《大话数据结构》笔记之 第七章 图
一、图的定义
1、图(Graph)是由顶点的有穷非空集合和顶点之间边的集合组成,通常表示为:G(V,E),其中G表示一个图,V是图G中顶点的集合,E是图G中边的集合。它是一种多对多的数据结构。
2、线性表中把数据元素叫元素,树中将数据元素叫结点,在图中数据元素则称之为顶点(Vertex)。
3、线性表中可以没有数据元素,称为空表;树中可以没有结点,叫做空树;在图结构中,不允许没有顶点,在定义中,若V是顶点的集合,则强调了顶点集合V有穷非空。(注意:此处定义有争议,国内部分教材强调点集非空,但在http://en.wikipedia.org/wiki/Null_graph中提出点集可为空)
4、线性表中,相邻的数据元素之间具有线性关系;在树结构中,相邻两层的结点具有层次关系;在图中,任意两个顶点之间都可能有关系,顶点之间的逻辑关系用边来表示,边集可以是空的。
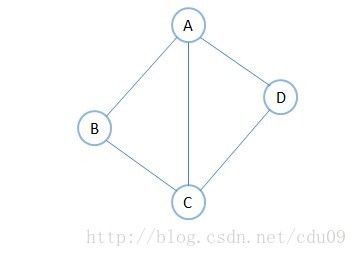
5、无向边与无向图:若顶点vi到vj之间的边没有方向,则称这条边为无向边(Edge),用无序偶(vi,vj)来表示。如果图中任意两个顶点之间的边都是无向边,则称该图为无向图。如下图就是一个无向图,由于是无方向的,所以连接顶点A与D的边,既可以表示成无序偶(A,D),也可以表示成(D,A)。定义为G1={V1,E1},其中V1={A,B,C,D},E1={(A,B),(B,C),(C,D),(D,A),(A,C)}。
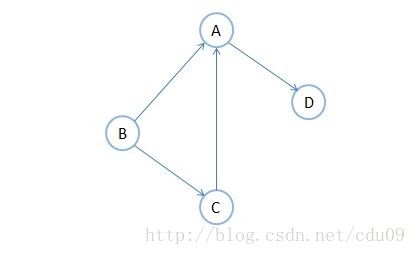
6、有向边与有向图:若从顶点vi到vj之间的边有方向,则称这条边为有向边,也称为弧(Arc),用有序偶<vi,vj>来表示,其中vi称为弧尾,vj称为弧头。如果图中任意两个顶点之间的边都是有向边,则称该图为有向图。下图就是一个有向图,其中<A,D>就表示弧,注意不能写成<D,A>。定义为:G2={V2,E2},其中V2={A,B,C,D},E2={<B,A>,<B,C>,<C,A>,<A,D>}。
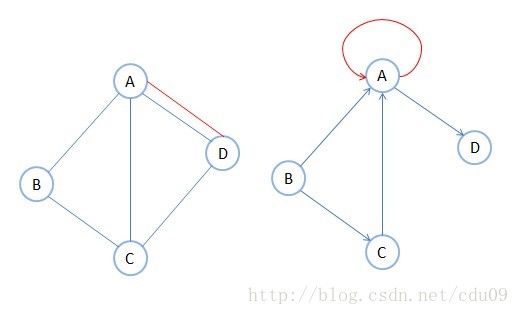
7、简单图:在图中,若不存在顶点到其自身的边,且同一条边不重复出现,则称这样的图为简单图。下面的两个图都不是简单图。
8、无向完全图:在无向图中,如果任意两个顶点之间都存在边,则称该图为无向完全图。含有n个顶点的无向完全图有n * (n-1) / 2条边。如下图。
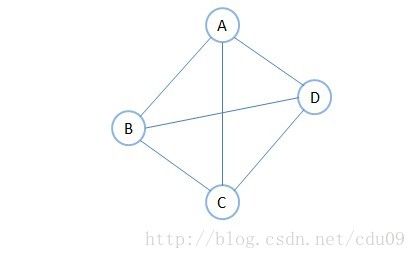
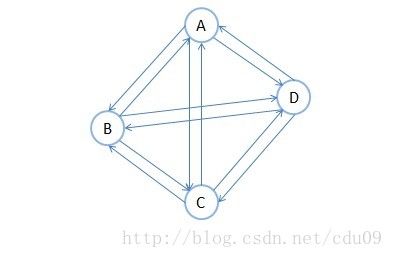
9、有向完全图:在有向图中,如果任意两个顶点之间都存在方向互为相反的两条弧,则称该图为有向完全图。含有n个顶点的有向完全图有n * (n-1)条边。如下图。
10、稀疏图和稠密图:有很少条边或弧的图称为稀疏图,反之称为稠密图。这里的稀疏和稠密都是相对而言的。通常认为边或弧数小于n*logn(n是顶点的个数)的图称为稀疏图,反之称为稠密图。
11、网:有些图的边或弧具有与它相关的数字,这种与图的边或弧相关的数叫做权(Weight);这种带权的图通常称为网(Network)。如下图。

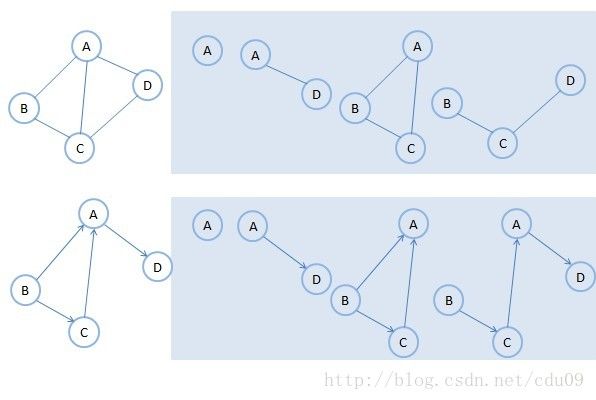
12、子图:假设有两个图G1=(V1,E1)和G2=(V2,E2),如果V2⊆V1且E2⊆E1,则称G2为G1的子图(Subgraph)。如下淡蓝色底纹的图均为左侧无向图或有向图的子图。
二、图的顶点与边之间的关系
1、对于无向图G=(V,E),如果边(v1,v2)∈E,则称顶点v1和v2互为邻接点(Adjacent),即v1和v2相邻接。边(v1,v2)依附于顶点v1和v2,或者说边(v1,v2)与顶点v1与v2相关联。顶点v1的度(Degree)是和v1相关联的边的数目,记为TD(v1)。如下图顶点A与B互为邻接点,边(A,B)依附于顶点A与B上,顶点A的度是3,各个顶点度的和为3+2+3+2=10,此图的边数是5,发现,边数其实就是各顶点度数和的一半,多出的一半是因为重复两次记数。简记为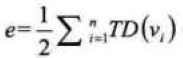 。
