Overlay & HWC on MDP -- MIMO Display软硬整合 .
本文做为Android Display系列的一部分,着重软硬整合设计,不涉及Framebuffer MDP驱动。
平台Android,MSM8k。
转载请注明出处。
详细地,需要结合代码看。
概述
Android显示系统SurfaceFlinger使用Overlay和HWC(Hardware composer)完成Surface Layer的硬件合成。Overlay和HWC表现为两个HAL,为芯片方案制造商留了实现余地。
因为Overlay也时常被称为hardware composition,为了避免混淆,本文中Overlay专指Android Display Overlay HAL,对应liboverlay.so;HWC专指SurfaceFlinger使用的硬件合成器HAL,对应hwcomposer.msm8xxxx.so。
Qualcomm MSM8k系列平台的MDP4.x(Mobile Display Platform)提供了硬件Overlay的功能,Android Overlay HAL与这个Overlay硬件相对应;当然,为了与上段照应,需要说明的是,MDP并不存在一个实现HWC的专门硬件,HWC也是在Overlay上实现的;体现在Android软件中,HWC HAL是建立在Overlay HAL基础上的,是使用Overlay HAL来实现的。
因此,再次,准确地说,提供硬件合成功能的是模块是Overlay,是MDP Overlay硬件的体现;而HWC则是SurfaceFlinger使用Overlay HAL的一个桥梁。
Overlay并非仅仅由SurfaceFlinger得到Surface后就不再经过SurfaceFlinger而使用硬件直接输出;从函数调用上看似乎是这样的,但是实际情形却非如此。硬件合成仅是合成的一种手段,合成的结果输出destination还是必须受控,因而也必须纳入SurfaceFlinger的输出管理范畴。
Overlay硬件平台
MSM8k上目前有MDP4.0, MDP4.1, MDP4.2三个硬件版本,主要是合成能力和管道数目的区别。通常,一个RGB pipe和一个VG pipe组成一个pipe pair,前者是对应UI RGB图像数据,后者对应Camera或Video的RGB或YUV数据,两个pipe输入到一个LayerMixer0用于合成;额外的,LayerMixer可能还有BF(Border Fill) pipe,用于视频按比例显示时屏幕多余边框填充,这个多用于Ext TV或HDMI输出的时候。MDP4有7个pipe,3个LayerMixer,其中LayerMix0可以配置有多达两个RGB pipe,两个VG pipe,一个BF pipe输入,完成5 Layer合成。
上述pipe是LayerMixer的输入元素,LayerMixer的输出对应到LCD,TV,HDMI等,当然不是直接对应,而是由DMA channel和上述模块的控制器相连。三个LayerMixer对应的三个输出使用一般是约定的,当然,软件层面上MDP driver中对每个管道的目标LayerMixer也做了固定的配置。三个输出一般标为Primary, Seconday, Extra,对应的DMA通道为DMA_P, DMA_S, DMA_E。
更直观地,参见Android Overlay on QC MDP4平台要点简记
由于LayerMixer0提供了多达5个Layer的合成能力,所以当没有Camera或Video优先使用它的时候,它被充分利用来做Layer的Hardware composition。提前且概要地,这儿必须清楚说明的是,LayerMixer0使用的两种情景:
当有Camera或Video的时候,SurfaceView对应的Layer为HWC_OVERLAY,这时该Layer对应一个VG pipe,而其余HWC_FRAMEBUFFER Layer经3D GPU render到Framebuffer后,该Framebuffer输入一个pipe(RGB1--base layer?),和VG pipe经LayerMixer0合成输出。
当没有Camera或Video的时候,如果UI Layer即HWC_FRAMEBUFFER Layer小于等于3个且都满足图像格式条件,那么这些Layer的CompositionType属性会被修改为HWC_OVERLAY,为每个Layer分配pipe,经LayerMixer0合成经DMA_P输出,这就是HWC。由于BF pipe能力条件的限制,不使用其做HWC,而RGB1做预留的base layer Framebuffer使用,所以标榜的4-layer mdp composition support实际只能接受SurfceFlinger的3个Layer做合成,也就是SurfaceFlinger的属性debug.mdpcomp.maxlayer=3。当超过3个Layer的时候,由于管道数量的限制,不能够再使用LayerMixer0,就使用GPU render,也即每个Layer->draw。当然GPU render也算是一个Hardware Composition,CompositionType方式的其中之一就是GPU。
