OpenCV图像处理
http://hahack.com/wiki/opencv-image.html
读写
读入
|
|
如果读入的是 jpg 格式的图片,默认会读入三个通道的数据。如果需要当做灰度图像读入,使用:
|
|
也可以先读入再转换成灰度图:
|
|
写入
|
|
展示
展示一幅 8U 图像
|
|
展示一幅 32F 的图像
需要先转成 8U 类型。例如:
|
|
访问像素
要获取 Mat 容器里的像素值,例如一幅图像里某个像素的亮度值,首先要求你得了解这幅图像的类型和通道数。
灰度图像访问单像素值
获取单通道灰度图(类型为8UC1)里像素点 (x,y) 的亮度值:
|
|
也可以这么写:
|
|
得到的 intensity.val[0] 将包含一个从 0~255 之间的数值。
彩色图像访问单像素值
对于 3 通道的 BGR 彩色图像,可以这么写:
|
|
浮点型的图像也以此类推,注意使用浮点型的变量保存即可。
遍历所有像素
如果要遍历所有像素,可以使用 C 语言的方式,先从数组第一行开始,遍历每一行。cv::Mat 类提供了一个访问图像一行的地址方法:ptr 函数,该函数为一个模板函数。
|
|
在系统底层,为了方便硬件解码,一幅二维图像可能会在每一行的末尾填补一个额外的像素,这个额外填补的像素不会被显示或储存,且它们所存储的值会被忽略,它们起到一个哨兵的作用。
但对于没有使用额外像素填补的图像,图像中的每个像素都是实际像素,因此可以把整幅图像直接当做一维数组来遍历每个元素,从而减轻了循环的开销。cv::Mat 类提供了 isContinuous 函数来检测是否属于这种情况。
|
|
另一种遍历像素的方法是使用 STL 风格的迭代器,如 cv::MatIterator_ 和 cv::MatConstIterator_:
|
|
也可以使用 iterator 类型,在 Mat_ 模板类里定义:
|
|
示例:
|
|
Mat 的迭代器是一个随机访问迭代器,因此支持完整的迭代器算术运算,如 std::sort() 等。
遍历并访问相邻像素
有时候需要在遍历图像的同时访问相邻的像素。例如,用于进行边缘增强的拉普拉斯算子的表达式为:
|
|
可使用三个指针来进行图像遍历,一个用于当前行,一个用于上面一行,一个用于下面一行:
|
|
图像通道
可以使用 cv::split 操作来将彩色图像分离成三个单通道图像,使用 cv::merge 操作可以重新将几个单通道图像合并成一个多通道图像。下面的程序演示了将一幅图像 image2 与另一幅图像 image1 的蓝色通道混合:
|
|
简单图像运算
图像叠加
- 简单叠加
|
|
- 带权叠加
|
|
- 标量叠加
|
|
- 带掩码叠加
|
|
当使用 mask 时,该操作只作用在对应的掩码位置不为 0 的像素上(mask 必须为单通道)。
其他操作
其他常用的操作,包括:
cv::substract:两个图像相减,支持 mask;cv::absdiff:两个图像的差的绝对值,支持 mask;cv::multiply:两个图像逐元素相乘,支持 mask;cv::divide:两个图像逐元素相除,支持 mask;- 按位操作
cv::bitwise_and、cv::bitwise_or、cv::bitwise_xor、cv::bitwise_not; cv::max和cv::min:求每个元素的最小值或最大值返回这个矩阵,并返回结果矩阵。cv::saturate_cast:确保值不会超出像素的取值范围(防止上溢和下溢)。
这些图像操作都要求参与运算的两幅图像大小相同。如果不符合这种情况,可以使用 ROI 。另外,因为这些运算都是逐元素进行的,因此可以在调用时直接把其中一张图像的变量直接作为输出变量。
更多的操作可以参考 矩阵操作速查表 。
感兴趣区域(ROI)
下面的程序演示了将一幅图像叠加到另一幅图像的一个感兴趣区域中。
|
|

叠加结果图
图像变换
图像缩放
OpenCV 提供了一个cv::resize() 函数,允许你指定新的图像大小,例如:
|
|
查找表
查找表是一种映射,可以将图像原来的像素的灰度值根据查找表指定的规则映射到另一个值。OpenCV 提供了 cv::LUT 来支持这种变换。
下面示例一个将图像反色的查找表变换:
|
|

