MapReduce 工作机制
本文主要内容
- MapReduce作业的执行流程
- 错误处理机制
- 作业调度机制
- Shuffle和排序
- 任务执行
1.MapReduce任务执行总流程
一个MapReduce作业的执行流程是:代码编程--->job configuration--->提交作业--->Mapper任务的分配执行--->处理中间结果--->Reduce任务分配执行--->完成。
如下图:(援引google 图片)
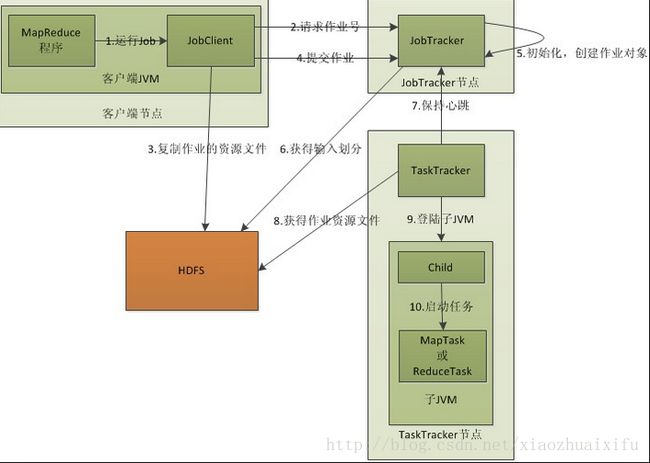
涉及4个独立的实体:
- 客户端:编写代码,作业配置与提交
- JobTracker:初始化作业,分配作业,与TaskTracker通过 heartbeat 信号进行通信,协调整个作业的执行
- TaskTracker:通过 heartbeat 信号与JobTracker通信,执行Map任务或者Reduce任务,上面只画了一个TaskTracker结点,实际上集群中包含很多
- HDFS:保存作业的数据、配置信息,保存作业的结果。
(一)提交作业
一个作业提交到Hadoop集群后,会自动化执行作业,用户只能监控执行情况和强制终止作业,别的什么也干不了,所以在提交作业之前应该把所有的配置参数都配置好:
包括如下这些参数:
- Map和Reduce的接口配置:各自派生自Mapper<k1,v1,k2,v2>和Reducer<k2,v2,k3,v3>,注意k2,v2的类型对应。
- 输入输出路径:具体的代码:
FileInputFormat.addInputPath( job, new Path(args[0]) ); //输入路径 FileOutputFormat.setOutputPath( job, new Path(args[1]) ); //输出路径
这两个路径是作为程序的参数传递进去的。还有其他的类型设置,比如输入输出格式类,输入输出key,value类的格式等等。
这里给出一个典型的配置:
Configuration conf = getConf();
conf.set("name", args[2]);
Job job = new Job(conf, "Test_2"); //任务名
job.setJarByClass(Test_2.class); //指定Class
FileInputFormat.addInputPath( job, new Path(args[0]) ); //输入路径
FileOutputFormat.setOutputPath( job, new Path(args[1]) ); //输出路径
job.setMapperClass( Map.class ); //调用上面Map类作为Map任务代码
job.setReducerClass ( Reduce.class ); //调用上面Reduce类作为Reduce任务代码
job.setOutputFormatClass( TextOutputFormat.class );
job.setOutputKeyClass( Text.class ); //指定输出的KEY的格式
job.setOutputValueClass( Text.class ); //指定输出的VALUE的格式
配置完成后就可以运行作业了。
下面给出提交作业的详细流程:
作业提交的关键函数:JobClient对象中submitJobInternal方法调用submitJob()方法,执行job,不给出代码,只阐述详细步骤:
- 通过JobTracker对象的getNewJobId()方法从JobTracker处获取当前作业的ID号
- 检查作业相关路径,如果输出路径没有指定或者路径已经存在,则作业提交失败,返回错误信息并退出。
- 计算作业的输入划分,将划分信息写入Job.split文件。
- 将作业资源---JAR文件、配置文件、输入划分文件复制到HDFS上。
- 调用JobTracker对象的submitJob()方法来真正提交作业。
(二)初始化作业
客户端调用JobTracker对象的submitJob()方法后,JobTracker会把此调用放入内部的TaskScheduler变量中,默认调度方法是JobQueueTaskScheduler,即FIFO调度方法,后面将会谈到除了默认的调度方式之外还有支持多用户同时服务和集群资源公平共享的调度器(公平调度器)和容量调度器。
当这个客户作业被调度执行时,JobTracker会创建一个代表这个作业的JobInProgress对象,将任务的记录信息封装到这个对象中,以便跟踪任务的状态和进程。接着JobInProgress对象的initTask函数会对任务进行初始化操作:此步骤对应上图的第5步。
- 从HDFS中读取作业对应的job.split文件,得到输入数据的划分信息
- 创建Map任务和Reduce任务,根据input split的划分信息设置Map Task的任务数,而Reduce任务的数量是根据配置文件或者函数指定,如果在代码中没有显示指定,那么会根据JobConf中的map.reduce.tasks属性来设置Reduce Task的数量,然后将上述Map Task和Reduce Task分别放入nonRunningMapCache和nonRunningReduces中,以便JobTracker向TaskTracker分配任务时使用。
- 创建两个初始化Task,分别初始化Map和Reduce.