Overlay HAL结构
MIMO输入输出代码结构设计,简单地讲,分为流路控制和数据流动两部分;Overlay及构建在其上的hwcomposer都是采用这种流路控制和数据流动的结构。
Overlay有多种应用场景,具体设计上描述为Overlay State。就是说如果允许管道任意灵活组合使用的话,可以有很多种花样的应用,但是这儿预先设计好这么些应用场景,应用场景一定,需要的管道类型和数目随之确定,管道连接的LayerMixer及其输出Video驱动控制器也确定。
Overlay State具体实现使用模板类OverlayImpl<P0, P1, P2>,P0, P1, P2是3个pipe,最多可以使用3个pipe。每个pipe对应的类是模板类GenericPipe<int PANEL>,PANEL指定该pipe合成后图像输出目的,从而也决定其使用的LayerMixer。另外地,每个OverlayImpl<P0, P1, P2>模板类的3个管道可能需要图像旋转,所以有可能使用3个Rotator。此处的P0, P1, P2只是逻辑索引,并不具体是MDP的管道索引,根据使用规格需求,从MDP管道中为之动态分配。
hwcomposer也设计了几个封装类与Overlay应用场景对应,屏蔽了场景功能的具体实现。hwcomposer中定义的应用场景比Overlay提供的场景还要少,仅是有限几个。大致结构图如下:
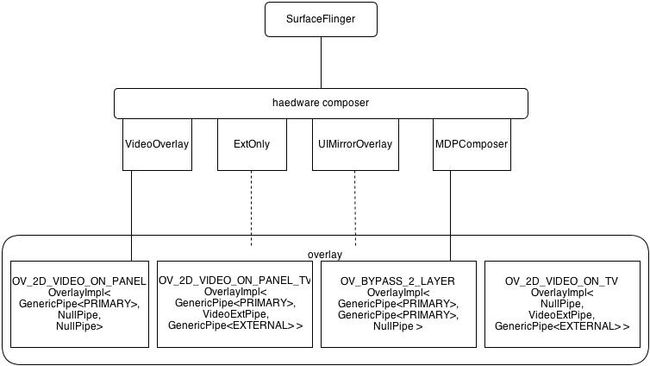
由于overlay场景太多,因此只示意了四个,OV_BYPASS_x_LAYER可以是1,2,3个,分别对应1个,2个或3个HWC_FRAMEBUFFER Layer和base layer Framebuffer合成的情形。
hwc_prepare的设计逻辑过于固化和简单,成了一种基于if-else判断的优先配置方式,宽阔的城堡顶部建了个鸟笼似的小阁楼;应该设计成Policy或RouteState的形式更具备可扩展性。
Overlay进行流路控制的接口是commit,然后调用其具体实现类和MDP封装类的相关接口,一个调用栈(适当向内核驱动做了扩展)如下:
mdp4_overlay_set()
msmfb_overlay_set()
ioctl(fb, MSMFB_OVERLAY_SET)
overlay::mdp_wrapper::setOverlay()
MdpCtrl::set()
Ctrl::commit()
pipe::commit() -> GernericPipe<utils::PRIMARY>::commit()
OverlayImplBase::commit() -> OverlayImpl<>::commit()
Overlay::commit(overlay::utils::eDest)
Overlay提交数据的接口是queueBuffer,然后同样调用其具体实现类和MDP封装类的相关接口,一个调用栈(适当向内核驱动做了扩展)如下:
mdp4_overlay_play()
msmfb_overlay_play()
ioctl(fd, MSMFB_OVERLAY_PLAY, &od) msmfb_overlay_data.id is mdp_overlay.id is the kernel pipe index in kernel db returned by MdpCtrl.commit()
overlay::mdp_wrapper::play()
MdpData::play(int fd, uint32_t offset)
Data::play()
GenericPipe<PANEL>::queueBuffer(int fd, uint32_t offset)
OverlayImplBase::queueBuffer() -> OverlayImpl<>::(int fd, uint32_t offset, utils::eDest dest)
Overlay::queueBuffer(int fd, uint32_t offset, utils::eDest dest)
Camera或Video Overlay
Camera Overlay一般有两种实现模式,一种模式是V4L2不提供Overlay接口,在用户态把V4L2 buffer handle传递给Framebuffer,由Framebuffer Overlay Implementation完成合成;另一种模式是V4L2提供Overlay接口,可以把Video buffer在V4L2内核驱动中提交给Framebuffer Overlay内核驱动完成合成。QC MSM8k Overlay是采用的第一种模式实现,但是V4L2和Framebuffer驱动也提供了第二种模式的实现;第二种模式可参见Freescale处理器上Android Overlay的实现。
Camera的取景器PreviewDisplay Window是个SurfaceView,所在的Layer(HWC_OVERLAY)在UI Layer底下,但是UI layer会开个全透的区域露出这个HWC_OVERLAY Layer。
