CUDA最佳实践(一)
近期开始学习CUDA编程,需要阅读很多资料,为了便于整理复习,特将阅读笔记记录,以备后用。
这一系列文章是根据NVIDIA公司官方文档《CUDA C Best Practices》的内容来进行整理的,由于笔者刚开始进行CUDA的学习,而并行语言的学习不如串行语言如C、C++那样容易入门,因此理解错误之处在所难免,欢迎读到错误的各位批评指正。
1. 学习目的
CUDA是一个C语言的扩充,学习它的目的是利用CUDA将程序中的可并行部分交由GPU来完成,以达到CPU与GPU协同工作的效果,极大提升程序性能。
2. 优化过程
学习CUDA的一个非常有用的作用在于程序员可以对现有的C/C++程序进行改写,将其中适合在GPU上运行的并行部分代码挖掘出来,改写代码使得它们可以在GPU上运行,从而极大地提升程序的运算性能。将串行代码转化为并行代码的过程是迭代的,简单来说,每一次迭代可以划分为4个相对独立的过程:
1、分析(Assess)
2、并行化(Parallelize)
3、优化(Optimize)
4、部署(Deploy)
这四个过程合起来称作APOD,CUDA为每个过程提供了解决方案以改善程序性能。APOD是一个循环的过程:对程序进行初步分析并行优化后,可以继续运用上述手段,分析程序中的可并行化段,利用CUDA对该段代码进行改写,优化改写的程序,最后将改写后的代码部署到原有程序中。这一过程可以形象地用下图来进行表示:
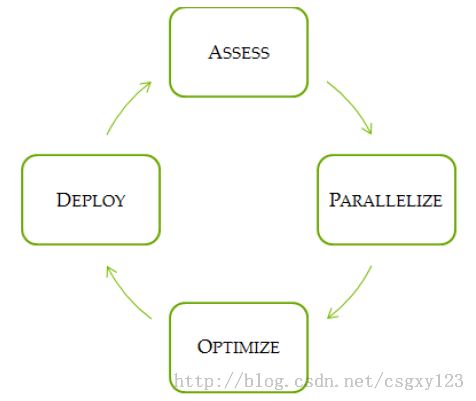
并行化过程是使用CUDA对原有C/C++程序进行初步改写,CUDA提供了众多的并行库供程序员调用,例如cuBLAS、cuFFT以及Thrust等,除此之外,还可以运用一些预处理指令来优化编译器的行为。
优化是对并行化后的程序重复进行APOD的过程,以使程序达到更好的性能。
在部署阶段,程序员需要比较改写后与改写前程序运算的结果,以验证改写的正确性。验证完毕后,将改写程序加入到原有项目当中。
分析过程主要是找出程序性能提升的极限,找出它们的方法是运用所谓的Amdahl定理和Gustafson定理,这两个定理随后将会提到。
3. 异构计算
异构计算是指运用多种不同架构的处理器来完成计算任务,使用CUDA,我们可以协调CPU和GPU,让它们分工合作以达到计算的目的。
在CUDA中,CPU用主机(Host)来表示,GPU则用设备(Device)来表示。主机和设备之间是有一些区别的,这些区别的主要部分集中在线程模型和物理内存方面:
线程资源(Threading resources)
CPU所支持的同时运行的线程数是极其有限的,一个拥有4个6核心处理器的服务器处理器在同一时刻只能同时运行24个线程(注意是同一时刻!),而现代NVIDIA GPU则可以支持同一时刻数千个活动线程同时运行。
线程(Threads)
在CPU中线程切换由于涉及到上下文(Context)的改变,代价很大。与之相比,GPU中的线程则非常轻巧,切换几乎没有代价。简言之,CPU的设计初衷是为了最小化线程切换的延迟,而GPU的设计理念是为了处理大量同时运行的轻量级线程以最大化吞吐量。
内存(RAM)
主机和设备都拥有各自的物理内存,它们之间通过PCI-E总线来交换信息。为了使用CUDA,数据必须通过PCI-E总线从主机传输到设备上。传输的开销是非常可观的,因此,为了获得更好的性能表现,数据重用是非常重要的。简单来说,数据应当尽可能久地保存在设备上以备运算所用。
4. 性能分析
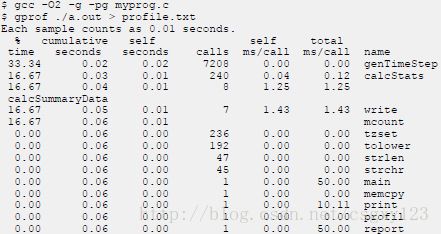
在很多项目中,完成了绝大多数工作任务的是相对较少的一部分核心代码。使用性能分析器,开发人员可以识别这样的热点代码,找到瓶颈,进而有针对性地对代码进行优化。性能分析的工具非常多,典型的工具如gprof便是其中之一,它是一款Linux平台上的开源性能分析器。下面则是其分析结果的部分截图:
4.1 强标度与Amdahl定律(Strong Scaling and Amdahl's Law)