推荐系统构建中的PCA和SVD算法
推荐本质上是求相似度,重点是如何度量相似性。推荐的常用算法是协同过滤算法,该算法基于用户行为的数据而设计的推荐算法。M个人对N个商品产生行为,从而构成联系,对M个人进行聚类是基于用户(M1和M2相似,则已知M1购买P1,可将P1商品推荐给M2),对N个商品进行聚类是基于商品(P1和P2商品相似,则已知M1购买P1,可将P2商品推荐给M1)。
相似度/距离计算方法有以下几种:
(1)闵可夫斯基距离
(2) 欧式距离
(3)杰卡德相似系数(Jaccard)
(4)余弦相似度 
(5)Pearson相似系数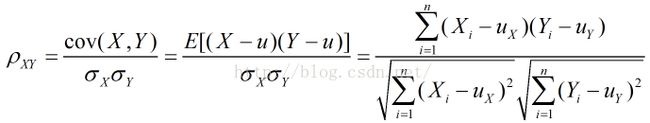
(6)相对熵(K-L距离)
Jaccard相似度的由来
R(u)是给用户u作出的推荐列表,而T(u)是用户在测试集上真正的行为列表
准确率/召回率


Jaccard系数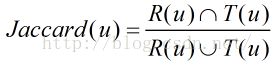
评价推荐系统的首要离线指标
通过将单个用户的准确率(或召回率)做累加,即得到整个推荐系统的准确率(或召回率),该离线指标常常用于比较各个推荐系统之间的优劣。


评价推荐系统的其他指标
覆盖率:
考虑不同商品出现的次数(概率),则可用信息熵或基尼系数。
多样性:

s(i,j)表示相同个数。
惊喜度:满意度/相似度
用户惊喜度来自于和用户喜欢的物品不相似,但用户却觉得满意的推荐。
降维问题的提出(PCA)
实际问题往往需要研究多个特征,而这些特征存在一定的相关性,数据量增加了问题的复杂性。将多个特征综合为少数几个代表性特征。既能够代表原始特征的绝大多数信息,组合后的特征又互不相关,降低相关性,主成分,即主成分分析。
考察降维后的样本方差
对于n个特征的m个样本,将每个样本写成行向量,得到矩阵A
思路:寻找样本的主方向u; 将m个样本值投影到某直线L上,得到m个位于直线L上的点,计算m个投影点的方差。认为方差最大的直线方向是主方向。这里假定样本是去均值化的,若没有去均值化,则计算m个样本的均值,将样本真实值减去均值。
计算投影样本点的方差
1.取投影直线L的延伸方向u,计算A·u的值
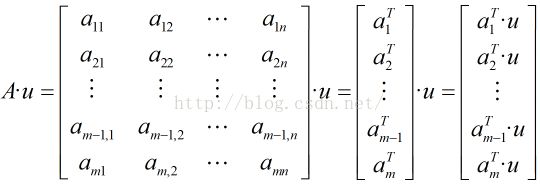
2.求向量A·u的方差
![]()
则得到目标函数

3.由于u数乘得到的方向和u相同,因此,增加u是单位向量的约束,即||u||=1,则![]()
4.建立Lagrange方程

若A中的样本都是去均值化的,则![]() 与A的协方差矩阵仅相差系数n-1
与A的协方差矩阵仅相差系数n-1
根据上公式,u是![]() 的一个特征向量,λ的值大小为原始观测数据的特征在向量u的方向上投影值的方差。
的一个特征向量,λ的值大小为原始观测数据的特征在向量u的方向上投影值的方差。

