大数据 IMF传奇 如何搭建 8台设备的SPARK分布式 集群
1.下载spark-1.6.0-bin-hadoop2.6.tgz
2.解压
root@master:/usr/local/setup_tools# tar -zxvf spark-1.6.0-bin-hadoop2.6.tgz
3.配置Spark的全局环境变量
输入# vi /etc/profile打开profile文件,按i可以进入文本输入模式,在profile文件的增加SPARK_HOME及修改PATH的环境变量
export SPARK_HOME=/usr/local/spark-1.6.0-bin-hadoop2.6
export
PATH=.:$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$SCALA_HOME/bin:$SPARK_HOME/bin
4.source /etc/profile
5.
root@master:/usr/local/spark-1.6.0-bin-hadoop2.6# cd /usr/local/spark-1.6.0-bin-hadoop2.6/conf
root@master:/usr/local/spark-1.6.0-bin-hadoop2.6/conf# ls
docker.properties.template log4j.properties.template slaves.template spark-env.sh.template
fairscheduler.xml.template metrics.properties.template spark-defaults.conf.template
root@master:/usr/local/spark-1.6.0-bin-hadoop2.6/conf#
6.
配置 spark-env.sh
root@master:/usr/local/spark-1.6.0-bin-hadoop2.6/conf# mv spark-env.sh.template spark-env.sh
export SCALA_HOME=/usr/local/scala-2.10.4
export JAVA_HOME=/usr/local/jdk1.8.0_60
export SPARK_MASTER_IP=192.168.189.1
export SPARK_WORKER_MEMORY=2g
export HADOOP_CONF_DIR=/usr/local/hadoop-2.6.0/etc/hadoop
7.配置slaves
# mv slaves.template slaves
worker1
worker2
worker3
worker4
worker5
worker6
worker7
worker8
8.分发配置
root@master:/usr/local/setup_scripts# vi spark_scp.sh
#!/bin/sh
for i in 2 3 4 5 6 7 8 9
do
scp -rq /etc/profile [email protected].$i:/etc/profile
ssh [email protected].$i source /etc/profile
scp -rq /usr/local/spark-1.6.0-bin-hadoop2.6 [email protected].$i:/usr/local/spark-1.6.0-bin-hadoop2.6
done
root@master:/usr/local/setup_scripts# chmod u+x spark_scp.sh
root@master:/usr/local/setup_scripts# ./spark_scp.sh
9.启动spark集群
root@master:/usr/local/hadoop-2.6.0/sbin# cd /usr/local/spark-1.6.0-bin-hadoop2.6/sbin
root@master:/usr/local/spark-1.6.0-bin-hadoop2.6/sbin# start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /usr/local/spark-1.6.0-bin-hadoop2.6/logs/spark-root-org.apache.spark.deploy.master.Master-1-master.out
worker5: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark-1.6.0-bin-hadoop2.6/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-worker5.out
worker4: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark-1.6.0-bin-hadoop2.6/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-worker4.out
worker7: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark-1.6.0-bin-hadoop2.6/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-worker7.out
worker2: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark-1.6.0-bin-hadoop2.6/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-worker2.out
worker1: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark-1.6.0-bin-hadoop2.6/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-worker1.out
worker6: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark-1.6.0-bin-hadoop2.6/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-worker6.out
