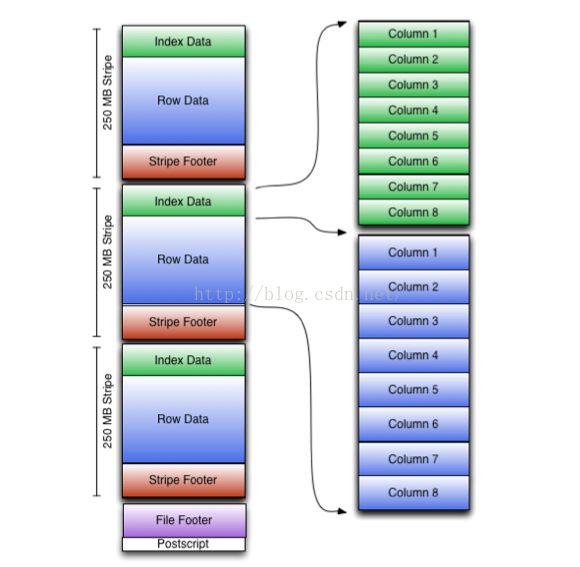
Stripe结构
从上图我们可以看出,每个Stripe都包含index data、rowdata以及stripe footer。Stripefooter包含流位置的目录;
Row data在表扫描的时候会用到。Index data包含每列的最大和最小值以及每列所在的行。行索引里面提供了偏移量,
它可以跳到正确的压缩块位置。具有相对频繁的行索引,使得在stripe中快 速读取的过程中可以跳过很多行,
尽管这个stripe的大小很大。
在默认情况下,最大可以跳过10000行。拥有通过过滤谓词而跳过大量的行的能力,你可 以在表的 secondarykeys 进行排序,
从而可以大幅减少执行时间。比如你的表的主分区是交易日期,那么你可以对次分区(state、zip code以及last name)
进行排序。
五.自定义格式
若当前数据文件格式不能被当前hive所识别时,可以自定义文件格式,
用户可通过实现InputFormat和OutputFormat来自定义输入输出格式。
六.总结
textfile 存储空间消耗比较大,并且压缩的text 无法分割和合并 查询的效率最低,可以直接存储,加载数据的速度最高
sequencefile 存储空间消耗最大,压缩的文件可以分割和合并 查询效率高,需要通过text文件转化来加载
orcfile, rcfile存储空间最小,查询的效率最高 ,需要通过text文件转化来加载,加载的速度最低.
orcfile, rcfile较有优势,orcfile,rcfile具备相当于行存储的数据加载和负载适应能力,扫描表时避免不必要的列读取,
拥有比其他结构更好的性能,而使用列维度的压缩,能有效提升存储空间利用率。
但orcfile, rcfile数据加载是性能损失较大,但由于hdfs一次写入多次读写,所以损失可以接受。
SequenceFile,ORCFile(ORC),rcfile格式的表不能直接从本地文件导入数据,数据要先导入到textfile格式的表中,
然后再从textfile表中导入到SequenceFile,ORCFile(ORC),rcfile表中。