。
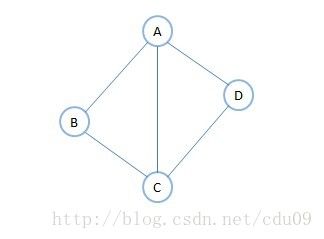
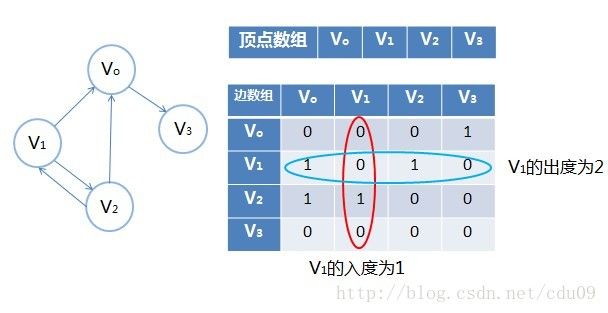
2、对于有向图G=(V,E),如果弧<v1,v2>∈E,则称顶点v1邻接到顶点v2,顶点v2邻接自顶点v1。弧<v1,v2>和顶点v1,v2相关联。以顶点v1为头的弧的数目称为v1的入度(InDegree),记为ID(v1);以v1为尾的弧的数目称为v1的出度(OutDegree),记为OD(v1);因此顶点v1的度为TD(v1)=ID(v1)+OD(v1)。如下图,顶点A的入度为2,出度为1,所以顶点A的度为2+1=3;此有向图的弧有4条,各顶点的出度和为1+2+1+0=4,各顶点的入度和为2+0+1+1=4,所以得到![]()
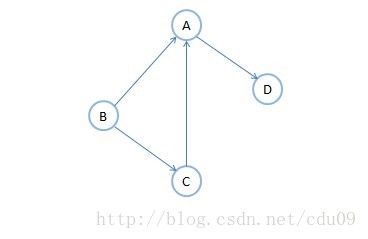
3、无向图G=(V,E)中从顶点v1到顶点v2的路径是一个顶点序列(v1=vi,0,vi,1,......,vi,m=v2),其中(vi,j-1,vi,j)∈E,1≤j≤m。如下图的左图的顶点B到顶点D的四种不同的路径。如果G是有向图,则路径也是有向的,顶点序列应该满足<vi,j-1,vi,j>∈E,1≤j≤m。如下图的右图顶点B到顶点D有两种路径,而顶点A到B就不存在路径。
4、路径的长度是路径上的边或弧的数目。如上图的右图的路径长度分别是2和3。
5、第一个顶点到最后一个顶点相同的路径称为回路或环(路径最终回到起始点)。序列中顶点不重复出现的路径称为简单路径。除了第一个顶点和最后一个顶点之外,其余顶点不重复出现的回路,称为简单回路或简单环。如下图的红线(实线)部分都构成环,左侧的环因第一个顶点和最后一个顶点都是B,而C、D、A没有重复出现,所以是一个简单环。而右侧的环由于顶点C的重复就不是简单环了。
三、连通图相关术语
1、在无向图G中,如果从顶点v1到顶点v2有路径,则称v1和v2是连通的。如果对于图中任意两个顶点vi、vj∈V,vi和vj都是连通的,则称G是连通图(ConnectedGraph)。下图的左图是无向非连通图,而右图是无向连通图。
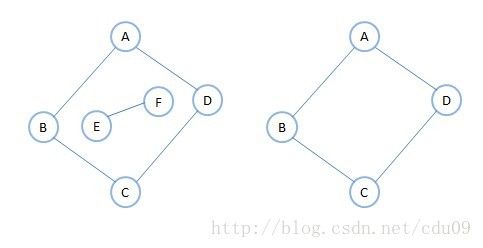
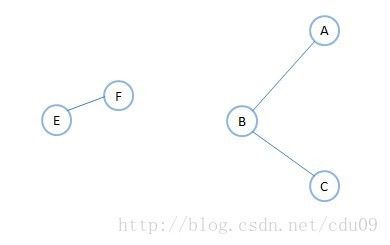
2、无向图中的极大连通子图称为连通分量。强调:
- 首先要是子图。
- 子图要是连通的。
- 连通子图含有极大顶点数。
- 具有极大顶点数的连通子图包含依附于这些顶点的所有边。
上图中左图虽然不是连通图,但是它有两个连通分量,即上图中的右图和下图中的左图,因为下图中的右图不满足连通子图的极大顶点数,所以不是上图中左图的连通分量。
3、在有向图G中,如果对于每一对vi、vj∈V,vi≠vj,从vi到vj和从vj到vi都存在路径,则称G是强连通图。有向图中的极大强连通子图称做有向图的强连通分量。
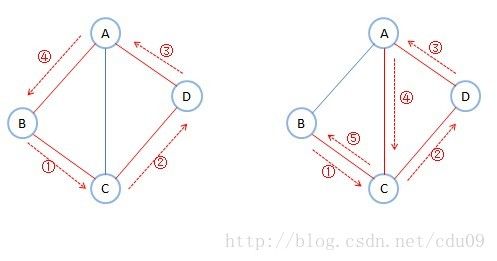
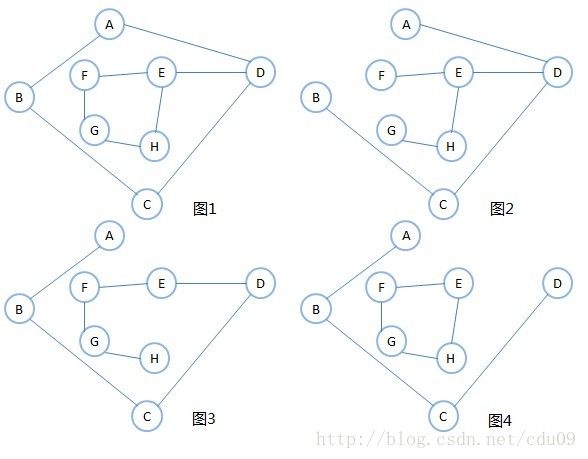
4、连通图的生成树定义:一个连通图的生成树是一个极小的连通子图,它含有图中全部的n个顶点,但只有足以构成一棵树的n-1条边。如下图的图1不是生成树,当去掉两条构成环的边后,比如图2或图3,就满足n个顶点,n-1条边且连通的定义,图2和图3都是一棵生成树。所以:如果一个图有n个顶点和小于n-1条边,则是非连通图,如果多于n-1条边,则必定构成一个环,因为这条边使得它依附的那两个顶点之间有了第二条路径,比如图2和图3,随便加哪两顶点的边都将构成环。不过有n-1条边并不一定是生成树,比如图4。
