msgpack 原理
存储/压缩
对于无符号整型:
----------- <128,则直接1个字节;
---------- [128,255], 则{0xcc, N} 2个字节表示
--------------[256,65535], 则{0xcd, N} 3个字节表示。(因为N介于[256,65535], 所以需要2个字节; 总共3个字节)
--------------[65536, 2^31-1] {0xce, N}--------------5个字节
--------------> uint32_max时,{0xcf, N}----------9个字节。
从这里看, 对于较小值,有压缩效果, 否则pack之后可能长度比原值更长。 这里的0xcc, 0xcd, 0xce, 0xcf高位都为1,同时表示后面还有多少个字节时用来表示同一个整数的。
对于有符号整型, 稍微更复杂一些,前置字节以0xdX开头。
msgpack的序列化最终都归结到基本类型, 如bool, char, int, double等; 在msg/type/下提供了list、string、set、map、queue的支持。
因此, 如果使用了第三方容器, 且自己的类又封装了该第三方容器, 则该类不能被msgpack序列化。
对自定义类的序列化支持, 需要使用宏 MSGPACK_DEFINE(member1, member2, ...) 的形式, 且: member必须为上述的基本类型,或者由基本类型组合得到的类且该类有MSGPACK_DEFINE的类型。
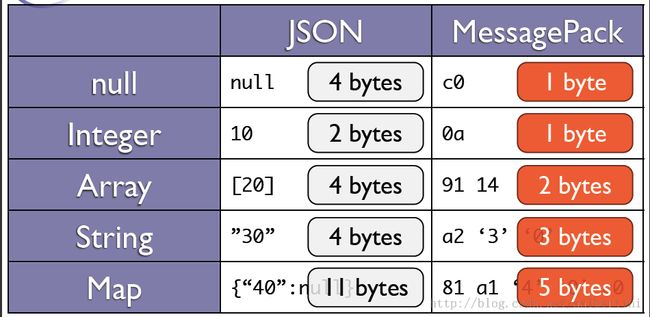
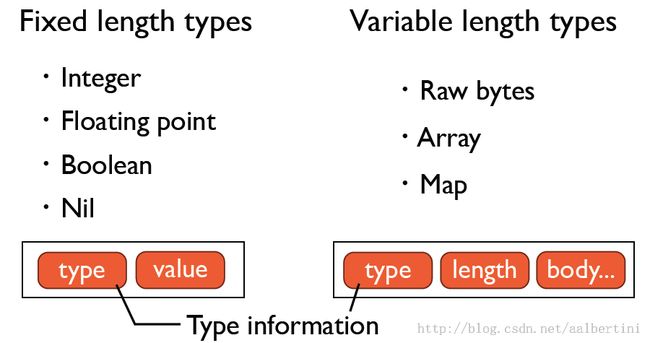
type定死了, 比如之前提到的0xcc, 0xcd等。
对于用户自定义类型,应该就是Raw bytes,length表示raw bytes的长度, 后续时该对象序列化的具体内容。
msgpack无法反射。 无法从一段buffer中自动反序列化得到正确的对象。 调用者必须明确指定类型才能反序列化成功。
msgpack的通常顺序是反序列化得到一个msgpack::obj, 然后再主动convert为用户指定的类型。
protobuf压缩比msgpack好。 且更方便灵活。 protobuf序列化性能应该稍差,因为protobuf的varint比msgpack的复杂。
protobuf自动生成代码有利:节省时间, skema足够灵活; 有弊:某些接口功能不够灵活或者缺接口。
msgpack只需要在类中加一个宏即可实现序列化支持。(也是有限制的,见第一个标红段)
上述两图片来自:
http://www.myexception.cn/open-source/1618388.html