计算机组成.计算机在计算啥.运算与ALU
- 突然发现在iPad的网页上也可以写博客哎,,这样就不用背着厚重的笔记本了
- 写了两句就发现,在输入状态下文本编辑窗口只能保持在最高,,,这样就被虚拟键盘挡住了,,,体验-1
再写两句发现又好了,,,体验+1
我所认为的计算机的运算,无非就是“算数”,除了传统的加减乘除外,在二进制的表示下,还有逻辑运算与移位运算。
- 而计算机真正的魅力在于,可以算得很快,所以承受得住我们去对每一个运算所赋予的详细含义,在各种含义下的运算互相碰撞着,也就干成了各种各样的事情。
- 二进制的逻辑运算对应与数学上的二元布尔代数,也是最简单的布尔代数,说白了就是真与假,就是1和0,,,而最简单的布尔代数已经让电计算机如此高效,,
- 移位运算实际上是一种受限的乘除,即只能扩大缩小一定的倍数。比如1000右移一位成0100也就缩小了2倍,再移一位成0010又缩小了2倍,相对于最初缩小了4倍。那我想缩小三倍怎么办?这就是乘法和除法要做的事,其很大程度上依赖了移位运算。
定点数的运算
- 二进制的特点是,只有1和0,也就可以把“1”对应为“逻辑真”,“0”对应为“逻辑假”。
- 真真假假与或非,假假真真门电路
- 简单的认识一下的话,计算机内把每一位也就是每个bit用一个电位体现,当这个电位有电表示1,没电表示0。
- 所以说计算机为什么非要采用二进制而不用十进制或其他进制呢?这是因为数据中的每一位需要用一位表示的话,一个电位要表示0到9的十种状态,就要有十个电压等级,这无疑是很复杂的。而且一位表示的信息越多,其处理起来也越复杂,而二进制只有1和0,处理起来极为简单,当二进制保存的位也多,其处理的复杂在于多个位之间的联系。
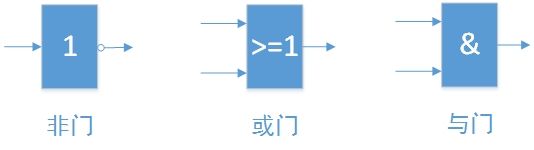
门电路
- 门电路干啥的?还记得1和0是用“有电”和“没电”来表示的吗,而门电路就是来根据有电和没电的状态来对1和0进行运算
- 什么是运算?我说1+1=2,实际上是输入了两个值,分别是1和1,告诉说对着两个数的运算是“+”,那么我就可以得到一个输出的结果2
- 每种门电路本身就对应了一种运算形式,最简单的门电路就是与“AND”、或“OR”、非“NOT”
- 一般一个门电路有两根电线作为输入,有一根电线作为输出
- 与AND:只有输入的两根电线都有电,输出的电线才有电
- 或OR:只有输入的两根电线都没电,输出的电线才没电
- 非NOT:只有一个输入电线,输入有电则输出没电,输入没电则输出有电
- 有电、没电、电线都是我臆想的,实现的方法我猜大概是串并联开关啥的吧,,,作为理解尚可,而具体能否这样实现我不知道了,,,有时间打算研究一下数字电路
- 注意,非门中真正起作用的是那个小圈圈,表示取反,常与其他门电路结合表示各种更为复杂的电路
逻辑运算
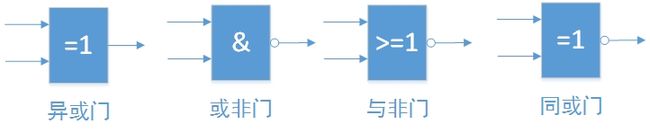
- 逻辑非
- 也就是取反,1变0,0变1
- 由“非门”电路实现
- 逻辑加
- 就是“或”,1+1=1,1+0=1,0+1=1,0+0=0。
- 由“或门”电路实现
- 逻辑乘
- 就是“与”,1·1=1,1·0=0·1=0·0=0。
- 由“与门”电路实现
- 逻辑异或
- “XOR”,其规则是1 XOR 1 = 0 XOR 0 = 0 ,1 XOR 0 = 0 XOR 1 = 1
- 解释1:相同输出0,不同输出1。只适合两个数的时候。
- 解释2:参与运算的1的个数为偶数输出0,为奇数输出1。适合多个数进行XOR运算时候,比如1 XOR 0 XOR 1 = 0。
- 异或运算有很多很好的特性,没法讲,活久见
移位运算
- 移位运算就是按位平移,有的位会移到外面,那么就丢弃,有的位会空出来 ,那么就补0,这个绝对的“补0”是对于原码而言的。
- 还是4 bit为例,二进制数“1000”,每位起个名字,最高位w3为1,依次w2为0,w1为0,w0为0