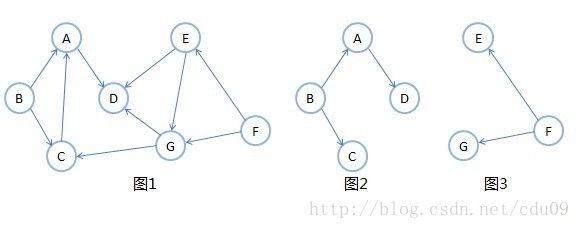
5、如果一个有向图恰有一个顶点的入度为0,其余顶点的入度均为1,则是一棵有向树。所谓入度为0其实就相当于树中的根结点,其余顶点入度为1就是说树的非根结点的双亲只有一个。一个有向图的生成森林由若干棵有向树组成,含有图中全部顶点,但只有足以构成若干棵不相交的有向树的弧。如下图所示,其中图1是一个有向图,去掉一些弧后,分解为两棵有向树,如图2和图3,且这两棵有向树就是图1有向图的生成森林。
四、图的存储结构之邻接矩阵
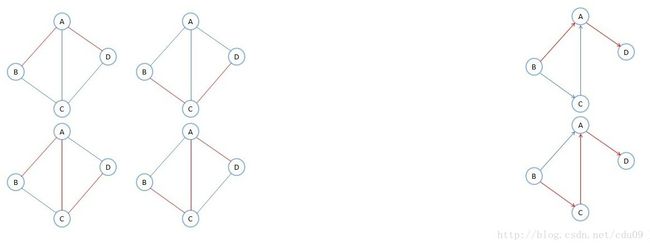
1、从图的逻辑结构定义来看,图上任何一个顶点都可被看成是第一个顶点,任一顶点的邻接点之间也不存在次序关系。如下面的四张图,它们其实是同一个图,只是顶点的位置不同。
2、因为任意两个顶点之间都可能存在联系,因此无法以数据元素在内存中的物理位置来表示元素之间的关系(内存物理位置是线性的,图的元素关系是平面的)。可以用多重链表来描述,但是纯粹用多重链表导致的浪费是无法想像的(如果各个顶点的度数相差太大,就会造成巨大的浪费)。
3、因为图是由顶点和边或弧两部分组成,合在一起比较困难,所以应该分为两个结构来分别存储。图的邻接矩阵(Adjacency Matrix)存储方式是用两个数组来表示图。顶点因为不区分大小、主次,所以用一个一维数组存储图中顶点信息;而边或弧由于是顶点与顶点之间的关系,所以用一个二维数组(称为邻接矩阵)存储图中的边或弧的信息。
4、设图G有n个顶点,则邻接矩阵是一个n * n的方阵,定义为:
无向图邻接矩阵实例,如下图,顶点数组为vertex[4]={V0,V1,V2,V3},边数组arc[4][4]为对称矩阵(0表示不存在顶点间的边,1表示顶点间存在边)。所谓对称矩阵就是n阶矩阵的元满足a[i][j]=a[j][i](0<=i,j<=n)。即从矩阵的左上角到右下角的主对角线为轴,右上角的元与左下角相对应的元全都是相等的。而且还可以发现在这条轴上的数据全都是0,表示这是一个简单图,不存在到自身的边。
而且对于无向图来说,顶点的度就是这个邻接矩阵中该顶点所在行或列的所有数值之和,比如顶点v0的度为0+1+1+1=3。所以有了这个二维数组组成的对称矩阵,要判定任意两顶点是否有边就变成判断二维数组中某个元素是否为1的问题了;要知道某个顶点的度,其实就是这个顶点Vi在邻接矩阵中第i行(或第i列)的元素之和;求顶点Vi的所有邻接点就是将矩阵中第i行元素扫描一遍,arc[i][j]为1就是邻接点。
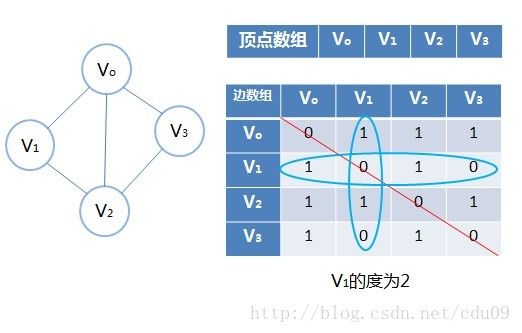
有向图邻接矩阵实例,如下图,可见顶点数组vertex[4]={V0,V1,V2,V3},弧数组arc[4][4]也是一个矩阵,但因为是有向图,所以这个矩阵并不对称,例如由V1到V0有弧,得到arc[1][0]=1,而V0到V1没有弧,因此arc[0][1]=0。还可以发现顶点V1的入度正好是第V1列各数之和;而出度即是该行的各数之和。
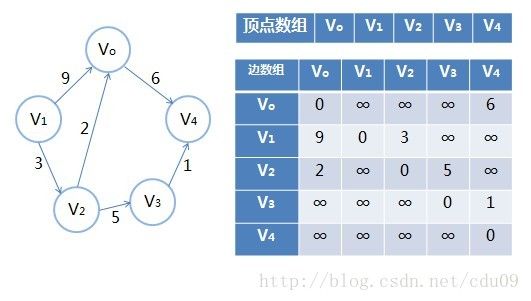
5、设图G是网图,有n个顶点,则邻接矩阵是一个n * n的方阵,定义如下,其中Wij表示(vi,vj)或<vi,vj>上的权值。∞表示一个计算机允许的、大于所有边上权值的值,即一个不可能的极限值。
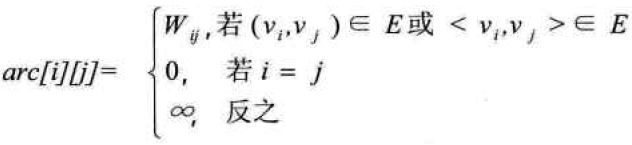
有向网图邻接矩阵实例,如下图
6、图的邻接矩阵存储的结构代码如下:
#define GRAPH_MAX_VERTEX_SIZE 100 // 最大顶点数
#define INFINITY 65535 // 用65535来代表∞
typedef char VertexType; // 顶点类型
typedef int EdgeType; // 边上的权值类型或用来表示是否有边
typedef struct Graph
{
VertexType vexs[GRAPH_MAX_VERTEX_SIZE]; // 顶点表