(三)任务分配
JobTracker和TaskTracker之间通过心跳机制进行通信完成任务分配,TaskTracker作为一个单独的JVM执行一个循环,周期性发送心跳(是否存活,是否准备接收新任务),JobTracker如果有待分配任务,会将分配信息封装在心跳通信的返回值中返回给TaskTracker。
(四) 执行任务
TaskTracker申请到新的任务之后,第一步,本地化任务,即将任务所需的数据,配置信息,程序代码从HDFS复制到TaskTracker本地,然后通过调用launchTaskForJob()启动任务,该方法又会调用lauchTask()方法启动任务,lauchTask()方法先为任务创建本地目录,然后启动TaskRunner,TaskRunner会启动新的JAVA虚拟机来执行每个任务。
(五)更新任务执行进度和状态
由MapReduce作业分割成的每个任务中都有一组计数器,它们对任务执行过程中的进度组成事件进行计数,由计数器发送状态信息给TaskTracker,同时TaskTracker通过心跳机制将任务的状态报告给JobTracker,由它产生一个全局的作业统计信息。
2.错误处理机制
(一)硬件故障
若发生了JobTracker机器故障,这是单点故障,最严重,目前来说这个解决机制不成熟,若是TaskTracker故障,那么着属于正常情况,JobTracker会将此故障的TaskTracker结点从等待任务调度的TaskTracker集合中删除,并且要求此结点上的任务返回,若此结点正在执行mapping任务,那么JobTracker会重新要求其他TaskTracker结点重新执行此任务,若此结点正在执行reducing任务,那么会重新执行未完成的reduce任务。
(二)任务失败
若用户代码缺陷,导致死循环或者进程崩溃,导致任务在执行过程中抛出了异常,此时任务JVM会自动退出,发送错误消息,写入Log日志,TaskTracker将此任务标记为失败。将任务计数器减1,以便申请新任务,那么接收到心跳信号的JobTracker会重新分配该任务的执行,避免将此任务分配给原来执行失败的结点,如果任务失败了4次(可配置),那么整个作业失败。
3.作业调度机制
默认才用FIFO调度算法,支持设置优先级,但是这是单用户调度算法, 不支持抢占优先级,从版本0.19.0之后支持公平调度器和容量调度器。
公平调度器才用作业池来管理作业,默认情况下,一个用户拥有独立的一个作业池,不管每个用户提交了多少作业,以使得每个用户拥有等同的获得集群资源的机会,支持作业优先级抢占,抢占不会导致作业失败,只会导致作业执行时间变长,公平调度器可以限制每个用户资源池并发执行作业的数量,这个可以限制一个用户一次提交大量作业导致大量的中间数据塞满硬盘空间。
4.Shuffle和排序
为了让Reduce可以并行处理Map结果,必须对Map的输出结果进行一定的排序和分割,这个过程就是Shuffle,这个过程包括在Map和Reduce两端,在Map端的Shuffle过程是对Map结果进行partition、sort、spill,然后将属于同一个划分的输出合并写在磁盘。Reduce端将各个Map送来的结果根据同一个划分进行合并,对合并的结果进行排序,最后交给Reducer处理。
....to be continue.