- 右移一位,就是让w0取w1的值,w1取w2的值,w2取w3的值,w3没地方取,就补0,变成了“0100”,视觉上就是“右移了一位”。
- 机器总是需要一个符号位来表示有符号数,而显然符号位在移位的时候并不参与,那么
- 对于有符号数的移位操作,我们叫“算数移位”
- 对于无符号数的移位操作,我们叫“逻辑移位”
- 其实无论算数移位还是逻辑移位,都是一种移位的规则,只不过只有对于各自的操作数才有意义。
- 显然符号位的移位并没有什么意义,,,,,,当然如果有什么特殊的手法可以让符号位的移动产生重要的意义,那么当然是可以移动的。
- 算术移位
- 基本规则:符号位不变,移位的空位补0
- 细则1:对于正数,无论机器内使用原码、反码还是补码表示,其都是原码的形式,因正数的原码反码补码是同样的表示,所以空位补0
- 细则2:对于负数,原码下空位补0,反码空位补1,补码左移补0,右移补1
- 有个表格会好理解一些,依旧是4bit,最高位符号位
| 数值 | 原码 | 补码 | 补码左移1位 | 左移后值 | 补码右移1位 | 右移后值 |
|---|---|---|---|---|---|---|
| 2 | 0010 | 0010 | 0100 | 4 | 0001 | 1 |
| -2 | 1010 | 1110 | 1100 | -4 | 1111 | -1 |
还有一点,就是移位的固有影响
- 本质上是乘、除的二进制简化形式,左移一位即乘2,右移一位即除2
- 而操作的数又是整数,那么在不断乘2(左移)的时候很可能会超过其上限而造成结果出错,而在不断除2(右移)的时候很可能有会因为原数为奇数而不能正确的得出其原值*0.5的值,表现就是取整,造成精度损失
- 从移位的角度来看,移位的时候必然会舍弃一位,而舍弃的一位若含有原数的信息,就会造成错误。
- 至于原码反码补码分别在左移右移时丢弃1还是0的时候才会出错,,,不再细究,,,
逻辑移位:
- 基本规则是,无论左移右移,空位补0
- 无论移丢0还是1,都不影响结果的正确性和精度
- 没意思,不写了
加减
由于计算机引入了补码,目的就是为了统一了正负数的运算,所以加减乘除也就要在补码下讲,当然在原码下也同样可讲,,,
对于两个数值X,Y(我是说数值哦)
- 加法:[X + Y]补 = [X]补 + [Y]补 (mod 2^n)
- 减法:[X - Y]补 = [X]补 + [-Y]补 (mod 2^n)
- 之所以要mod2^n,是因为原本长度为n位,运算之后可能会有进位导致长度变长,而实际上计算机是没有办法保存多出来的那一位(尽管可以采取某种特殊的手段来保存)所以就舍弃掉了。
- 对于减法的 [-Y]补 ,其求法为 [Y]补 的每位(包括符号位)取反后+1,即[-Y]补 = [Y]补 +1。当Y为正数时,-Y为负数,负数的补码也就是对应正数的取反后+1,符合我们所知的转换规则。而这条规则同样适用于Y为负数的时候。
- 惯例列表
| X值 | [X]补 | 加法 | Y值 | [Y]补 | 结果值 | [结果]补 |
|---|---|---|---|---|---|---|
| 2 | 0010 | + | 1 | 0001 | 3 | 0011 |
| -1 | 1111 | + | 2 | 0010 | 1 | 0001 |
| X值 | [X]补 | 减法 | Y值 | [-Y]补 | 结果值 | [结果]补 |
|---|---|---|---|---|---|---|
| 3 | 0011 | - | 1 | 1111 | 2 | 0010 |
| 2 | 0010 | - | -1 | 0001 | 3 | 0011 |
乘除
- 早期的计算机一般只有加法器和移位电路,乘法的实现依赖于加法和移位。