PCA的重要应用
特征提取:比如变量组合 2X1+X2
数据压缩:降维(把不重要的特征给除去),对原始观测数据A在λ值前k大的特征向量u上投影后,获得一个![]() 的序列,再加上特征向量矩阵Q,即将A原来的m*n个数据压缩到m*k+k*n个数据。
的序列,再加上特征向量矩阵Q,即将A原来的m*n个数据压缩到m*k+k*n个数据。
PCA总结
实对称矩阵的特征值一定是实数,不同特征值对应的特征向量一定正交,重数为r的特征值一定有r个线性无关的特征向量;
样本矩阵的协方差矩阵必然一定是对称矩阵,协方差矩阵的元素即各个特征间相关性的度量;
将协方差矩阵C的特征向量组成矩阵P,可以将C合同为对角矩阵D,对角矩阵D的对角元素即为A的特征值。
![]() ;
;
协方差矩阵的特征向量,往往单位化,即特征向量的模为1,从而,P是标准正交矩阵:![]()
将特征空间线性加权,使得加权后的特征组合间是不相关的,选择若干最大的特征值对应的特征向量(即新的特征组合),即完成了PCA的过程。
关于PCA的进一步思考(SVD)
若A是m*n阶矩阵,不妨认为m>n,则![]() 是n*n阶方阵。根据下式计算:
是n*n阶方阵。根据下式计算:
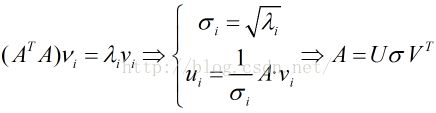
从而,将矩阵A可以写成U,V两个方阵和对角矩阵D的乘积,这一过程,称作奇异值分解SVD.
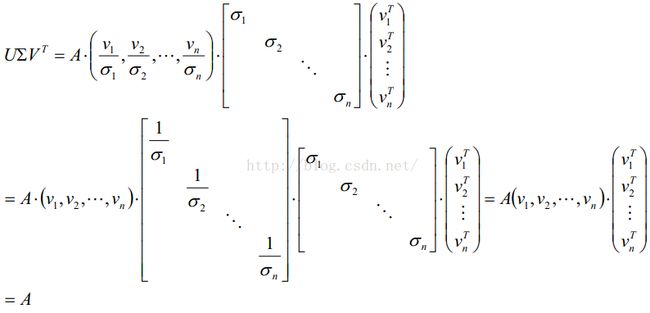
SVD是一种重要的矩阵分解方法,可以看做对称方阵在任意矩阵上的推广。假设A是一个m*n阶的实矩阵,则存在一个分解使得: ,通常将奇异值由大到小排列,这样,
,通常将奇异值由大到小排列,这样,![]() 便能由A唯一确定了。
便能由A唯一确定了。
SVD的四个矩阵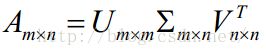 ,在实际中, 往往只保留
,在实际中, 往往只保留![]() 前k个较大的数。
前k个较大的数。
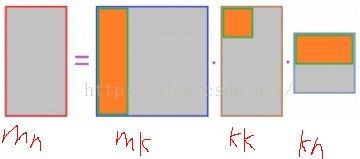 因为面积(n-k)*m>k*k+k*n,说明PCA具有数据压缩的作用
因为面积(n-k)*m>k*k+k*n,说明PCA具有数据压缩的作用
SVD方法(奇异值分解)还可以被用来计算矩阵的伪逆。若矩阵A的奇异值分解为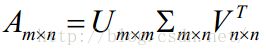 ,那么A的伪逆为
,那么A的伪逆为![]() 其中
其中![]() 是
是![]() 的伪逆,是将主对角线上每个非零元素都求倒数之后再转置得到的。求伪逆通常可以用来求解最小二乘法问题。
的伪逆,是将主对角线上每个非零元素都求倒数之后再转置得到的。求伪逆通常可以用来求解最小二乘法问题。
广义逆矩阵(伪逆)
若A为非奇异矩阵,则线性方程组Ax=b的解为![]()
若A为可逆矩阵,![]() 即为
即为![]()
![]()
当A为矩阵(非方阵)时,称![]() 为A的广义逆(伪逆)
为A的广义逆(伪逆)
新用户的个性化推荐

然后,计算新加用户(Bob)和现在用户的距离:余弦距离(一定意义下即为相关系数),求出其与最近的用户
PCA和SVD总结
矩阵对向量的乘法,对应于对该向量的旋转、伸缩。如果对某向量只发生了伸缩而无旋转变化,则该向量是该矩阵的特征向量,伸缩比即为特征值。
PCA是用来提取一个场的主要信息(即主成分分量),而SVD一般用来分析两个场的相关关系。两者在具体的实现方法上也有不同,SVD是通过矩阵奇异值分解的方法分解两个场的协方差矩阵的,而PCA是通过分解一个场的协方差矩阵。
PCA可用于特征的压缩、降维;当然也能去噪等;如果将矩阵转置后再用PCA,相当于去除相关度过大的样本数据——但不常见,SVD能够对一般矩阵分解,发现隐变量,并可用于个性化推荐等内容。![]() (n*n)降维对象为特征,
(n*n)降维对象为特征,![]() (m*m)降维对象为样本。
(m*m)降维对象为样本。
关于电影权值问题:如果电影M1非常流行,相当数目的人都看过;电影M2流行度偏低,则如果两人都看过M2,则他们的相似度应该更高,适当提高非流行商品的权值。