worker3: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark-1.6.0-bin-hadoop2.6/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-worker3.out
worker8: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark-1.6.0-bin-hadoop2.6/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-worker8.out
root@master:/usr/local/spark-1.6.0-bin-hadoop2.6/sbin# jps
5378 NameNode
5608 SecondaryNameNode
7260 Jps
7181 Master
5742 ResourceManager
root@master:/usr/local/spark-1.6.0-bin-hadoop2.6/sbin#
root@worker3:~/.ssh# jps
4152 Worker
3994 NodeManager
4202 Jps
3262 DataNode
root@worker3:~/.ssh#
root@worker6:/usr/local# jps
3809 NodeManager
4017 Jps
3077 DataNode
3966 Worker
root@worker6:/usr/local#
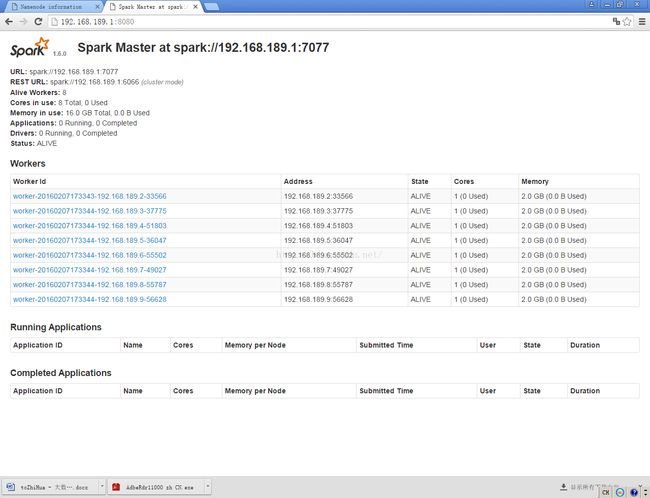
10.web查看 ok
http://192.168.189.1:8080/
1.6.0 Spark Master at spark://192.168.189.1:7077
URL: spark://192.168.189.1:7077
REST URL: spark://192.168.189.1:6066 (cluster mode)
Alive Workers: 8
Cores in use: 8 Total, 0 Used
Memory in use: 16.0 GB Total, 0.0 B Used
Applications: 0 Running, 0 Completed
Drivers: 0 Running, 0 Completed
Status: ALIVE
Workers
Worker Id Address State Cores Memory
worker-20160207173343-192.168.189.2-33566 192.168.189.2:33566 ALIVE 1 (0 Used) 2.0 GB (0.0 B Used)
worker-20160207173344-192.168.189.3-37775 192.168.189.3:37775 ALIVE 1 (0 Used) 2.0 GB (0.0 B Used)
worker-20160207173344-192.168.189.4-51803 192.168.189.4:51803 ALIVE 1 (0 Used) 2.0 GB (0.0 B Used)
worker-20160207173344-192.168.189.5-36047 192.168.189.5:36047 ALIVE 1 (0 Used) 2.0 GB (0.0 B Used)
worker-20160207173344-192.168.189.6-55502 192.168.189.6:55502 ALIVE 1 (0 Used) 2.0 GB (0.0 B Used)
worker-20160207173344-192.168.189.7-49027 192.168.189.7:49027 ALIVE 1 (0 Used) 2.0 GB (0.0 B Used)
worker-20160207173344-192.168.189.8-55787 192.168.189.8:55787 ALIVE 1 (0 Used) 2.0 GB (0.0 B Used)
worker-20160207173344-192.168.189.9-56628 192.168.189.9:56628 ALIVE 1 (0 Used) 2.0 GB (0.0 B Used)
11 spark-shell
root@master:/usr/local/spark-1.6.0-bin-hadoop2.6/sbin# spark-shell
16/02/07 17:36:35 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
16/02/07 17:36:35 INFO spark.SecurityManager: Changing view acls to: root
16/02/07 17:36:35 INFO spark.SecurityManager: Changing modify acls to: root
16/02/07 17:36:35 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); users with modify permissions: Set(root)
16/02/07 17:36:36 INFO spark.HttpServer: Starting HTTP Server
16/02/07 17:36:36 INFO server.Server: jetty-8.y.z-SNAPSHOT
16/02/07 17:36:36 INFO server.AbstractConnector: Started [email protected]:51277
16/02/07 17:36:36 INFO util.Utils: Successfully started service 'HTTP class server' on port 51277.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.6.0
/_/
Using Scala version 2.10.5 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_60)
Type in expressions to have them evaluated.