- 我们知道移位就是一种受限的乘法,左移一位相当于乘2,左移两位相当于乘4。那么乘法就是解决中间乘3的问题。很简单可以想到,乘3就等于原数乘2+原数本身,也就是一次移位和一次加法来实现。
- 那么这种思路可不可以形成一种公式来指导任意的乘法运算呢? 当然是有的
- 原码一位乘法
- 先在原码下考虑,补码的话其实会有些不同。注意原码表示的乘数下,结果也应该是用原码表示
- 先以我自己琢磨的定点整数为例,约定一下按每一位来表示的整数我写在[ ]里面,并用空格间隔开每位。
- 则A=[a3 a2 a1 a0] B=[b3 b2 b1 b0]
- A*B的每一位用c来表示,则c3 = a3 XOR b3,即符号位可以由两个乘数的符号位直接得出(异或运算)从而符号位可以不用参与实际的运算过程
- [c2 c1 c0]
- = [a2 a1 a0] * [b2 b1 b0]
- = [a2 a1 a0] * ( [b2 0 0] + [0 b1 0] + [0 0 b0] )
- = [a2 a1 a0] * [0 0 b0] + [a2 a1 a0] * [0 b1 0] + [a2 a1 a0] * [b2 0 0]
- = [a2 a1 a0] * b0 * 2^0+ [a2 a1 a0] * b1 * 2^1 + [a2 a1 a0] * b2 * 2^2
- 注意到:
- b2 b1 b0实际上就是B的每一位,而且只能是1或0,如果是0则对应项就不必运算
- b0所在项需要乘2^0,也就是不需要左移
- b1所在项需要乘2^1,也就是左移一位,也就是在前一项的基础上左移一位
- b2所在项需要乘2^2,也就是左移二位,也就是在前一项的基础上左移一位
- 至此其实已经相当明了了,就是根据乘数B的每一位,对乘数A进行左移并加上之前的值,我们把之前的值作为部分积的概念引入
- 取部分积 Z0 = 0,A的绝对值记为|A|
- Z1 = |A| * b0 * 2^0
- Z2 = |A| * b1 * 2^1 + Z1
- Z3 = |A| * b2 * 2^2 + Z2
- 但是这样还有个不足之处,那就是我每次进行的移位位数是递增的,而这很容易改进,从公式就可以简单的入手
- 原式
- = [a2 a1 a0] * b0 * 2^0+ [a2 a1 a0] * b1 * 2^1 + [a2 a1 a0] * b2 * 2^2
- = [a2 a1 a0] * b0 + 2 * ( [a2 a1 a0] * b1 + 2 * [a2 a1 a0] * b2 )
- 取部分积 Z0 = |A| * b2
- Z1 = Z0 * 2 + |A| * b1
- Z2 = Z1 * 2 + |A| * b0
- 语言描述下就是:
- 1、部分积取 |A| * b2
- 2、部分积左移一位
- 3、部分积 += |A| * b1
- 4、部分积左移一位
- 5、部分积 += |A| * b0
- 得到结果
- 再以书上所讲的定点小数为例
- 设A=[a3 . a2 a1 a0],B=[b3 . b2 b1 b0],
- a3和b3表示符号位
- 真正的纯小数部分为 0. a2 a1 a0 的形式
- 乘积的符号依旧由 a3 XOR b3 算得
- A * B
- = [0. a2 a1 a0] * [0. b2 b1 b0]
- = [0. a2 a1 a0] * ( [0. b2 0 0] + [0. 0 b1 0] + [0. 0 0 b0] )
- = [0. a2 a1 a0] * b2 * 2^-1 + [0. a2 a1 a0] * b1 * 2^-2 + [0. a2 a1 a0] * b0 * 2^-3
- = [0.a2 a1 a0] * b2 * 2^-1 + 2^-2 * ( [0. a2 a1 a0] * b1 + [0. a2 a1 a0] * b0 * 2^-1 )
