使用MPI并行求解前缀和(prefix sum)
使用MPI并行求解前缀和(pre fixsum)
1.背景
本文介绍的并行模式是前缀和(prefixsum),通常也叫扫描(scan)。从数学的角度看,闭扫描(inclusive scan)操作接受一个二元运算符和一个n元输入数组[x0,x1,…,xn-1],然后返回一个输出数组:
[x0,(x0+x1),…,(x0+x1 … +xn-1)]。
2.串行扫描
在介绍并行扫描算法与它们的实现前,先介绍一个高效的串行闭扫描算法以及它的实现。
void sequential_scan(int *x, int *y, int size){
y[0] = x[0];
int i;
for (i = 1; i < size;i++) { // n-1 teims-iteration
y[i] = y[i - 1] +x[i];
}
}
这个是算法的效率很高,每处理一个输入元素x,计算机只需要做一次加法、一次存储器加载和一侧存储器存储。
3.简单并行扫描
本文介绍一个简单的并行扫描算法,该算法对所有输出元素进行归约操作,它的核心思想是通过为每个输出元素计算相关输入元素的归约树来快速创建每个元素。
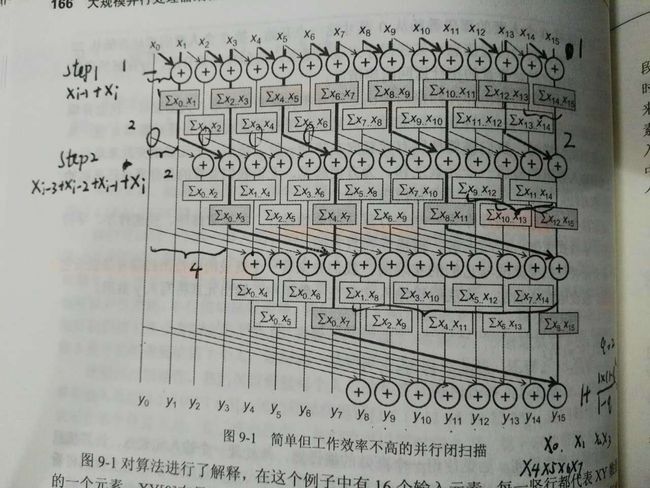
这是一个原地扫描算法,它对输入数组XY进行操作。开始的时候XY数组中保存的是输入元素,然后算法迭代地把数组中的内容转化为输出元素。
上图每一竖行代表XY数组的一个元素,XY[0]在最左边,竖直方向表示迭代的过程。在算法开始前,假设XY[i]中保存了输入元素xi,在n次迭代以后,XY[i]中保存的是这个位置之前(包括这个位置)2^n个输入元素之和,即在第1次迭代结束后,XY[i]中保存的是xi-1 + xi,在第2次迭代结束后,XY[i]中保存的是xi-3 + xi-2 + xi-1 + xi,以此类推。
// Parallel prefix sum
#include <mpi.h>
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
int main(){
int my_rank;
int pNO;
int tag = 0;
int dest;
int source;
MPI_Status status;
MPI_Comm comm;
comm = MPI_COMM_WORLD;
int x_i;
int tmpVal;
int sum;
int *outputArray;
int cutIdx = 1;
int step = 1;
MPI_Init(NULL, NULL);
MPI_Comm_rank(comm, &my_rank);
MPI_Comm_size(comm, &pNO);
x_i = my_rank + 1;
sum = x_i;
int i;
for (i = 1; i < pNO; i *= 2) {
if (my_rank < pNO - cutIdx) {
dest = my_rank + step;
MPI_Send(&sum, 1, MPI_INT, dest, tag, comm);
}
if (my_rank > cutIdx || my_rank == cutIdx){
source = my_rank - step;
MPI_Recv(&tmpVal, 1, MPI_INT, source, tag, comm, &status);
sum += tmpVal;
}
cutIdx *= 2;
step *= 2;
}
if (my_rank != 0){
MPI_Send(&sum, 1, MPI_INT, 0, tag, comm);
}
else{
outputArray = (int*)malloc(sizeof(int)*pNO);
outputArray[0] = sum;
int j;
for (j = 1; j < pNO; j++) {
MPI_Recv(outputArray + j, 1, MPI_INT, j, tag, comm, &status);
}
for (j = 0; j < pNO; j++) {
printf(" %d ", outputArray[j]);
}
printf("\n");
free(outputArray);
}
MPI_Finalize();
return 0;
}
4.效率分析
所有进程将迭代log2(N)步,其中N等于进程数目。每次迭代中,不需要做加法的线程的数量等于跨步大小,计算算法完成的工作量:
∑(N- step), for step 1,2,4,…,N/2 (log2(N)项)
每一项的第一个部分和跨步无关,和是N * log2(N),第二部分类似等比级数,它们的和为N-1。所以加法操作的总数是:
N * log2(N) – (N - 1)
注意串行算法完成的加法总数为N-1。计算同样数据量的前缀和,这种简单并行算法需要几倍的执行单元才能达到和串行代码一样的速度。额外的执行资源和并行中额外开销使得该算法效率不高。
为了提高效率,可以共享一些中间结果,如利用归约树得到的“子和”,来计算扫描的其他输出值。