Type :help for more information.
16/02/07 17:36:45 INFO spark.SparkContext: Running Spark version 1.6.0
16/02/07 17:36:45 INFO spark.SecurityManager: Changing view acls to: root
16/02/07 17:36:45 INFO spark.SecurityManager: Changing modify acls to: root
16/02/07 17:36:45 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); users with modify permissions: Set(root)
16/02/07 17:36:46 INFO util.Utils: Successfully started service 'sparkDriver' on port 46612.
16/02/07 17:36:47 INFO slf4j.Slf4jLogger: Slf4jLogger started
。。。
16/02/07 17:37:25 WARN metastore.ObjectStore: Failed to get database default, returning NoSuchObjectException
16/02/07 17:37:26 INFO metastore.HiveMetaStore: Added admin role in metastore
16/02/07 17:37:26 INFO metastore.HiveMetaStore: Added public role in metastore
16/02/07 17:37:26 INFO metastore.HiveMetaStore: No user is added in admin role, since config is empty
16/02/07 17:37:26 INFO metastore.HiveMetaStore: 0: get_all_databases
16/02/07 17:37:26 INFO HiveMetaStore.audit: ugi=root ip=unknown-ip-addr cmd=get_all_databases
16/02/07 17:37:26 INFO metastore.HiveMetaStore: 0: get_functions: db=default pat=*
16/02/07 17:37:26 INFO HiveMetaStore.audit: ugi=root ip=unknown-ip-addr cmd=get_functions: db=default pat=*
16/02/07 17:37:26 INFO DataNucleus.Datastore: The class "org.apache.hadoop.hive.metastore.model.MResourceUri" is tagged as "embedded-only" so does not have its own datastore table.
16/02/07 17:37:27 INFO session.SessionState: Created local directory: /tmp/821b1835-fa8e-4b49-9e36-064bda6b9d32_resources
16/02/07 17:37:27 INFO session.SessionState: Created HDFS directory: /tmp/hive/root/821b1835-fa8e-4b49-9e36-064bda6b9d32
16/02/07 17:37:27 INFO session.SessionState: Created local directory: /tmp/root/821b1835-fa8e-4b49-9e36-064bda6b9d32
16/02/07 17:37:27 INFO session.SessionState: Created HDFS directory: /tmp/hive/root/821b1835-fa8e-4b49-9e36-064bda6b9d32/_tmp_space.db
16/02/07 17:37:27 INFO repl.SparkILoop: Created sql context (with Hive support)..
SQL context available as sqlContext.
2.解压
root@master:/usr/local/setup_tools# tar -zxvf spark-1.6.0-bin-hadoop2.6.tgz
3.配置Spark的全局环境变量
输入# vi /etc/profile打开profile文件,按i可以进入文本输入模式,在profile文件的增加SPARK_HOME及修改PATH的环境变量
export SPARK_HOME=/usr/local/spark-1.6.0-bin-hadoop2.6
export
PATH=.:$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$SCALA_HOME/bin:$SPARK_HOME/bin
4.source /etc/profile
5.
root@master:/usr/local/spark-1.6.0-bin-hadoop2.6# cd /usr/local/spark-1.6.0-bin-hadoop2.6/conf
root@master:/usr/local/spark-1.6.0-bin-hadoop2.6/conf# ls
docker.properties.template log4j.properties.template slaves.template spark-env.sh.template
fairscheduler.xml.template metrics.properties.template spark-defaults.conf.template
root@master:/usr/local/spark-1.6.0-bin-hadoop2.6/conf#
6.
