ELK日志分析
1.Elasticsearch 2.0.0 Install
1-1.下载文件到本地:
https://www.elastic.co/downloads/elasticsearch
wget https://download.elasticsearch.org/elasticsearch/release/org/elasticsearch/distribution/tar/elasticsearch/2.0.0/elasticsearch-2.0.0.tar.gz在项目根目录下新建data文件夹
#mkdir data1-2.设置服务ip&&port
修改文件elasticsearch.yml
#pwd
/data2/elasticsearch-2.0.0/config
[root@10 config]# vim elasticsearch.yml 修改成服务ip和port
network.host: 10.13.1.139
http.port: 543211-3.安装插件
在项目根目录下没有plugins文件夹,需通过安装插件新建该文件夹,
the core plugins can be installed as follows:
[root@10 bin]# pwd
/data2/elasticsearch-2.0.0/bin
[root@10 bin]# ./plugin install analysis-icu
-> Installing analysis-icu...
Plugins directory [/data2/elasticsearch-2.0.0/plugins] does not exist. Creating
1-4.sudo用户修改文件为读写执行(启动服务时,需非Root账号)
非Root账号启动服务时,会新建文件
[root@10 elasticsearch-2.0.0]# chmod 777 *1-5.启动服务
切换到非Root用户,启动服务
[root@10 ~]# su - hugang
[hugang@10 ~]$ cd /data2/elasticsearch-2.0.0/bin
[hugang@10 bin]$ ./elasticsearch -d
验证服务
[hugang@10 bin]$ curl -X GET http://10.13.1.139:54321
{
"name" : "Madame Hydra",
"cluster_name" : "elasticsearch",
"version" : {
"number" : "2.0.0",
"build_hash" : "de54438d6af8f9340d50c5c786151783ce7d6be5",
"build_timestamp" : "2015-10-22T08:09:48Z",
"build_snapshot" : false,
"lucene_version" : "5.2.1"
},
"tagline" : "You Know, for Search"
}2.Logstash 2.0.0 Install
Logstash:Collect, Enrich & Transport Data;Logstash负责收集,丰富和传输log数据,Pipeline由三部分组成:
- input:指定来源
- filter:过滤规则
- output:指定输出
在配置文件指定这三个元素,运行Logstash时,需在执行脚本bin/logstash加上该配置文件作为脚本参数。
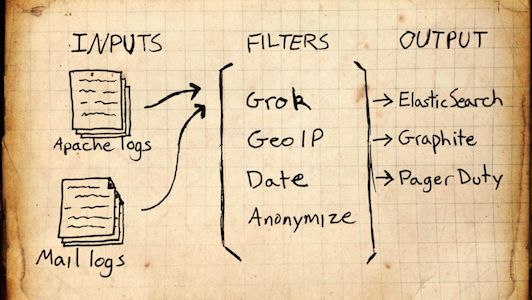
运行环境要求:JDK minimum version 1.7.0_51
2-1.下载Logstash
https://www.elastic.co/downloads/logstash
wget https://download.elastic.co/logstash/logstash/logstash-2.0.0.tar.gz2-2.新建配置文件
根据自己业务需求,新建Pipeline配置文件,文件名自定义,但是内容必须含有input, filter, output三元素。
collectlogtoredis.conf
input {
file {
path => "/data1/weibo8074/logs/exposure.log"
}
}
filter {
grok {
match => { "message" => "(?<uida>[0-9]{10}) (?<uidb>[0-9]{10}) (?<idList>([0-9]{16},){1,}[0-9]{16})" }
}
}
output {
redis { host => "10.13.1.139" port => 6379 data_type => "list" key => "logstash:collect:exposurelog" }
}
input: 指定Logstash收集数据的来源,支持多种来源,比如:file, stdin, syslog, elasticsearch等,具体可参照:https://www.elastic.co/guide/en/logstash/current/input-plugins.html
filter: 提取有效信息的规则,支持如下:grok, json, xml, csv等,具体可参照: https://www.elastic.co/guide/en/logstash/current/filter-plugins.html
output: 将数据发送到特定目的地,支持如下:csv, kafka, syslog, stdout, redis等,具体可参照: https://www.elastic.co/guide/en/logstash/current/output-plugins.html
collectlogtoredis.conf 分析
- 指定input来源为file, 格式如下:
file {
path => ...
}path为配置选项(必填), 类型为array, 可以如下定义, 支持通配符:
path => [ "/var/log/messages", "/var/log/*.log" ]
path => "/data/mysql/mysql.log"stat_interval配置选项:How often (in seconds) we stat files to see if they have been modified. 默认1s.
- 指定filter为grok, grok解析任意的文本,是最好的方式解析杂乱log数据成结构化,默认有超过120模式: https://github.com/logstash-plugins/logstash-patterns-core/tree/master/patterns, 也可以自定义自己的模式, 提供在线调试 http://grokdebug.herokuapp.com.
match为配置选项,Value type is hash, Default value is {};A hash of matches of field ⇒ value
For example:
filter {
grok { match => { "message" => "Duration: %{NUMBER:duration}" } }
}
If you need to match multiple patterns against a single field, the value can be an array of patterns
filter {
grok { match => { "message" => [ "Duration: %{NUMBER:duration}", "Speed: %{NUMBER:speed}" ] } }
}- 指定output为redis, 指定host, port, key等。
2-3. 启动Logstatsh服务
执行bin/logstash agent -f collectlogtoredis.conf
3.kibana 4.2.1
3-1.下载
https://www.elastic.co/downloads/kibana
wget https://download.elastic.co/kibana/kibana/kibana-4.2.1-linux-x64.tar.gz3-2.配置elasticsearch地址
在config/kibana.yml 修改成你本地elasticsearch服务地址
elasticsearch.url: “http://10.13.1.139:54321”
3-3.启动服务
./bin/kibana访问kibana服务:
ip:5601具体配置请参照:https://www.elastic.co/webinars/getting-started-with-kibana?baymax=rtp&elektra=blog&iesrc=ctr