EdgeType arc[GRAPH_MAX_VERTEX_SIZE][GRAPH_MAX_VERTEX_SIZE]; // 邻接矩阵,可看作边表
int numVertexs, numEdges; // 图中当前的顶点数和边数
}Graph;
7、建立无向网图的邻接矩阵表示的代码如下,从中可以得到n个顶点和e条边的无向网图的创建,时间复杂度为O(n+n²+e),其中对邻接矩阵Garc的初始化消耗了O(n²)的时间。
/**
* 建立无向网图的邻接矩阵表示,有向图与无向图等的建立方式与之大同小异
* @param graph:指向图结构的指针
*/
void CreateGraph(Graph *graph)
{
int i, j, k, w;
printf("输入顶点数和边数,分别用空格分隔:");
scanf("%d %d", &(graph->numVertexs), &(graph->numEdges)); // 接收输入的顶点数和边数
for(i = 0; i < graph->numVertexs; i++) // 读入顶点信息,建立顶点表
{
printf("输入第%d个顶点信息:", i + 1);
fflush(stdin); // 清空键盘输入缓冲区
scanf("%c", &(graph->vexs[i]));
}
for(i = 0; i < graph->numVertexs; i++)
{
for(j = 0; j < graph->numVertexs; j++)
{
graph->arc[i][j] = INFINITY; // 邻接矩阵初始化
}
}
for(k = 0; k < graph->numEdges; k++) // 读入numEdges条边,建立邻接矩阵
{
printf("输入边(vi,vj)上的下标i,下标j和权w,分别用空格分隔:");
fflush(stdin); // 清空键盘输入缓冲区
scanf("%d %d %d", &i, &j, &w);
graph->arc[i][j] = w;
graph->arc[j][i] = graph->arc[i][j]; // 因为是无向图,矩阵对称
}
}
8、对于边数相对顶点较少的图,这种结构是存在对存储空间的极大浪费的。如下图。

五、图的存储结构之邻接表
1、由于对于边数相对顶点较少的图,邻接矩阵这种结构存在对存储空间的极大浪费,因为它采用了二维数组来存储边或弧信息,而数组的特点是直接就分配了预先指定大小的空间,要不就造成空间浪费,要不就造成空间不足,所以会存在这些问题,所以可以考虑把数组与链表相结合的存储方法来存储,这称为邻接表(AdjacencyList)。邻接表的处理办法:
- 图中顶点用一个一维数组存储(也可以用单链表来存储,不过数组可以较容易地读取顶点信息,更加方便),对于顶点数组中,每个数据元素还要存储指向第一个邻接点的指针。
- 图中每个顶点vi的所有邻接点构成一个线性表,由于邻接点的个数不定,用单链表存储,无向图称为顶点vi的边表,有向图则称为顶点vi作为弧尾的出边表。
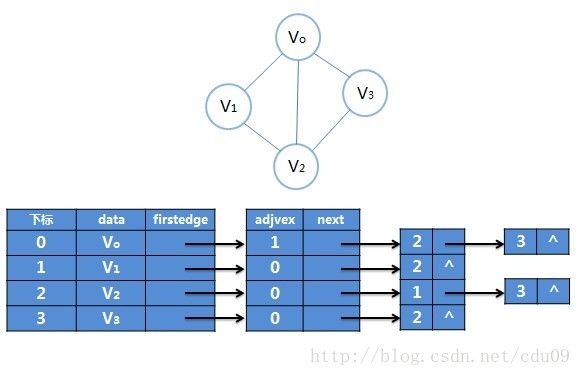
2、无向图的邻接表结构图示:其中顶点表的各个结点由data和firstedge两个域表示,data是数据域,存储顶点的信息,firstedge是指针域,指向边表的第一个结点,即此顶点的第一个邻接点;边表结点由adjvex和next两个域组成,adjvex是邻接点域,存储某顶点的邻接点在顶点表中的下标,next则存储指向边表中下一个结点的指针。如下图:
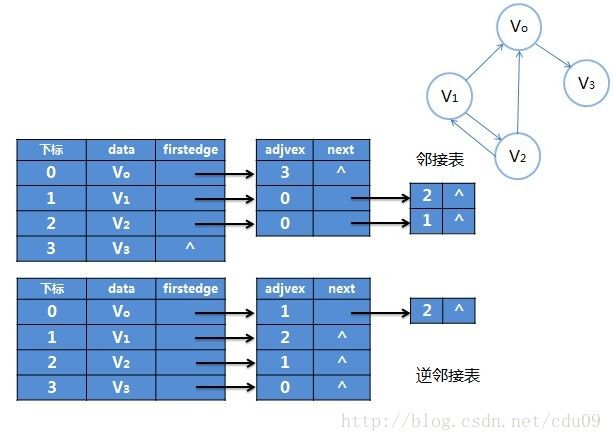
3、有向图的邻接表结构图示:如下图所示,是有向图的邻接表和逆邻接表,要注意的是有向图由于有方向, 是以顶点当弧尾来存储出边表的,这有利于得到每个顶点的出度。为了便于确定顶点的入度或以顶点为弧头的弧,可以建立一个有向图的逆邻接表,即对每个顶点vi都建立一个链接为vi为弧头的表。