- = 2^-1 * ( [0. a2 a1 a0] * b2 + 2^-1 * ( [0. a2 a1 a0] * b1 + [0. a2 a1 a0] * b0 * 2^-1 ) )
- = 2^-1 * ( |A| * b2 + 2^-1 * ( |A| * b1 + 2^-1 * |A| * b0 ) )
- 取部分积Z0 = |A| * b0
- Z1 = 2^-1 * Z0 = Z0 右移一位
- Z2 = Z1 + |A| * b1
- Z3 = 2^-1 * Z2 = Z2 右移一位
- Z4 = Z3 + |A| * b2
- Z5 = 2^-1 * Z4 = Z4 右移一位
- 语言描述:
- 部分积取 |A| * b0
- 部分积右移一位
- 部分积 += |A| * b1
- 部分积右移一位
- 部分积 += |A| * b2
- 部分积右移一位
- 注意到 b0 b1 b2 的含义,它们是乘数 B 的每一位,而且值只能是1和0。反映到过程中讲就是,如果 B 中有一位为1,那就要在“相应的两次右移之间”部分积加上一次 |A|,如果该位为 0,部分积就可以连续右移。
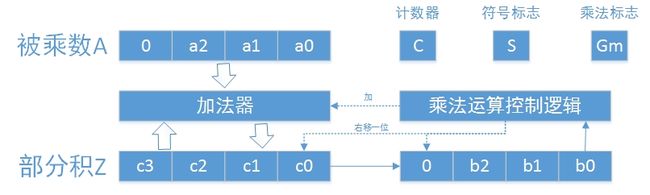
- 小结:
- 定点整数左移,定点小数右移
- 乘法被分解成“加上原数和移位一位”的多次重复
- 结合硬件的布局也许会更容易理解。一下是定点小数的硬件布局
- 补码一位乘法
- 补码一位乘法又称为校正法,原因就是有了原码一位乘法的基础,补码一位乘法只需稍作分析和校正即可转换为原码一位乘法来运算
- 以定点小数为例,并给出一张帮助理解的编码表
| 编码 | 一般意义下的值 | 视为补码下的值 | 视为原码下的值 |
|---|---|---|---|
| 0.00 | 0 | 0 | 0 |
| 0.01 | 0.25 | 0.25 | 0.25 |
| 0.10 | 0.5 | 0.5 | 0.5 |
| 0.11 | 0.75 | 0.75 | 0.75 |
| 1.00 | 1 | -1 | -0 |
| 1.01 | 1.25 | -0.75 | -0.25 |
| 1.10 | 1.5 | -0.5 | -0.5 |
| 1.11 | 1.75 | -0.25 | -0.75 |
- 取两个乘数 X 和 Y均为小数 ,这里用X和Y表示一般意义下的编码。
- 所谓的一般意义就是不用符号位来保存符号,而是直接用“+”和“-”,就像我们正常写十进制的数字的时候,正12就写成“12”,负11就写成“-11”。
| 数值 | 一般编码 | 原码 | 补码 |
|---|---|---|---|
| 0.25 | +0.01 | 0.01 | 0.01 |
| -0.25 | -0.01 | 1.01 | 1.11 |
模运算
- 在这里我们再讲一下模运算
- 给定一个正整数p,任意一个整数n,一定存在等式
n=k∗p+r满足k为整数,r为整数且 0 <= r < p
- 我们称k为商,r为余数
- 所谓的模运算,也就是
n mod p=r这种形式,编程里用 % 运算符来表示模运算,即n % p=r
- 模运算规律,只介绍我们用到的两条和我额外添加的辅助理解的简单规则
- 一、(a + b)%p = (a%p + b%p) %p
- 二、(a * b)%p = (a%p * b%p)%p
- 三、a%p = (p + a)%p
- 四、a>0时,由上一条,(-a)%p = (p-a)%p,即一个负数模p可以等价转换成一个正数模p,而这两个数的绝对值之和为p
- 给定一个正整数p,任意一个整数n,一定存在等式
正文
- [X]补 = x0.x1x2x3…xN-1,[Y]补 = y0.y1y2y3…yN-1
- 当 X 的符号任意,Y为正数的时候
- [Y]补 = 0.y1y2y3…yN-1 = Y