配置 spark-env.sh
root@master:/usr/local/spark-1.6.0-bin-hadoop2.6/conf# mv spark-env.sh.template spark-env.sh
export SCALA_HOME=/usr/local/scala-2.10.4
export JAVA_HOME=/usr/local/jdk1.8.0_60
export SPARK_MASTER_IP=192.168.189.1
export SPARK_WORKER_MEMORY=2g
export HADOOP_CONF_DIR=/usr/local/hadoop-2.6.0/etc/hadoop
7.配置slaves
# mv slaves.template slaves
worker1
worker2
worker3
worker4
worker5
worker6
worker7
worker8
8.分发配置
root@master:/usr/local/setup_scripts# vi spark_scp.sh
#!/bin/sh
for i in 2 3 4 5 6 7 8 9
do
scp -rq /etc/profile [email protected].$i:/etc/profile
ssh [email protected].$i source /etc/profile
scp -rq /usr/local/spark-1.6.0-bin-hadoop2.6 [email protected].$i:/usr/local/spark-1.6.0-bin-hadoop2.6
done
root@master:/usr/local/setup_scripts# chmod u+x spark_scp.sh
root@master:/usr/local/setup_scripts# ./spark_scp.sh
9.启动spark集群
root@master:/usr/local/hadoop-2.6.0/sbin# cd /usr/local/spark-1.6.0-bin-hadoop2.6/sbin
root@master:/usr/local/spark-1.6.0-bin-hadoop2.6/sbin# start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /usr/local/spark-1.6.0-bin-hadoop2.6/logs/spark-root-org.apache.spark.deploy.master.Master-1-master.out
worker5: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark-1.6.0-bin-hadoop2.6/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-worker5.out
worker4: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark-1.6.0-bin-hadoop2.6/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-worker4.out
worker7: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark-1.6.0-bin-hadoop2.6/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-worker7.out
worker2: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark-1.6.0-bin-hadoop2.6/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-worker2.out
worker1: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark-1.6.0-bin-hadoop2.6/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-worker1.out
worker6: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark-1.6.0-bin-hadoop2.6/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-worker6.out
worker3: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark-1.6.0-bin-hadoop2.6/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-worker3.out
worker8: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark-1.6.0-bin-hadoop2.6/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-worker8.out
root@master:/usr/local/spark-1.6.0-bin-hadoop2.6/sbin# jps
5378 NameNode
5608 SecondaryNameNode
7260 Jps
7181 Master
5742 ResourceManager
root@master:/usr/local/spark-1.6.0-bin-hadoop2.6/sbin#
root@worker3:~/.ssh# jps
4152 Worker
3994 NodeManager
4202 Jps
3262 DataNode
root@worker3:~/.ssh#
root@worker6:/usr/local# jps
3809 NodeManager
4017 Jps
3077 DataNode
3966 Worker
root@worker6:/usr/local#
10.web查看 ok
http://192.168.189.1:8080/
1.6.0 Spark Master at spark://192.168.189.1:7077
URL: spark://192.168.189.1:7077
REST URL: spark://192.168.189.1:6066 (cluster mode)
Alive Workers: 8
Cores in use: 8 Total, 0 Used
Memory in use: 16.0 GB Total, 0.0 B Used
Applications: 0 Running, 0 Completed
Drivers: 0 Running, 0 Completed
Status: ALIVE
Workers
Worker Id Address State Cores Memory
worker-20160207173343-192.168.189.2-33566 192.168.189.2:33566 ALIVE 1 (0 Used) 2.0 GB (0.0 B Used)
worker-20160207173344-192.168.189.3-37775 192.168.189.3:37775 ALIVE 1 (0 Used) 2.0 GB (0.0 B Used)
worker-20160207173344-192.168.189.4-51803 192.168.189.4:51803 ALIVE 1 (0 Used) 2.0 GB (0.0 B Used)