下面描述其合成过程。
3D GPU 绘制:所有的HWC_FRAMEBUFFER layers会首先经OpenGL 3D GPU绘制到back Framebuffer上;
OV_PIPE0配置:然后在setupHardwareComposer=> HWComposer::prepare=>hwc_prepare=>VideoOverlay::prepare中使用HWC_OVERLAY Layer参数设置OV_PIPE0分配的类型为Video/Graphic的MDP pipe;
OV_PIPE0提交:DisplayHardware::flip=>HWComposer::commit=>hwc_set=>VideoOverlay::draw提交HWC_OVERLAY Layer的图像数据到OV_PIPE0的内核VG pipe的工作队列中(单容量队列即可);
OV_PIPE3配置:DisplayHardware::flip => HWComposer::commit=> hwc_set=>eglSwapBuffers=> queueBuffer=> fb_post=>update_framebuffer中使用base layer back framebuffer参数配置OV_PIPE3即RGB1 pipe(注意base layer的特殊地位);
OV_PIPE3提交:当update_framebuffer真正提交图像数据到RGB1 pipe时,对应stage 0 for base layer(内核驱动)会启动MDP LayerMixer0进行Layers合成;
DMA传输:然后fb_post通过FBIOPUT_VSCREENINFO或PAN_DISPLAY启动DMA_P送合成好的图像经MIPI-DSI输出显示。
BufferFlip:queueBuffer后,该framebuffer即为front framebuffer,然后eglSwapBuffers会dequeueBuffer下一个Framebuffer做为back framebuffer。
此时Hardware Composer使用的是VideoOverlay@hwcomposer.msm8960.so对应的逻辑。VG pipe设置和提交的栈示例如下:
/system/lib/liboverlay.so (overlay::Overlay::commit(overlay::utils::eDest)+71)
/system/lib/liboverlay.so configPrimVid(hwc_context_t *ctx, hwc_layer_t *layer)
/system/lib/liboverlay.so VideoOverlay::configure(hwc_context_t *ctx, hwc_layer_t *, hwc_layer_t *)
/system/lib/hw/hwcomposer.msm8960.so (qhwc::VideoOverlay::prepare(hwc_context_t *, hwc_layer_list_t *)+xxx)
/system/lib/hw/hwcomposer.msm8960.so (qhwc::MDPComp::setup(hwc_context_t*, hwc_layer_list*)+163) for each pipe.
/system/lib/hw/hwcomposer.msm8960.so (qhwc::MDPComp::configure(hwc_composer_device*, hwc_layer_list*)+59)
/system/lib/hw/hwcomposer.msm8960.so hwc_prepare(hwc_composer_device_t *dev, hwc_layer_list_t* list)
/system/lib/libsurfaceflinger.so (android::HWComposer::prepare() const+9)
/system/lib/libsurfaceflinger.so (android::SurfaceFlinger::setupHardwareComposer()+127)
/system/lib/libsurfaceflinger.so (android::SurfaceFlinger::handleRepaint()+147)
/system/lib/libsurfaceflinger.so (android::SurfaceFlinger::onMessageReceived(int)+91)
/system/lib/liboverlay.so Overlay::queueBuffer(int fd, uint32_t offset, utils::eDest dest)
/system/lib/hw/hwcomposer.msm8960.so (qhwc::VideoOverlay::draw(hwc_context_t*, hwc_layer_list*)+xx) for each pipe.