- [X]补 = x0.x1x2x3…xN-1 = 2+X = 2^N +X (mod 2)
- 解释一下
- 这里等号“=”的意义是“编码后长得相同”
- 当Y为正数的时候,Y的一般意义下的编码形式和Y的补码形式相同,显然易见。
- X为任意数,即可正可负。但是X是定点小数,不考虑符号的话一般意义下表示的数字范围是[0,2),所以对于一个数值X,其加上2后的编码一样,因为“2”本身已经超过了编码的能力,即使加上了也无法被编码,具体的表现形式就是截断。外在表现之一就是模运算的运算规律三。
- 如X的值为0.25,编码为000.01000,按表格中存储的位来截断之后的编码就是0.01
- X+2的值为2.25,编码为010.01000,截断后仍是0.01。
- 进一步分析,如果X为负数怎么办。依旧是举例说明。
- X的值为 -0.25 , 根据表格
- X的补码形式是 “1.11”
- X+2的值为1.75,一般编码的形式是“1.11”
- 也就是说,冥冥之中,有一种特殊的方法规律可以把我们一般意义下的编码和补码统一起来,简单的+2并取模就可以转换。
- 这个规律就是:对于任意小数 N,有 [N]补 = 2 + N (mod 2),而这个规律恰又对应上了模运算的规律三,而且其实有种内在的数学联系。
- 进一步的进行数学分析
- [X]补 * [Y]补
- = [X]补 * Y
- = (2^N + X) * Y (mod 2)
- = ( 2^N * Y (mod 2) + X * Y ( mod 2) ) (mod 2)
- = ( 2 (mod 2) + X * Y (mod 2) ) (mod 2)
- = ( 2 + X * Y) ( mod 2)
- = [X * Y]补
- 注意到中间加粗部分的转换,即”2^N * Y (mod 2) = 2 (mod 2)”
- 2^N * Y 也就是对Y进行左移,还记得 Y 是 0.y1y2y3…yN-1吗,如果左移N-1位的话,也就变成了 y1 y2 y3 … yN-1.000…0,这本身是一个大于等于1的数(注意到Y是一个正数),所以“原式 = 2 * 一个大等于1的整数 (mod 2) ”也就等于“2 (mod 2)”。其实二者在mod 2的意义下就都是0了嘛。
- 之所以转换成2,而不是其他同样是全0的编码,是为了对应上文的规律,从而得出 [X * Y]补 这个最终结果
- 所以最终的结论就是:[X * Y]补 = [X]补 * Y
- 疑问?从推导过程中可以发现,在最后两步的等式中,即
(2+X∗Y) (mod 2)=[X∗Y]补对前者运用模运算的规律的话就可以直接去掉2,从而变成了(X∗Y) (mod 2) = [X∗Y]补了啊,这很奇怪啊。。。
- 其实这样的推导很对,确实可以得出这个结果,而且这个结果也确实是对的。
- 这里X和Y的意义是“一般编码”下的形式,分类讨论一下的话
- X为正,Y本为正,则式子显然成立
- X为负,Y为正,则 X * Y 其实是一个负值,但这还不是最终的结果,最终[X * Y]补所对应的是 (X * Y)(mod 2),也就是身为负值的 X * Y模2之后的结果。要知道模运算的结果r总是一个大于等于0的数,所以最终[X * Y]补的编码形式其实也就是和 (2+X*Y)的编码形式相同。
- 但我们最终需要的是直接使用[X]补和[Y]补来运算得到[X*Y]补。所以我们留下了“2”,不仅仅是因为这样做是正确的(见上条的分类讨论),同时也是因为我们这样可以转换成我们需要的形式。
- 再说一遍我们的推导结论:[X * Y]补 = [X]补 * Y
- 这个结论意味着什么呢?意味着我们最终需要得到的X*Y的补码形式可以直接由X的补码和Y的补码(因为此时Y为正所以[Y]补=Y)形式直接参与运算得到。
- 具体的运算步骤和原码的拆分一模一样,简单讲一下
- [X * Y]补 = [X]补 * 0. y1 y2 y3 … yN-1