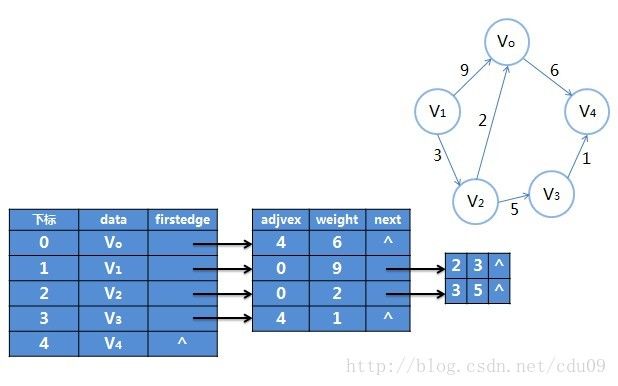
4、网图的邻接表:对于带权值的网图,可以在出边表结点定义中再增加一个weight的数据域,存储权值信息即可,如下图所示。
5、图的邻接表存储结构定义代码如下:
#define GRAPH_MAX_VERTEX_SIZE 100 // 最大顶点数
typedef char VertexType; // 顶点类型
typedef int EdgeType; // 边上的权值类型
// 边表结点结构定义
typedef struct EdgeNode
{
int adjvex; // 邻接点域,存储该顶点在顶点表中对应的下标
EdgeType weight; // 用于存储权值,对于非网图可以不需要
struct EdgeNode *next; // 链表指针域,指向下一个邻接点
}EdgeNode;
// 顶点表结点结构定义
typedef struct VertexNode
{
VertexType data; // 顶点域,存储顶点信息
EdgeNode *firstEdge; // 边表头指针
}VertexNode;
// 图结构定义
typedef struct Graph
{
VertexNode adjList[GRAPH_MAX_VERTEX_SIZE];
int numvertexs, numEdges; // 图中当前顶点数和边数
}Graph;
6、无向图的邻接表的创建代码:其中应用了单链表创建中的头插法,对于n个顶点和e条边来说,时间复杂度是O(n+e)。
/**
* 建立无向图的邻接表表示,有向图与网图等的建立方式与之大同小异
* @param graph:指向图结构的指针
*/
void CreateGraph(Graph *graph)
{
int i, j, k;
EdgeNode *e;
printf("输入无向图的顶点数和边数,分别用空格分隔:");
scanf("%d %d", &(graph->numVertexs), &(graph->numEdges)); // 接收输入的顶点数和边数,并赋值
// 读入顶点信息,建立顶点表
for(i = 0; i < graph->numVertexs; i++)
{
printf("输入第%d个顶点信息:", i + 1);
fflush(stdin); // 清空键盘输入缓冲区
scanf("%c", &(graph->adjList[i].data));
graph->adjList[i].firstEdge = NULL; // 将该顶点指向第一个边表结点的指针置为空
}
// 建立边表
for(k = 0; k < graph->numEdges; k++)
{
printf("输入边(vi, vj)的两个顶点在顶点数组中的下标i、下标j,分别用空格分隔:");
fflush(stdin); // 清空键盘输入缓冲区
scanf("%d %d", &i, &j);
e = (EdgeNode *)malloc(sizeof(EdgeNode)); // 生成边表结点
if(!e)
{
exit(1);
}
e->adjvex = j; // 邻接序号为j
e->next = graph->adjList[i].firstEdge; // 将边表结点e的next指针指向当前顶点上firstEdge指针指向的边表结点
graph->adjList[i].firstEdge = e; // 将当前顶点的firstEdge指针指向边表结点e,头插法
// 因为是无向图,所以需要将(vi, vj)表示的边反过来再执行一遍,设置下标为j的顶点的边表
e = (EdgeNode *)malloc(sizeof(EdgeNode));
if(!e)
{
exit(1);
}
e->adjvex = i;
e->next = graph->adjList[j].firstEdge;