/system/lib/hw/hwcomposer.msm8960.so static int hwc_set(hwc_composer_device_t *dev,hwc_display_t dpy,hwc_surface_t sur, hwc_layer_list_t* list)
/system/lib/libsurfaceflinger.so (android::HWComposer::commit() const+11)
/system/lib/libsurfaceflinger.so (android::DisplayHardware::flip(android::Region const&) const+59)
/system/lib/libsurfaceflinger.so (android::SurfaceFlinger::postFramebuffer()+61)
/system/lib/libsurfaceflinger.so (android::SurfaceFlinger::onMessageReceived(int)+103)
Base layer对应的RGB pipe设置和提交的栈示例从略。Base layer提交到RGB1时真正启动LayerMixer0的4-stage layer composition。
FB Layer Hardware Composition
当开启硬件(debug.sf.hw=1)合成且合成方式选择MDP时,属性debug.mdpcomp.maxlayer决定了可以使用的通道的个数,当前设置为3,因为RGB1 pipe预留为Camera或Video时的base layer使用,在全Framebuffer layer MDP合成情景下,RGB1对应的base layer是一个处于最顶端的全透明层。相关系统设置和属性如下:
在系统根目录文件 /systembuild.prop中,
debug.sf.hw=1
debug.egl.hw=1
debug.composition.type=mdp
debug.enable.wl_log=1
debug.mdpcomp.maxlayer=3
debug.mdpcomp.logs=0
其中CompositionType有 4种,debug.composition.type=dyn/c2d/mdp/cpu/gpu,dyn是根据c2d和mdp的硬件存在选择使用二者之一。
gpu/c2d/mdp可以释放cpu/gpu,减轻cpu/gpu的负担,但并不一定能使显示效果流畅。
SurfaceFlinger启动时会取debug.mdpcomp.maxlayer属性值记录在全局变量sMaxLayers中。相关代码如下:
782 sMaxLayers = 0;
783 if(property_get("debug.mdpcomp.maxlayer", property, NULL) > 0) {
784 if(atoi(property) != 0)
785 sMaxLayers = atoi(property);
786 }
当没有Camera/Video/HDMI/WFD等Overlay应用情景时,所有Layer都是HWC_FRAMEBUFFER的,MDP的LayerMixer0是闲置的,这时可以优化利用其来做Framebuffer Layer合成。由于管道数目限制的原因,只能合成小于等于sMaxLayers个Layers。多于3个的时候是否可以MDP合成其中的3个?可能需要考虑Layer buffer维度、格式、缩放、Z序等因素。当多于3个的时候,是遍历layer::draw使用GPU来绘制纹理到back framebuffer上的。
下面着重看少于等于3个Layer,MDP合成的情况。
首先,所有的Layer的compositiontype都是HWC_FRAMEBUFFER的;
然后SurfaceFlinger在setHardwareComposer时发现hwc_prepare没有别的优先的Overlay情景,最后的一个if分支就是使用MDP来做Layer合成;SurfaceFlinger会检查Layer的属性看是否满足使用MDP的条件,然后设置满足条件的Layer的属性[compositionType, flags] = (HWC_OVERLAY, MDPCOMP);这样SurfaceFlinger::composeSurfaces时,就不再通过layer::draw使用GPU来绘制;
PIPE配置:SurfaceFlinger为HWC创建工作集,为每个Layer分配并使用MDPComp::prepare配置每个pipe,如果有缩放需求,则会分配VG pipe,因为RGB pipe不支持缩放;有一个Layer则Overlay状态为BYPASS_1_LAYER,表示有1个Layer Bypass,不需要OpenGL绘制,同理2个Layer为BYPASS_2_LAYER,3个为BYPASS_3_LAYER;
PIPE提交:在DisplayHardware::flip中提交每个Layer的数据到管道,即MDPComp::draw() => Overlay::queueBuffer()。注意Layer图像数据是在PMEM/ASHMEM内存中而不是Framebuffer内存中,但仍物理连续或IOMMU映射连续,LayerMixerdraw可访问。MDPComp::draw完即提交数据到对应管道的单容量队列后,清layer->flags &= ~HWC_MDPCOMP标志;
在eglSwapBuffers时,真正做back & front Buffer的切换(准确地说双缓冲是切换,三缓冲是轮用)
OV_PIPE3配置:DisplayHardware::flip => HWComposer::commit=> hwc_set=>eglSwapBuffers=> queueBuffer=> fb_post=>update_framebuffer中使用base layer back framebuffer参数配置OV_PIPE3即RGB1 pipe;
