day21:从Spark架构中透视Job
本文整理来源于DT大数据梦工厂:
一个work 上可以有多个executor。
启动程序默认的资源分配方式在每个Work上为当前程序分配一个ExecutorBackend,且默认情况下会最大化的使用core和momory。
CoraseGrani
Executor 的运行任务:
在excecutor 中一次性最多能够运行多少并发的Task取决于当前Executor能够使用的cores数量
一个Stage 分配的任务:executor 下里面的Task
在出现oom 或者其他的情况下,可以设置多个executor。但是在当前只有一个spakr 是计算框架时候,只能增加分片数量。
task 分配给谁主要取决于数据本地性。
cache.map().collect 不能这样做。
cache 后不能马上进行算子计算,cache 数据本地化
手动绘制spark 架构:
线程是不关心具体运行什么代码,线程是计算资源。
线程不关心具体Task中运行什么代码,所以Task 和Thread和解耦合,所以Thread是可以被复用
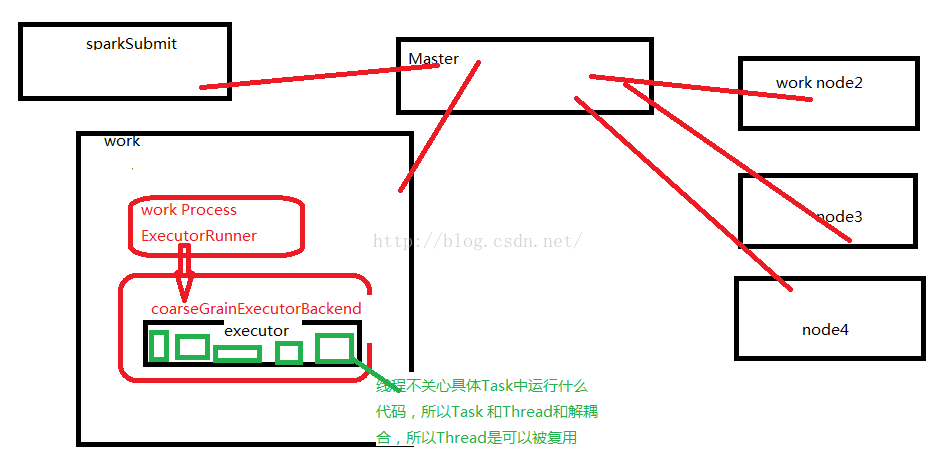
spark 在启动的时候都有一个全局资源管理器,负责整个集群的资源管理和分配,以及接收程序作业的提交且为作业分配资源。而每个节点都有一个workProcess,来管理当前计算器里面的计算资源并且向Mster汇报worker还能够正常工作。当应用程序提交作业的时候,Master 就会为我们当前提交的节点默认分配一个raseGrainedExecutorBackend进程。这个分配的进程如果你不分配的会默认情况下会最大限度的使用当前机器下最大的cpu和内存。当Driver 本身没有问题的话,Driver就会进行作业的调度来驱动CoraseGrainedExecutorBackend 中Excutor的线程来具体干活。这也就并发执行了。
一个work 下有可能会有多个work Process, ExecutorRunner
workPrecess 不会管理计算资源,每个工作节点都会有一个work Process 来管计算资源。
work Process 管理当前机器cpu和内存资源实际上是通过master来管理每台机器上的计算资源。
workProcess 会为接收master,并会为当前要运行的应用程序分配CoraseGrainedExecutorBackend 进程
Stage里面的内容一定是在executor 中执行的!
spark的一个应用程序中可以因为不同的action产生众多的job,每个job只有有一个stage。
DT大数据梦工厂联系方式:
新浪微博:www.weibo.com/ilovepains/
微信公众号:DT_Spark
博客:http://.blog.sina.com.cn/ilovepains
TEL:18610086859
Email:[email protected]