graph->adjList[j].firstEdge = e;
}
}
六、图的存储结构之十字链表
1、对于有向图来说,邻接表是有缺陷的,它解决了出度却不容易了解入度,反之逆邻接表解决了入度却不容易了解出度,把邻接表和逆邻接表整合在一起,即成了有向图的一种存储方法:十字链表(Orthogonal List)。
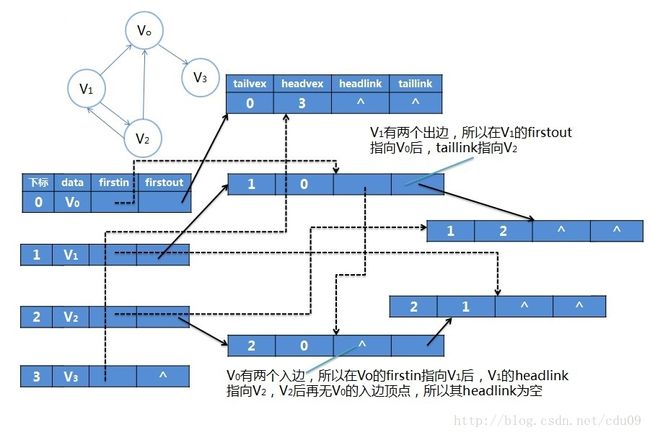
2、重新定义顶点表结点结构如下图,其中firstin表示入边表头指针,指向该顶点的入边表中第一个结点;firstout表示出边表头指针,指向该顶点的出边表中的第一个结点。

接着重新定义的边表结点结构如下图,其中tailvex是指弧起点在顶点表的下标,headvex是指弧终点在顶点表中的下标,headlink是指入边表指针域,指向终点相同的下一条边;taillink是指出边表指针域,指向起点相同的下一条边,如果是网,可以再增加一个weight域来存储权值。注意这里的tailvex和headvex一起表示的是一条边,而不再像邻接表中是表示一个点。

3、如下图是十字链表的存储图示,其中实线箭头表示的就是邻接表,而虚线箭头就是此图的逆邻接表的表示。
4、建立一个有向网图的十字链表表示完整代码如下:
/***************************************************************************/
/** 图的存储结构之十字链表 **/
/***************************************************************************/
#include <stdio.h>
#include <stdlib.h>
#define GRAPH_MAX_VERTEX_SIZE 100 // 最大顶点数
typedef char VertexType; // 顶点类型
typedef int EdgeType; // 边上的权值类型,对于非网图可以不需要
// 边表结点结构定义
typedef struct EdgeNode
{
int tailvex; // 一条狐的弧尾所在顶点在顶点表中的下标
int headvex; // 一条狐的弧头所在顶点在顶点表中的下标,与tailvex一起构成一条弧
EdgeType weight; // 用于存储权值,对于非网图可以不需要
struct EdgeNode *headlink; // 指向入边表中的下一个入边结点
struct EdgeNode *taillink; // 指向出边表中的下一个出边结点
}EdgeNode;
// 顶点表结点结构定义
typedef struct VertexNode
{
VertexType data; // 顶点域,存储顶点信息
EdgeNode *firstin; // 入边表头指针
EdgeNode *firstout; // 出边表头指针
}VertexNode;
// 图结构定义
typedef struct Graph
{
VertexNode ortList[GRAPH_MAX_VERTEX_SIZE]; // 顶点表
int numVertexs, numEdges; // 有向网图中当前顶点数和弧数
}Graph;
/**
* 创建有向网图的十字链表表示
* @param graph:指向有向网图结构的指针
*/
void CreateGraph(Graph *graph)
{
int i, j, k, w;
EdgeNode *e;
printf("输入有向网图的顶点数和弧数,分别以空格分隔:");
scanf("%d %d", &(graph->numVertexs), &(graph->numEdges)); // 接收输入的顶点数和弧数,并赋值给有向网图结构中相关变量
// 建立顶点表
for(i = 0; i < graph->numVertexs; i++)
{