- 取部分积Z0 = 0,我们最终要得到的结果是[Zn-1]补
- [Z0]补 = 0
- [Z1]补 = 2^-1 * (yN-1 * [X]补 + [Z0]补)
- [Z2]补 = 2^-1 * (yN-2 * [X]补 + [Z1]补)
- ……
- [Zn-1]补 = 2^-1 * (y1 * [X]补 + [Zn-2]补) = [X * Y]补
- 当X的符号任意,Y为负数的时候
- 我不打算推导了,,,真累
- 结论:[X * Y]补 = [X]补 * 0.y1 y2 y3 … yN-1 +[-X]补
- 最后需要加上的 [-X]补 也就是补码一位乘法的校正值,可见校正只需要在Y为负的情况下才需要
- 所以实际在运算的时候,只有一个乘数是以真正的补码的形式参与了运算,而Y则需要在判断了符号之后去掉符号位变成正数来参与运算,Y的符号位做额外判断是为了判断最后是否需要加上[-X]补来进行校正
- 那有没有两个乘数都以补码的形式直接参与运算,最后得出正确的补码形式呢?额符靠丝
- 布斯算法“Booth算法”
- [X]补 = x0.x1x2x3…xN-1 [Y]补 = y0.y1y2y3…yN-1
- 按照校正法的结论
[X∗Y]补 =[X]补 ∗ 0.y1y2y3...yN−1 +y0 ∗ [−X]补
- 由于在mod 2的意义下,[-X]补 = -[X]补 (mod 2)
- 证明:证明太晦涩,我可以举例来解释一下
- 取X=0.25,则-X = -0.25。后面几行都是二进制的形式
- 查表:[X]补 = 0.01 ; [-X]补 = 1.11
- -[X]补 = -0.01
- -0.01 (mod 2) = (10.00 - 0.01) (mod 2) = 1.11 (mod 2) = 1.11
- 所以有[-X]补 = -[X]补 (mod 2)
- 简单说来就是,mod 2意义下,负值总要通过加2来转化为正值,之后再谈编码形式
- 证明:证明太晦涩,我可以举例来解释一下
- 所以最终就有如下的形式
- [X * Y]补
- = [X]补 * (0.y1y2y3…yN-1)- y0 * [X]补
- = [X]补 * (-y0 + y1 * 2^-1 + y2 * 2^-2 + … + yN-1 * 2^-(N-1) )
- = [X]补 * [ (y1 - y0) + (y2 - y1) * 2^-1 + … + (yN-1 - yN-2) * 2^-(N-2) + (0 - yN-1) * 2^-(N-1) ]
- = [X]补 * [ (y1 - y0) + (y2 - y1) * 2^-1 + … + (yN-1 - yN-2) * 2^-(N-2) + (yN - yN-1) * 2^-(N-1) ] 式中”yN = 0”
- 如此再结合部分积
- 取部分积Z0 = 0
- Z1 = 2^-1 * {Z0 + (yN - yN-1) * [X]补 }
- Z2 = 2^-1 * {Z1 + (yN-1 - yN-2) * [X]补 }
- ……
- ZN-1 = 2^-1 * { ZN-2 + (y2 - y1) * [X]补 }
- ZN = ZN-1 + (y1 - y0) * [X]补 = [X * Y]补
- [X]补直接参与了运算,y0也参与了运算也就意味着Y也是以补码的形式[Y]补直接参与了运算
- 特点
- 首先是X和Y均是以补码的形态[X]补和[Y]补参与了运算
- 结果是[X*Y]补
- 运算期间的逻辑变得复杂了,原先只需要看Y的对应位是1和0,而现在每一步需要用到Y的两位之间的差,见下面的表格
- 最后一步是不需要乘2^-1,也就是不需要右移
| yi-1 yi | yi - yi-1 | 操作 |
|---|---|---|
| 0 0 | 0 | 加上0,然后右移一位 |