OV_PIPE3提交:当update_framebuffer真正提交图像数据到RGB1 pipe时,对应stage 0 for base layer(内核驱动)会启动MDP LayerMixer0进行Layers合成;此时base layer是个最顶层的全透明Layer,不妨碍底层Layer的显示;
DMA传输:然后fb_post通过FBIOPUT_VSCREENINFO或PAN_DISPLAY启动DMA_P送合成好的图像经MIPI-DSI输出显示。
BufferFlip:queueBuffer后,该framebuffer即为front framebuffer,然后eglSwapBuffers会dequeueBuffer下一个Framebuffer做为back framebuffer。
HWC功能时,是MDPComp@hwcomposer.msm8960.so对应的逻辑,一个Layer对应的 pipe设置和提交的栈示例如下:
#00 pc 0000b0d0 /system/lib/liboverlay.so (overlay::Overlay::commit(overlay::utils::eDest)+71)
#01 pc 00005d16 /system/lib/hw/hwcomposer.msm8960.so (qhwc::MDPComp::prepare(hwc_context_t*, hwc_layer*, qhwc::MDPComp::mdp_pipe_info&)+577)
#02 pc 00006190 /system/lib/hw/hwcomposer.msm8960.so (qhwc::MDPComp::setup(hwc_context_t*, hwc_layer_list*)+163) for each pipe.
#03 pc 0000652c /system/lib/hw/hwcomposer.msm8960.so (qhwc::MDPComp::configure(hwc_composer_device*, hwc_layer_list*)+59)
#04 pc 000037ea /system/lib/hw/hwcomposer.msm8960.so hwc_prepare(hwc_composer_device_t *dev, hwc_layer_list_t* list)
#05 pc 0001ebba /system/lib/libsurfaceflinger.so (android::HWComposer::prepare() const+9)
#06 pc 00020df4 /system/lib/libsurfaceflinger.so (android::SurfaceFlinger::setupHardwareComposer()+127)
#07 pc 000212f4 /system/lib/libsurfaceflinger.so (android::SurfaceFlinger::handleRepaint()+147)
#08 pc 000222e8 /system/lib/libsurfaceflinger.so (android::SurfaceFlinger::onMessageReceived(int)+91)
/system/lib/liboverlay.so Overlay::queueBuffer(int fd, uint32_t offset, utils::eDest dest)
#00 pc 00006592 /system/lib/hw/hwcomposer.msm8960.so (qhwc::MDPComp::draw(hwc_context_t*, hwc_layer_list*)+85) for each pipe.
#01 pc 00003ae4 /system/lib/hw/hwcomposer.msm8960.so static int hwc_set(hwc_composer_device_t *dev,hwc_display_t dpy,hwc_surface_t sur, hwc_layer_list_t* list)
#02 pc 0001ed56 /system/lib/libsurfaceflinger.so (android::HWComposer::commit() const+11)
#03 pc 0001e57c /system/lib/libsurfaceflinger.so (android::DisplayHardware::flip(android::Region const&) const+59)
#04 pc 000209c6 /system/lib/libsurfaceflinger.so (android::SurfaceFlinger::postFramebuffer()+61)
#05 pc 00022474 /system/lib/libsurfaceflinger.so (android::SurfaceFlinger::onMessageReceived(int)+103)
Base layer对应的RGB pipe设置和提交的栈示例从略。重复地,Base layer提交到RGB1时真正启动LayerMixer0的4-stage layer composition。
HDMI / WFD
有机会待续。
LayerMixer0合成后图像经DMA_P输出时,在BLT模式和DIRECTOUT模式下LayerMixer0与DMA之间没有buffer;即使FB模式,也是一个Overlay buffer而未必是做为Framebuffer内存,当然这个Overlay buffer做为DMA_P输入传输给MIPI-DSI/LCDC。
[END]
[更正]
代码里找不到update_framebuffer函数了,fb_post简单了;
代码里也找不到设置OV_PIPE3和提交framebuffer数据到OV_PIPE3的部分了;
变为在驱动中做DMA时,合成且输出。