printf("输入第%d个顶点信息:", i + 1);
fflush(stdin); // 清空键盘输入缓冲区
scanf("%c", &(graph->ortList[i].data)); // 接收输入的顶点信息
graph->ortList[i].firstin = graph->ortList[i].firstout = NULL;
}
// 建立十字链表
for(k = 0; k < graph->numEdges; k++)
{
printf("输入弧<vi, vj>的两个顶点在顶点数组中的下标i、下标j,以及该弧上的权值,分别用空格分隔:");
fflush(stdin); // 清空键盘输入缓冲区
scanf("%d %d %d", &i, &j, &w);
e = (EdgeNode *)malloc(sizeof(EdgeNode)); // 生成边表结点
if(!e)
{
exit(1);
}
e->tailvex = i;
e->headvex = j;
e->weight = w;
// 输入的弧是<vi, vj>,那么对于顶点vi来说,就是它的出边结点
// 则采用头插法使顶点vi的出边域指向该出边结点
e->taillink = graph->ortList[i].firstout;
graph->ortList[i].firstout = e;
// 输入的弧是<vi, vj>,那么对于顶点vj来说,就是它的入边结点
// 则采用头插法使顶点vj的入边域指向该入边结点
e->headlink = graph->ortList[j].firstin;
graph->ortList[j].firstin = e;
}
}
int main()
{
Graph graph;
CreateGraph(&graph);
return 0;
}
5、十字链表的好处就是把邻接表和逆邻接表整合在了一起,这样既容易找到以V
i
为尾的弧,也容易找到以V
i
为头的弧,因而容易求得顶点的出度和入度。它除了结构复杂一点外,其创建图算法的时间复杂度是和邻接表相同的,在有向图的应用中,十字链表是非常好的数据结构模型。
七、图的存储结构之邻接多重表
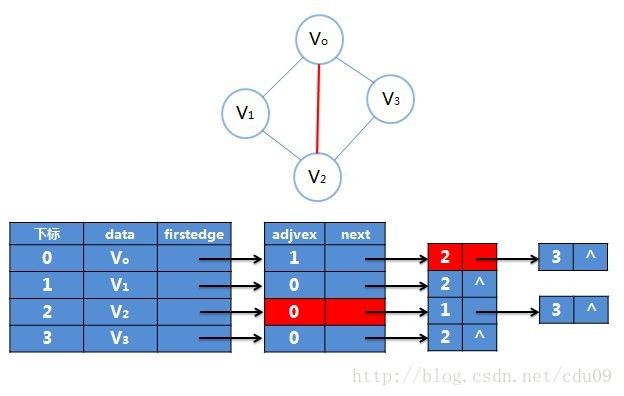
1、十字链表是邻接表对有向图的优化存储结构,而对于无向图的邻接表,如果在无向图的应用中,关注的重点是顶点的话,那么邻接表是不错的选择,但如果更关注的是边的操作,比如对已经访问过的边做标记,或者删除某一条边等操作,邻接表就显得不那么方便了。如下图:若要删除(V0,V2)这条边,就需要对邻接表结构中边表的两个结点进行删除操作。
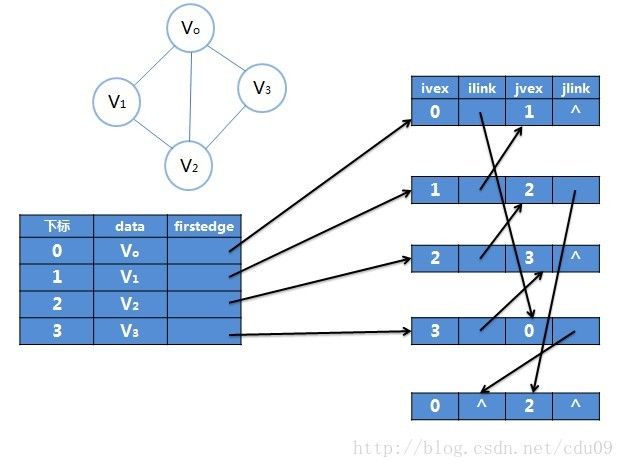
因此,也可以仿照十字链表的方式,对边表结构进行改装,重新定义的边表结构如下:其中ivex和jvex是与某条边依附的两个顶点在顶点表中的下标。ilink指向依附顶点ivex的下一条边,jlink指向依附顶点jvex的下一条边。也就是说在邻接多重表里边,边表存放的是一条边,而不是一个顶点。

采用邻接多重表的存储结构示意图如下:
2、建立无向网图的邻接多重表表示完整代码如下:
/***************************************************************************/
/** 图的存储结构之邻接多重表 **/
/***************************************************************************/
#include <stdio.h>
#include <stdlib.h>
#define GRAPH_MAX_VERTEX_SIZE 100 // 最大顶点数
typedef char VertexType; // 顶点类型
typedef int EdgeType; // 边上的权值类型,对于非网图可以不需要
// 定义边表结构