| 0 1 | 1 | 加上[X]补,然后右移一位 |
| 1 0 | -1 | 加上[-X]补,然后右移一位 |
| 1 1 | 0 | 加上0,然后右移一位 |
- 除法运算
- 因为考试不考,,,所以先不细写了,,简要讲一下我对除法的理解
- 想象一下十进制下手算除法的过程,总是要去凑出每一位,使其与除数相乘的结果刚好不大于下面的被除数。每次凑数的时候都需要乘乘看到底是不是刚好不大于被除数。
- 那么在二进制下也是凑的吗?不,这可是神奇的二进制
- 因为二进制只有0和1,所以假如在二进制下模仿十进制除法的姿态,我们去凑数的时候也只有0和1两种选择
- 如果0是正确的结果,这也就意味着除数大于被除数
- 如果1是正确的结果,这也就意味着除数小于被除数
- 也就是说,在二进制下,我们不需要凑数,只需要比较一下除数和被除数那个大,就可以知道当前数位上是填0还是填1了。
- 比较好比啊,只需要两个数减一减就知道谁大谁小了。
- 再配合上移位操作,除法也就被完美的用减法和移位实现了。
- 嗯。神奇的二进制。
- 具体的方法有
- 原码恢复余数除法
- 核心思想就是:每次在做减法看谁大谁小来决定填1还是0的时候,我们并不知道到底谁大谁小。
- 看谁大谁小,就需要看减完的余数是正还是负
- 如果余数为负,就说明我们减过头了,自然是填0,但是我们还需要再把余数恢复过来,也就是所谓的“恢复余数”
- 原码加减交替除法
- 核心思想就是:改进了原码恢复余数除法,不需要恢复余数。
- 本质上我们不需要死板的看余数的正负才能判断谁大谁小,
- 在余数为负的时候,我们可以通过加上除数而不是恢复余数后再去除数,一样可以判断谁打谁小来进一步判断填1还是0
- 余数为正的时候自然就是减去除数
- 所谓加减交替
- 原码恢复余数除法
ALU
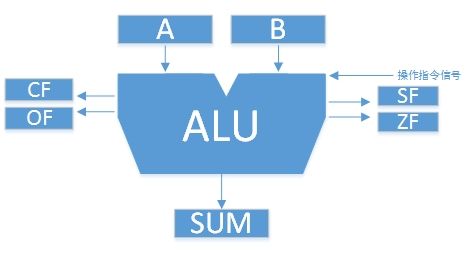
- 算术逻辑单元(arithmetic and logic unit)
- 组成:
- 内部组成:
- 加法器AU
- 逻辑运算器
- 移位器
- 求补器
- 外部组成:
- 两个输入缓冲器A和B
- 输出缓冲器SUM
- 进位标志CF、溢出标志OF、符号标志SF、零标志ZF
- 内部组成:
加法器
- 加法器比较好讲,也比较简单
- 所以大概这就是被选入教材的原因
串行加法器
- 考虑我们手算加法的时候,总是
- 先个位相加,选出结果和进位
- 再十位相加并加上进位,再算出结果和进位
- ……
- 这个就是一个链式的过程,每一位(除了第一位)之外其结果的得出都依赖于前一位的进位,并且该位运算完的进位需要提供给下一位才能得出下一位的结果和进位,下一位的进位再……
- 基本逻辑单元:全加器FA(Full Adder)
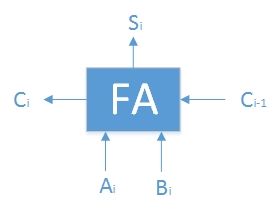
- 介绍
- 两个本位加数 Ai 和 Bi
- 低位进位 Ci-1
- 本位和 Si
- 向高位的进位 Ci
- Si = Ai XOR Bi XOR Ci-1
- Ci = Ai·Bi + (Ai+Bi)·Ci-1(逻辑加OR 与 逻辑乘AND)
- 记Gi=Ai·Bi称为本位进位
- 记Pi=Ai+Bi称为传递条件,Pi·Ci-1称为传递进位
- 可见:Ci = Gi + Pi·Ci-1
- 多个FA串接起来,就组成了串行加法器
- 特点
- 器件单一(仅FA)成本低
- 速度慢,,,想想就要慢死了
并行加法器
- 我们看到,每一位之间的依赖关系,是“进位值Ci”
- 如果我们能提前知道了每一位的 Ci,那么位之间的依赖关系也就不复存在了,也就可以并行进行了,就是同时算所有的数位
有办法吗?有的
以四位CRA(Carry Ripple Adder)为例
- C0 = 0
- C1 = G1 + P1·C0
- C2 = G2 + P2·C1
- C3 = G3 + P3·C2
- C4 = G4 + P4·C3