worker-20160207173344-192.168.189.5-36047 192.168.189.5:36047 ALIVE 1 (0 Used) 2.0 GB (0.0 B Used)
worker-20160207173344-192.168.189.6-55502 192.168.189.6:55502 ALIVE 1 (0 Used) 2.0 GB (0.0 B Used)
worker-20160207173344-192.168.189.7-49027 192.168.189.7:49027 ALIVE 1 (0 Used) 2.0 GB (0.0 B Used)
worker-20160207173344-192.168.189.8-55787 192.168.189.8:55787 ALIVE 1 (0 Used) 2.0 GB (0.0 B Used)
worker-20160207173344-192.168.189.9-56628 192.168.189.9:56628 ALIVE 1 (0 Used) 2.0 GB (0.0 B Used)
11 spark-shell
root@master:/usr/local/spark-1.6.0-bin-hadoop2.6/sbin# spark-shell
16/02/07 17:36:35 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
16/02/07 17:36:35 INFO spark.SecurityManager: Changing view acls to: root
16/02/07 17:36:35 INFO spark.SecurityManager: Changing modify acls to: root
16/02/07 17:36:35 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); users with modify permissions: Set(root)
16/02/07 17:36:36 INFO spark.HttpServer: Starting HTTP Server
16/02/07 17:36:36 INFO server.Server: jetty-8.y.z-SNAPSHOT
16/02/07 17:36:36 INFO server.AbstractConnector: Started [email protected]:51277
16/02/07 17:36:36 INFO util.Utils: Successfully started service 'HTTP class server' on port 51277.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.6.0
/_/
Using Scala version 2.10.5 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_60)
Type in expressions to have them evaluated.
Type :help for more information.
16/02/07 17:36:45 INFO spark.SparkContext: Running Spark version 1.6.0
16/02/07 17:36:45 INFO spark.SecurityManager: Changing view acls to: root
16/02/07 17:36:45 INFO spark.SecurityManager: Changing modify acls to: root
16/02/07 17:36:45 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); users with modify permissions: Set(root)
16/02/07 17:36:46 INFO util.Utils: Successfully started service 'sparkDriver' on port 46612.
16/02/07 17:36:47 INFO slf4j.Slf4jLogger: Slf4jLogger started
。。。
16/02/07 17:37:25 WARN metastore.ObjectStore: Failed to get database default, returning NoSuchObjectException
16/02/07 17:37:26 INFO metastore.HiveMetaStore: Added admin role in metastore
16/02/07 17:37:26 INFO metastore.HiveMetaStore: Added public role in metastore
16/02/07 17:37:26 INFO metastore.HiveMetaStore: No user is added in admin role, since config is empty
16/02/07 17:37:26 INFO metastore.HiveMetaStore: 0: get_all_databases
16/02/07 17:37:26 INFO HiveMetaStore.audit: ugi=root ip=unknown-ip-addr cmd=get_all_databases
16/02/07 17:37:26 INFO metastore.HiveMetaStore: 0: get_functions: db=default pat=*
16/02/07 17:37:26 INFO HiveMetaStore.audit: ugi=root ip=unknown-ip-addr cmd=get_functions: db=default pat=*
16/02/07 17:37:26 INFO DataNucleus.Datastore: The class "org.apache.hadoop.hive.metastore.model.MResourceUri" is tagged as "embedded-only" so does not have its own datastore table.
16/02/07 17:37:27 INFO session.SessionState: Created local directory: /tmp/821b1835-fa8e-4b49-9e36-064bda6b9d32_resources
16/02/07 17:37:27 INFO session.SessionState: Created HDFS directory: /tmp/hive/root/821b1835-fa8e-4b49-9e36-064bda6b9d32
16/02/07 17:37:27 INFO session.SessionState: Created local directory: /tmp/root/821b1835-fa8e-4b49-9e36-064bda6b9d32
16/02/07 17:37:27 INFO session.SessionState: Created HDFS directory: /tmp/hive/root/821b1835-fa8e-4b49-9e36-064bda6b9d32/_tmp_space.db
16/02/07 17:37:27 INFO repl.SparkILoop: Created sql context (with Hive support)..
SQL context available as sqlContext.