typedef struct EdgeNode
{
int ivex; // 边(vi, vj)所在顶点vi在顶点表中的下标
struct EdgeNode *ilink; // 指向依附顶点ivex的下一个边表结点
int jvex; // 边(vi, vj)所在顶点vj在顶点表中的下标
struct EdgeNode *jlink; // 指向依附顶点jvex的下一个边表结点
EdgeType weight; // 边上的权值,对于非网图可以不需要
}EdgeNode;
// 定义顶点表结构
typedef struct VertexNode
{
VertexType data; // 顶点数据
EdgeNode *firstEdge; // 指向依附该顶点的第一个边表结点
}VertexNode;
// 定义无向网图结构
typedef struct Graph
{
VertexNode adjMultiList[GRAPH_MAX_VERTEX_SIZE]; // 顶点表
int numVertexs, numEdges; // 无向网图当前顶点数和边数
}Graph;
/**
* 建立无向网图的邻接多重表表示
* @param graph:指向图结构的指针
*/
void CreateGraph(Graph *graph)
{
int i, j, k, w;
EdgeNode *e;
printf("输入无向网图的顶点数和边数,分别用空格分隔:");
scanf("%d %d", &(graph->numVertexs), &(graph->numEdges)); // 接收输入的顶点数和边数,并赋值
// 读入顶点信息,建立顶点表
for(i = 0; i < graph->numVertexs; i++)
{
printf("输入第%d个顶点信息:", i + 1);
fflush(stdin); // 清空键盘输入缓冲区
scanf("%c", &(graph->adjMultiList[i].data));
graph->adjMultiList[i].firstEdge = NULL; // 将该顶点指向依附该顶点的第一个边表结点的指针置为空
}
// 建立邻接多重表
for(k = 0; k < graph->numEdges; k++)
{
printf("输入边(vi, vj)的两个顶点在顶点数组中的下标i、下标j,以及该边上的权值w,分别用空格分隔:");
fflush(stdin); // 清空键盘输入缓冲区
scanf("%d %d %d", &i, &j, &w);
e = (EdgeNode *)malloc(sizeof(EdgeNode));
if(!e)
{
exit(1);
}
e->ivex = i;
e->jvex = j;
e->weight = w;
// 边(vi, vj)依附于顶点vi和vj,
// 那么采用头插法将顶点vi指向依附于顶点vi的第一个边结点的指针域的指针指向边结点e
e->ilink = graph->adjMultiList[i].firstEdge;
graph->adjMultiList[i].firstEdge = e;
// 同理,采用头插法将顶点vj指向依附于顶点vj的第一个边结点的指针域的指针指向边结点e
e->jlink = graph->adjMultiList[j].firstEdge;
graph->adjMultiList[j].firstEdge = e;
}
}
int main()
{
Graph graph;
CreateGraph(&graph);
return 0;
}
八、
图的存储结构之
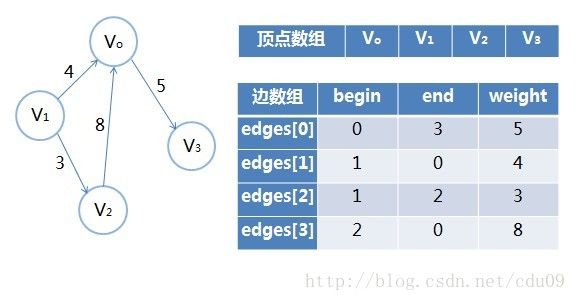
边集数组
1、边集数组是由两个一维数组构成,一个是存储顶点的信息,另一个是存储边的信息,这个边数组每个数据元素由一条边的起点下标(begin)、终点下标(end)和权(weight)组成。如下图。