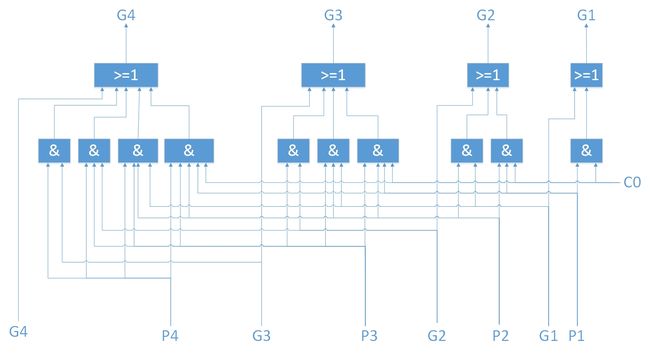
- 进一步变换可得到
- C0 = 0
- C1 = G1 + P1·C0
- C2 = G2 + P2·G1 + P2·P1·C0
- C3 = G3 + P3·G2 + P3·P2·G1 + P3·P2·P1·C0
- C4 = G4 + P4·G3 + P4·P3·G2 + P4·P3·P2·G1 + P4·P3·P2·P1·C0
- 容易看出,虽然逻辑复杂了很多,但是Ci只和G、P、C0有关,而不依赖于Ci-1,而G、P有只和各自的Ai、Bi有关
- 这也就意味着,我们一开始就知道的Ai、Bi和C0=0,足以求出C1、C2、C3、C4。这样不就是“提前把所有的Ci”求出来了嘛
- 我们就设计了这样的逻辑电路,输入是G1、P1、G2、P2、G3、P3、G4、P4、C0,依照公式设计好电路,输出是C1、C2、C3、C4,分别输入到对应的全加器FA中。
- 这就是先行进位加法(Carry Look Ahead, CLA)链,也叫超前进位链
- 四个FA和一个CLA就可以组成一个四位的先行进位加法器,SN74181就是这样一种ALU芯片
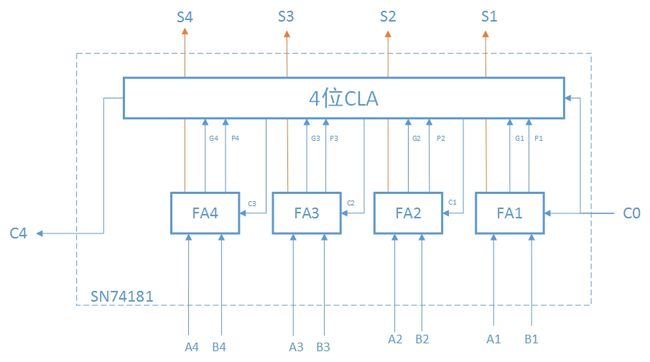
- 至此也就了解了基本的并行思想
- 然而多个SN74181之间仍然需要串行,,嗯哼,我猜你想到了什么。没错,可以用同样方法来对多个SN74181进行并行化
- D1 = G4 + P4·G3 + P4·P3·G2 + P4·P3·P2·G1
- T1 = P4·P3·P2·P1
- 则 C4 = D1 + T1·C0
- C8 = D2 + T2·D1 + T2·T1·C0
- C12 = D3 + T3·D2 + T3·T2·D1 + T3·T2·T1·C0
- C16 = D4 + T4·D3 + T4·T3·D2 + T4·T3·T2·D1 + T4·T3·T2·T1·C0
- 和之前很是对称的形式,只不过D和T是由G和P来生成 ,而G和P是直接由A和B来生成。实际上实现的逻辑电路完全一样,但是
- 前者CLA提前生成的是FA之间的进位信号,我们称之为组内信号
- 而此时提前生成的是SN74181之间的进位信号 ,称为组间信号
- 我们称此时实现的逻辑电路为成组先行进位(Block Carry Look Ahead,BCLA)链
- SN74182就是一个BCLA部件。
- 注意和SN74181的含义并不对称
- 等等我就不画图了,基本思路知道就好,按理可以无限的并行下去,但问题是1)我们不一定需要那么多位的运算,2)虽然是模块化 设计但避免不了复杂度的提高,不过这种越往上并行所需要的部件就越少,就部件数量来说并不会增加很多。
浮点数运算
- 这个就很简单
加减
- 按部就班的来,不过我想你也应该有思路
- 1、对阶:使两个操作数 阶码相同
- 2、尾数求和:对尾数进行加减运算
- 3、规格化:规格化运算的结果
- 4、舍入:为保证精度,考虑尾数右移的时候丢失的数值是否需要舍入(相当于十进制下的四舍五入)
- 5、溢出判断:上溢下溢还是没溢出
- 列举一下舍入的策略
- 截断法:直接舍弃丢失的数值
- 0舍1入法:丢失0就直接丢弃,丢失1就置最低位为1(对原码所言)。补码下自然应是“1舍0入”了)
- 恒置1法:也叫“冯·诺依曼舍入法”,无论丢失0或1,永远置最低位为1。简单但是误差大
- 查表舍入法:用ROM存一张表,以尾数的最低K位和丢失的最高位作为地址,查找出的数值来代替尾数的最低K位。提前设计好。由于读取ROM要比直接进行加法快,所以速度快。但又增加了硬件。
乘除
- 自己想象怎么算。嗯,很简单吧。
- 1、阶码相加、减
- 2、尾数相乘、除
- 3、规格化
- 4、舍入处理
- 5、溢出判断
天哪终于写完了。有错误的地方望指正。