反色结果图
阈值处理
阈值处理可以用来从图像中剔除低于或高于一定值的像素,其基本的思想是,给定一个数组和一个阈值,然后根据数组中的每个元素的值是低于还是高于阈值而进行一些处理。OpenCV 提供了 cv::threshold() 操作来进行阈值处理:
|
|
其中,阈值类型选项 type 可以是以下几种类型:
| 阈值类型 | 说明 | 对应的操作 |
|---|---|---|
cv::THRESH_BINARY |
二值阈值化 | dsti=(srci>T)?M:0 |
cv::THRESH_BINARY_INV |
反向二值阈值化 | dsti=(srci>T)?0:M |
cv::THRESH_TRUNC |
截断阈值化 | dsti=(srci>T)?M:srci |
cv::THRESH_TOZERO |
超过阈值被置于0 | dsti=(srci>T)?srci:0 |
cv::THRESH_TOZERO_INV |
低于阈值被置于0 | dsti=(srci>T)?0:srci |
各种阈值类型的操作结果可以参考下图:
| 将被阈值化的值和阈值 | 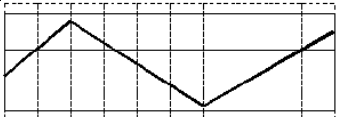 |
| 二值阈值化 |  |
| 反向二值阈值化 |  |
| 截断阈值化 |  |
| 超过阈值被置于0 |  |
| 低于阈值被置于0 |  |
示例:
|
|
形态学变换
膨胀
|
|
上面的 element 是结构元素,在这里用到了矩形结构元素。OpenCV 提供了几种形状的结构元素,可以通过 cv::getStructuringElement() 来定义:
|
|
其中,shape 包含几种形状:
- MORPH_Rect - 矩形结构元素;
- MORPH_Ellipse - 椭圆形结构元素;
- MORPH_CROSS - 十字形结构元素。
也可以自己定义一个形状,例如定义一个 “X” 形结构元素:
|
|
腐蚀
|
|
高级形态学变换
基于膨胀和腐蚀两种基本的形态学变换,可以组合成诸如开操作、闭操作、形态学梯度、顶帽变换、黑(底)帽变换等高级的形态学变换。OpenCV 提供 cv::morphologyEx() 操作,以进行更高级的形态学变换:
|
|
其中 op 可以是以下几种操作类型:
MORPH_OPEN- 开操作MORPH_CLOSE- 闭操作MORPH_GRADIENT- 形态学梯度MORPH_TOPHAT- “顶帽”MORPH_BLACKHAT- “黑帽”
开操作示例:
|
|
直方图
计算直方图
使用 cv::calHist 来计算直方图,得到的直方图将存放到一个 cv::MatND 类型的容器中。
|
|
用于灰度图像
|
|
用于彩色图像
|
|

原图

计算得到的直方图
直方图均衡化
在 OpenCV 中可以很方便的调用 cv::equalizeHist 来进行直方图均衡:
|
|
在其内部是使用了如下的查找表变换:
|
|
其中 p[i] 是灰度值小于或等于 i 的像素数量。p[i] 常被称为 累积直方图(Cumulative Histogram)。

均衡化结果

均衡化后的直方图
反投影直方图
可以利用直方图来检测一幅图像中是否含有目标图像类似的内容,所使用的算法称为反投影(back projection)。在 OpenCV 中,相应的操作是 cv::calcBackProject 操作 :
|
|
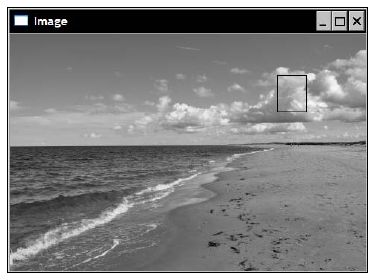
例如,检测上图中类似云朵的部分,可以先使用 ROI 截取该图像中有云朵的部分作为目标图像:
|
|
之后提取 ROI 的直方图,用到了上面编写的 Histogram1D 类:
|
|
对其做归一化处理,得到一个概率分布:
|
|
然后可以对整幅图像做反投影变换,将图像中每个像素点的灰度值用归一化后的直方图的相应概率值来代替。
|
|
得到如下的概率图,其中颜色越黑的部分表示概率越大:

可以进一步使用阈值操作,将可能为云朵的像素突出出来:
|
|
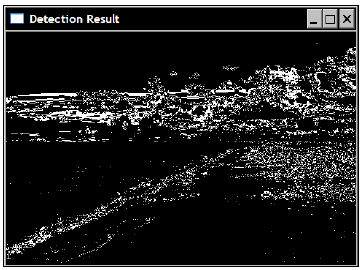
可以将这个算法封装成一个类 ObjectFinder 。
空间滤波
低通滤波
均值模糊
OpenCV 提供 cv::blur() 函数来对图像进行低通滤波,从而达到平滑图像的作用。
|
|
示例:
|
|
均值模糊的卷积核形式如下:
|
|
原图:

结果:

高斯模糊
一种加权平均的模糊算法。OpenCV 提供 cv::blur() 函数来对图像进行高斯模糊。
|
|
示例:
|
|
高斯模糊的卷积核根据所选的 σ 值 sigmaX 和 sigmaY 的不同而不同。值越大,则模糊效果越明显。可以通过 cv::getGaussianKernel()函数获取与 sigma 值对应的卷积核。
结果:

下采样
下采样的步骤是:
- 将 Gi 与高斯内核卷积:
- 将所有偶数行和列去除。显而易见,结果图像只有原图的四分之一。
OpenCV 提供了 cv::pyrDown() 函数来完成这两步操作:
|
|
示例:
|
|
下采样常被应用于缩小图像:如果要将一幅图像缩小一倍,直接隔一行或一列去掉图像的行和列是不够的——直接去掉后,解析度会降低,如果不修改图像的空间频率,就会造成空间混淆。因此,正确的做法是先进行低通滤波,去除高频分量后再进行下采样。下文将介绍的高斯金字塔就是迭代地使用下采样技术将图像逐步缩小成一个金字塔。
上采样
上采样不是下采样的逆操作,因为在下采样过程中原图的部分信息将会丢失。
类似的,还有一种上采样操作(不是下采样的逆操作!)。步骤为:
- 首先,将图像在每个方向扩大为原来的两倍,新增的行和列以 0 填充 (0) 。
- 使用指定的滤波器进行卷积,获得 “新增像素” 的近似值。
OpenCV 提供了 cv::pyrUp() 函数进行下采样操作。
|
|
上采样常和下采样一起用来创建图像金字塔。
中值滤波
OpenCV 提供 cv::medianBlur() 函数进行中值滤波:
|
|
示例:
|
|
中值滤波并不是一个线性滤波,因此它并不能用一个核矩阵来表示。然而,它也是通过相邻像素来决定每一个像素的值的:一个像素的值,等于其相邻像素的值的中值。中值滤波的一个典型应用是滤除椒盐噪声:
原图:

结果:

中值滤波还有用一个优点:可以保留图像边缘的锐利程度。然而,它会影响图像的材质等细节特征。
高通滤波
高通滤波常用来提取图像中变化比较明显的地方,例如图像边缘。
Sobel 滤波
Sobel 滤波是一种方向滤波器,它只影响竖直方向或水平方向的图像频率。该方向取决于卷积核的形状。OpenCV 提供了 cv::Sobel() 函数来进行 Sobel 滤波:
|
|
构造一个竖直方向的 Sobel 滤波器示例:
|
|
构造一个水平方向的 Sobel 滤波器示例:
|
|
注意上面两个用例都是使用 CV_8U 这种图像类型。在这种情况下,0 值对应的像素灰度值将为 128 ,负值对应的像素将用暗一些的颜色,而正值对应的像素将用亮一些的颜色。最终的效果就如一些照片处理软件的“浮雕”特效一样:
竖直 Sobel 滤波器的结果:
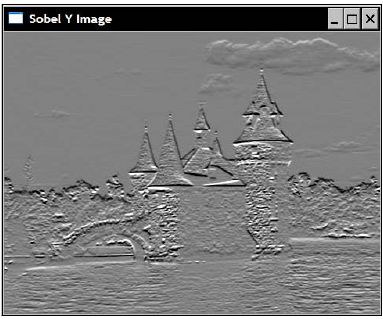
水平 Sobel 滤波器的结果:

两种形式的卷积如下:
|
|
|
|
由于 Sobel 滤波器的核包含正值和负值,因此更常用的图像类型是使用16位符号整型(CV_16S)。下面将用这种类型来提取图像边缘。
边缘提取
- 计算 Sobel 算子的 L1 范数:
|
|
- 使用
convertTo()方法将得到的 L1 范数转换成一幅图像,0 值对应的像素点为白色,而更高的值对应的像素点将用更暗的颜色表示:
|
|
得到如下的结果:

- 对其再进一步做阈值处理,得到一幅线条清晰的二值图像:
|
|

原理
从数学上讲,sobel 滤波器计算的是图像的梯度信息,即:
由于梯度是一个二维向量,因此它有范数和方向。梯度的范数可以用来表示变化的幅度,通常使用欧几里得范数(称为 L2 范数 )来求解:
然而,在图像处理中,我们通常只需要计算两个方向的一阶导数的绝对值的和,即 L1 范数 ,这个值与 L2 范数非常接近,但运算量要小很多:
梯度向量总是指向图像中最陡峭的变化方向,这意味着在图像中,梯度方向将与图像中的边缘垂直,并且从暗的部分指向亮的部分。梯度方向可以通过下面的公式得到:
OpenCV 提供了 cv::cartToPolar() 函数来获取梯度方向:
|
|
默认情况下,得到的方向是用辐度角来表示的,通过再添加一个参数 true 可以得到几何角。
拉普拉斯变换
拉普拉斯滤波器是另一个高通线性滤波器。OpenCV 提供了 cv::Laplacian() 函数来计算图像的拉普拉斯变换。
|
|
一个封装好的拉普拉斯变换类 LaplacianZC 如下:
|
|
使用示例:
|
|
结果:

拉普拉斯变换同样可以用来提取边缘:
边缘提取
图像的经过拉普拉斯变换后,可以利用结果的 zero-crossings 提取边缘:
- 遍历 Laplacian 结果图像,比对当前像素点和其左邻的像素点;
- 如果两个像素点灰度值差值大于一个阈值,且正负号不同,则当前像素点为一个 zero-crossing 点;
- 否则,对下一个像素重复同样的测试。
|
|

拉普拉斯变换可以提取出丰富的边缘信息,但不足在于也对噪声很敏感。
原理
拉普拉斯变换定义为 x 、 y 两个方向的二阶导数的和:
它最简单的形式是用如下的 3x3 卷积核逼近的矩阵:
|
|
图像卷积
OpenCV 提供了 cv::filter2D 函数来进行图像卷积。使用它前只需先构造一个卷积核。
|
|
例如,用源图像减去拉普拉斯滤波结果可以增强图像细节,相应的卷积核形式为:
|
|
实现如下:
|
|
图像金字塔
一个图像金字塔是一系列图像的集合:
- 所有图像来源于同一张原始图像;
- 通过梯次向下采样获得,直到达到某个终止条件才停止采样。
有两种类型的图像金字塔常常出现在文献和应用中:
- 高斯金字塔(Gaussian pyramid): 基于下采样;
- 拉普拉斯金字塔(Laplacian pyramid): 用来从金字塔低层图像重建上层未采样图像。
高斯金字塔
高斯金字塔为一层一层的图像,层级越高,图像越小。如下图所示,每一层都按从下到上的次序编号, 层级 (i+1) (表示为 Gi+1 尺寸小于层级 i(Gi) )。

前面已经了解到,缩小图像可以使用下采样技术。而高斯金字塔就是基于 下采样 实现的:通过对输入图像 G0 (原始图像) 下采样多次就会得到整个金字塔。
OpenCV 提供了一个函数 cv::buildPyramid() 用来从一幅图像创建高斯金字塔:
|
|
示例:
|
|
结果:

拉普拉斯金字塔
下采样是一个丢失信息的函数。为了恢复原来(更高分辨率)的图像,我们需要获得下采样操作中丢失的信息,这些信息可以通过上采样来预测。这些数据形成了拉普拉斯金字塔(又叫做预测残差金字塔)。下面是拉普拉斯金字塔的第 i 层的数学定义:
这里的 Gi 和 Gi+1 分别代表第 i 层和第 i+1 层的高斯金字塔图像; UP() 操作将原始图像中位置为 (x, y) 的像素映射到目标图像的 (2x+1, 2y+1) 位置;符号 ⨂ 代表卷积操作, ς 是 n×n 的高斯核。OpenCV 提供的函数 cv::pyrUp() 实现的功能就如 UP(Gi+1)⨂ςn×n 所定义。因此,我们可以使用 OpenCV 直接进行拉普拉斯运算:
OpenCV 没有提供直接生成拉普拉斯金字塔的函数,但自己实现一个也很容易:
|
|
以上两个重载函数分别根据一张图片或一系列图片生成拉普拉斯金字塔。金字塔的最顶层是一张低分辨率近似。
示例:
|
|
结果:

图像分割
分水岭
OpenCV 提供了 cv::watershed() 函数来实现分水岭操作。
|
|
一个封装好的 WatershedSegmenter 类如下:
|
|
应用该类的步骤是:
- 构造一个 marker 图像(可以通过对源图像进行标记和处理);
- 调用
WatershedSegmenter::setMarkters()函数设置 marker; - 调用
WatershedSegmenter::process()函数进行分水岭处理。

GrabCut
OpenCV 提供了 cv::grabCut() 函数来实现 GrabCut 操作。
|
|
使用 cv::grabCut() 函数非常简单,你只需要输入一张图像,标记一些像素点属于前景图或背景图。然后该算法就会根据这些标记点分割出整幅图像前景和背景。
一种标记的方法就是直接将一部分前景的区域用矩形框起来:
|
|
之后可以调用 cv::grabCut() 函数:
|
|
得到的结果 result 将包含下面四种常量值:
cv::GC_BGD- 所有确定属于背景的像素(实际值为 0);cv::GC_FGD- 所有确定属于前景的像素(实际值为 1);cv::GC_PR_BGD- 所有可能属于背景的像素(实际值为 2);cv::GC_PR_FGD- 所有可能属于前景的像素(实际值为 3)。
我们可以将所有可能是前景的像素提取出来:
|
|
上面得到的 foreground 图像即是应用 GrabCut 算法分割出的前景图像。
由于 cv::GC_FGD 和 cv::PR_FGD 的实际值为 1 和 3,上面的 cv::compare() 操作也可以简单的写成:
|
|

形状检测
轮廓
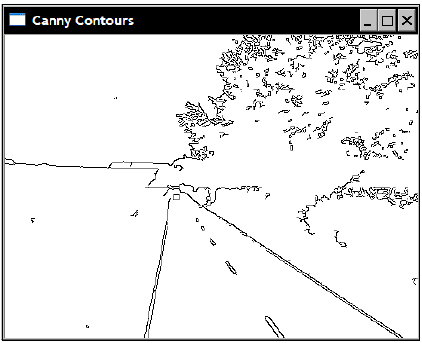
Canny 算法是一个有效的轮廓提取方法。OpenCV 提供了 cv::Canny() 函数:
|
|
例如:
|
|
原图:

结果:
直线
Hough 变换是经典的提取直线的方法。OpenCV 提供了两个版本的 Hough 变换:
HoughLines
基本的版本是 cv::HoughLines() 函数:
|
|
参数 rho 和 theta 决定了直线查找的步长。
示例:
|
|
结果:

HoughLinesP
另一个是 cv::HoughLinesP() 函数,提供了 Probabilistic Hough 变换操作,与前者的不同是对直线的可能性进行了估计,以防止对一些因巧合出现的像素对齐的情况的误判:
|
|
可以将它封装成一个类 LineFinder 。
示例:
|
|

圆
Hough 变换也可以用来检测圆。OpenCV 提供了 cv::HoughCircles() 实现这一操作:
|
|
其中,method 参数目前只有一个可选值 CV_HOUGH_GRADIENT。
在进行该变换前,总是建议先进行一次高斯模糊,以降低图像噪声,提高识别率。示例:
|
|
结果:

形状拟合
直线
OpenCV 提供了 cv::fitLine() 函数以根据一些点的集合拟合直线:
|
|
示例:
|
|
椭圆
OpenCV 提供了 cv::fitEllipse() 函数以根据一些点的集合拟合椭圆:
|
|
该操作返回一个经旋转的矩形,以表示一个椭圆的大小、形状和旋转角度。示例:
|
|
形状特征
轮廓
OpenCV 提供了 cv::findContours() 函数以提取一幅图像中的闭合轮廓:
|
|
示例(只提取外部轮廓,不考虑内部轮廓):
|
|

如果要同时查找内部轮廓,可以把 cv::findContours() 的第 3 个参数改为 CV_RETR_LIST 。如果要在查找内外所有的轮廓的同时保存轮廓的层次,可以改为 CV_RETR_TREE 。CV_RETRC_COMP 也可以得到层次,但只分成外轮廓和内轮廓两层。
边界框(bounding box)
获取一个形状的 bounding box:
|
|
最小外接圆
|
|
最小外接多边形
|
|
凸包
|
|
矩(moments)
|
|
上面几步的结果:
