pca降维的理论知识
什么是PCA?
在数据挖掘或者图像处理等领域经常会用到主成分分析,这样做的好处是使要分析的数据的维度降低了,但是数据的主要信息还能保留下来,并且,这些变换后的维两两不相关!至于为什么?那就接着往下看。在本文中,将会很详细的解答这些问题:PCA、SVD、特征值、奇异值、特征向量这些关键词是怎么联系到一起的?又是如何在一个矩阵上体现出来?它们如何决定着一个矩阵的性质?能不能用一种直观又容易理解的方式描述出来?
数据降维
为了说明什么是数据的主成分,先从数据降维说起。数据降维是怎么回事儿?假设三维空间中有一系列点,这些点分布在一个过原点的斜面上,如果你用自然坐标系x,y,z这三个轴来表示这组数据的话,需要使用三个维度,而事实上,这些点的分布仅仅是在一个二维的平面上,那么,问题出在哪里?如果你再仔细想想,能不能把x,y,z坐标系旋转一下,使数据所在平面与x,y平面重合?这就对了!如果把旋转后的坐标系记为x',y',z',那么这组数据的表示只用x'和y'两个维度表示即可!当然了,如果想恢复原来的表示方式,那就得把这两个坐标之间的变换矩阵存下来。这样就能把数据维度降下来了!但是,我们要看到这个过程的本质,如果把这些数据按行或者按列排成一个矩阵,那么这个矩阵的秩就是2!这些数据之间是有相关性的,这些数据构成的过原点的向量的最大线性无关组包含2个向量,这就是为什么一开始就假设平面过原点的原因!那么如果平面不过原点呢?这就是数据中心化的缘故!将坐标原点平移到数据中心,这样原本不相关的数据在这个新坐标系中就有相关性了!有趣的是,三点一定共面,也就是说三维空间中任意三点中心化后都是线性相关的,一般来讲n维空间中的n个点一定能在一个n-1维子空间中分析!所以,不要说数据不相关,那是因为坐标没选对!
上面这个例子里把数据降维后并没有丢弃任何东西,因为这些数据在平面以外的第三个维度的分量都为0。现在,我假设这些数据在z'轴有一个很小的抖动,那么我们仍然用上述的二维表示这些数据,理由是我认为这两个轴的信息是数据的主成分,而这些信息对于我们的分析已经足够了,z'轴上的抖动很有可能是噪声,也就是说本来这组数据是有相关性的,噪声的引入,导致了数据不完全相关,但是,这些数据在z'轴上的分布与原点构成的夹角非常小,也就是说在z'轴上有很大的相关性,综合这些考虑,就可以认为数据在x',y'轴上的投影构成了数据的主成分!
现在,关于什么是数据的主成分已经很好的回答了。下面来看一个更具体的例子。
下面是一些学生的成绩:
原理及推导 <wbr>(转)")
首先,假设这些科目成绩不相关,也就是说某一科考多少份与其他科没有关系。那么一眼就能看出来,数学、物理、化学这三门成绩构成了这组数据的主成分(很显然,数学作为第一主成分,因为数学成绩拉的最开)。为什么一眼能看出来?因为坐标轴选对了!下面再看一组数据,还能不能一眼看出来:
原理及推导 <wbr>(转)")
是不是有点凌乱了?你还能看出来数据的主成分吗?显然不能,因为在这坐标系下数据分布很散乱。所以说,看到事物的表象而看不到其本质,是因为看的角度有问题!如果把这些数据在空间中画出来,也许你一眼就能看出来。但是,对于高维数据,能想象其分布吗?就算能描述分布,如何精确地找到这些主成分的轴?如何衡量你提取的主成分到底占了整个数据的多少信息?要回答这些问题,需要将上面的分析上升到理论层面。接下来就是PCA的理论分析。
PCA推导
以下面这幅图开始我们的推导:
原理及推导 <wbr>(转)")
上面是二维空间中的一组数据,很明显,数据的分布让我们很容易就能看出来主成分的轴(简称主轴)的大致方向。下面的问题就是如何通过数学计算找出主轴的方向。来看这张图:
原理及推导 <wbr>(转)")
现在要做的事情就是寻找u1的方向,对于这点,我想好多人都有经验,这不就是以前用最小二乘法拟合数据时做的事情吗!对,最小二乘法求出来的直线(二维)的方向就是u1的方向!那u2的方向呢?因为这里是二维情况,所以u2方向就是跟u1垂直的方向。
先来看看svd分解
SVD不仅是一个数学问题,在工程应用中的很多地方都有它的身影,比如前面讲的PCA,掌握了SVD原理后再去看PCA那是相当简单的,在推荐系统方面,SVD更是名声大噪,将它应用于推荐系统的是Netflix大奖的获得者Koren,可以在Google上找到他写的文章;用SVD可以很容易得到任意矩阵的满秩分解,用满秩分解可以对数据做压缩。可以用SVD来证明对任意M*N的矩阵均存在如下分解:
原理详解及推导 <wbr>(转)")
这个可以应用在数据降维压缩上!在数据相关性特别大的情况下存储X和Y矩阵比存储A矩阵占用空间更小!
在开始讲解SVD之前,先补充一点矩阵代数的相关知识。
正交矩阵
正交矩阵是在欧几里得空间里的叫法,在酉空间里叫酉矩阵,一个正交矩阵对应的变换叫正交变换,这个变换的特点是不改变向量的尺寸和向量间的夹角,那么它到底是个什么样的变换呢?看下面这张图
原理详解及推导 <wbr>(转)")
假设二维空间中的一个向量OA,它在标准坐标系也即e1、e2表示的坐标是中表示为(a,b)'(用'表示转置),现在把它用另一组坐标e1'、e2'表示为(a',b')',存在矩阵U使得(a',b')'=U(a,b)',则U即为正交矩阵。从图中可以看到,正交变换只是将变换向量用另一组正交基表示,在这个过程中并没有对向量做拉伸,也不改变向量的空间位置,加入对两个向量同时做正交变换,那么变换前后这两个向量的夹角显然不会改变。上面的例子只是正交变换的一个方面,即旋转变换,可以把e1'、e2'坐标系看做是e1、e2坐标系经过旋转某个斯塔角度得到,怎么样得到该旋转矩阵U呢?如下
原理详解及推导 <wbr>(转)")
原理详解及推导 <wbr>(转)")
![]()
a'和b'实际上是x在e1'和e2'轴上的投影大小,所以直接做内积可得,then
原理详解及推导 <wbr>(转)")
从图中可以看到
原理详解及推导 <wbr>(转)")
原理详解及推导 <wbr>(转)")
所以
原理详解及推导 <wbr>(转)")
正交阵U行(列)向量之间都是单位正交向量。上面求得的是一个旋转矩阵,它对向量做旋转变换!也许你会有疑问:刚才不是说向量空间位置不变吗?怎么现在又说它被旋转了?对的,这两个并没有冲突,说空间位置不变是绝对的,但是坐标是相对的,加入你站在e1上看OA,随着e1旋转到e1',看OA的位置就会改变。如下图:
原理详解及推导 <wbr>(转)")
如图,如果我选择了e1'、e2'作为新的标准坐标系,那么在新坐标系中OA(原标准坐标系的表示)就变成了OA',这样看来就好像坐标系不动,把OA往顺时针方向旋转了“斯塔”角度,这个操作实现起来很简单:将变换后的向量坐标仍然表示在当前坐标系中。
旋转变换是正交变换的一个方面,这个挺有用的,比如在开发中需要实现某种旋转效果,直接可以用旋转变换实现。正交变换的另一个方面是反射变换,也即e1'的方向与图中方向相反,这个不再讨论。
总结:正交矩阵的行(列)向量都是两两正交的单位向量,正交矩阵对应的变换为正交变换,它有两种表现:旋转和反射。正交矩阵将标准正交基映射为标准正交基(即图中从e1、e2到e1'、e2')
特征值分解——EVD
在讨论SVD之前先讨论矩阵的特征值分解(EVD),在这里,选择一种特殊的矩阵——对称阵(酉空间中叫hermite矩阵即厄米阵)。对称阵有一个很优美的性质:它总能相似对角化,对称阵不同特征值对应的特征向量两两正交。一个矩阵能相似对角化即说明其特征子空间即为其列空间,若不能对角化则其特征子空间为列空间的子空间。现在假设存在mxm的满秩对称矩阵A,它有m个不同的特征值,设特征值为
![]()
对应的单位特征向量为
![]()
则有
原理详解及推导 <wbr>(转)")
进而
原理详解及推导 <wbr>(转)")
原理详解及推导 <wbr>(转)")
原理详解及推导 <wbr>(转)")
所以可得到A的特征值分解(由于对称阵特征向量两两正交,所以U为正交阵,正交阵的逆矩阵等于其转置)
原理详解及推导 <wbr>(转)")
这里假设A有m个不同的特征值,实际上,只要A是对称阵其均有如上分解。
矩阵A分解了,相应的,其对应的映射也分解为三个映射。现在假设有x向量,用A将其变换到A的列空间中,那么首先由U'先对x做变换:
![]()
U是正交阵U'也是正交阵,所以U'对x的变换是正交变换,它将x用新的坐标系来表示,这个坐标系就是A的所有正交的特征向量构成的坐标系。比如将x用A的所有特征向量表示为:
![]()
则通过第一个变换就可以把x表示为[a1 a2 ... am]':
原理详解及推导 <wbr>(转)")
紧接着,在新的坐标系表示下,由中间那个对角矩阵对新的向量坐标换,其结果就是将向量往各个轴方向拉伸或压缩:
原理详解及推导 <wbr>(转)")
从上图可以看到,如果A不是满秩的话,那么就是说对角阵的对角线上元素存在0,这时候就会导致维度退化,这样就会使映射后的向量落入m维空间的子空间中。
最后一个变换就是U对拉伸或压缩后的向量做变换,由于U和U'是互为逆矩阵,所以U变换是U'变换的逆变换。
因此,从对称阵的分解对应的映射分解来分析一个矩阵的变换特点是非常直观的。假设对称阵特征值全为1那么显然它就是单位阵,如果对称阵的特征值有个别是0其他全是1,那么它就是一个正交投影矩阵,它将m维向量投影到它的列空间中。
根据对称阵A的特征向量,如果A是2*2的,那么就可以在二维平面中找到这样一个矩形,是的这个矩形经过A变换后还是矩形:
原理详解及推导 <wbr>(转)")
这个矩形的选择就是让其边都落在A的特征向量方向上,如果选择其他矩形的话变换后的图形就不是矩形了!
奇异值分解——SVD
上面的特征值分解的A矩阵是对称阵,根据EVD可以找到一个(超)矩形使得变换后还是(超)矩形,也即A可以将一组正交基映射到另一组正交基!那么现在来分析:对任意M*N的矩阵,能否找到一组正交基使得经过它变换后还是正交基?答案是肯定的,它就是SVD分解的精髓所在。
现在假设存在M*N矩阵A,事实上,A矩阵将n维空间中的向量映射到k(k<=m)维空间中,k=Rank(A)。现在的目标就是:在n维空间中找一组正交基,使得经过A变换后还是正交的。假设已经找到这样一组正交基:
![]()
则A矩阵将这组基映射为:
![]()
如果要使他们两两正交,即
![]()
根据假设,存在
![]()
所以如果正交基v选择为A'A的特征向量的话,由于A'A是对称阵,v之间两两正交,那么
原理详解及推导 <wbr>(转)")
这样就找到了正交基使其映射后还是正交基了,现在,将映射后的正交基单位化:
因为
![]()
所以有
![]()
所以取单位向量
原理详解及推导 <wbr>(转)")
由此可得
![]()
当k < i <= m时,对u1,u2,...,uk进行扩展u(k+1),...,um,使得u1,u2,...,um为m维空间中的一组正交基,即
![]()
同样的,对v1,v2,...,vk进行扩展v(k+1),...,vn(这n-k个向量存在于A的零空间中,即Ax=0的解空间的基),使得v1,v2,...,vn为n维空间中的一组正交基,即
![]()
则可得到
原理详解及推导 <wbr>(转)")
继而可以得到A矩阵的奇异值分解:
![]()
![]()
现在可以来对A矩阵的映射过程进行分析了:如果在n维空间中找到一个(超)矩形,其边都落在A'A的特征向量的方向上,那么经过A变换后的形状仍然为(超)矩形!
vi为A'A的特征向量,称为A的右奇异向量,ui=Avi实际上为AA'的特征向量,称为A的左奇异向量。下面利用SVD证明文章一开始的满秩分解:
原理详解及推导 <wbr>(转)")
利用矩阵分块乘法展开得:
原理详解及推导 <wbr>(转)")
可以看到第二项为0,有
原理详解及推导 <wbr>(转)")
令
原理详解及推导 <wbr>(转)")
原理详解及推导 <wbr>(转)")
则A=XY即是A的满秩分解。
整个SVD的推导过程就是这样,后面会介绍SVD在推荐系统中的具体应用,也就是复现Koren论文中的算法以及其推导过程。
一下是我从别人博客转载过来的,分析的特别好
首先, 我们定义样本和特征, 假定有 m 个样本, 每个样本有 n 个特征, 可以如下表示:
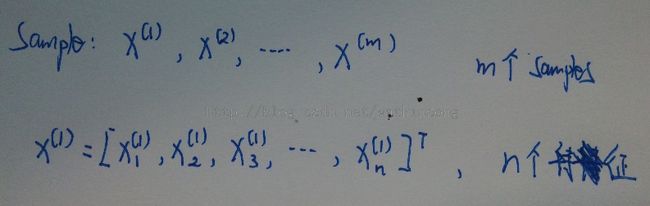
由简到难, 先看一下从2D 降维到1D的比较直观的表示:

在上图中, 假设只有两个特征x1, x2, 然后需要降维到1D, 这个时候我们可以观察途中X所表示的样本点基本上分布在一条直线上, 那么就可以将所有的用(x1, x2)平面表示的坐标映射到图像画出的直线z上, 上图中的黑色铅笔线表示样本点映射的过程。
映射到直线Z后, 如果只用直线Z表示样本的空间分布, 就可以用1个坐标表示每个样本了, 这样就将2D的特征降维到1D的特征。 同样的道理, 如果将3D的特征降维到2D, 就是将具有3D特征的样本从一个三维空间中映射到二维空间。
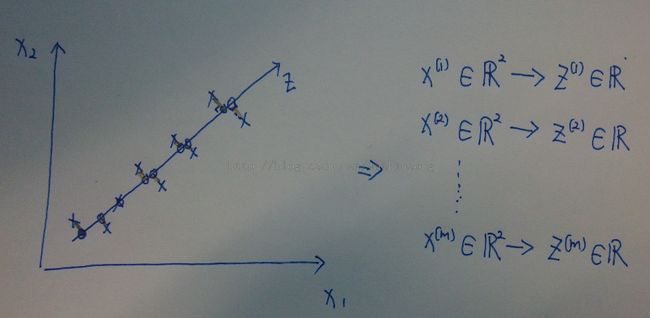
在上图中, 将所有的二维特征的样本点映射到了一维直线上, 这样, 从上图中可以看出在映射的过程中存在映射误差。
在上图中, 用圆圈表示了样本映射后的坐标位置。这些位置可以叫做近似位置, 以后还要用到这些位置计算映射误差。
因为在降维映射的过程中, 存在映射误差, 所有在对高维特征降维之前, 需要做特征归一化(feature normalization), 这个归一化操作包括: (1) feature scaling (让所有的特征拥有相似的尺度, 要不然一个特征特别小, 一个特征特别大会影响降维的效果) (2) zero mean normalization (零均值归一化)。
在上图中, 也可以把降维的过程看作找到一个或者多个向量u1, u2, ...., un, 使得这些向量构成一个新的向量空间(需要学习矩阵分析哦), 然后把需要降维的样本映射到这个新的样本空间上。
对于2D -> 1D 的降维过程, 可以理解为找到一个向量u1, u1表示了一个方向, 然后将所有的样本映射到这个方向上, 其实, 一个向量也可以表示一个样本空间。
对于3D -> 2D 的降维过程, 可以理解为找到两个向量u1, u2, (u1, u2) 这两个向量定义了一个新的特征空间, 然后将原样本空间的样本映射到新的样本空间。
对于n-D -> k-D 的降维过程, 可以理解为找到 k 个向量 u1, u2, ..., uk, 这k个向量定义了新的向量空间, 然后进行样本映射。
3.2 Cost Function
既然样本映射存在误差, 就需要计算每次映射的误差大小。 采用以下公式计算误差大小:

X-approx表示的是样本映射以后的新的坐标, 这个坐标如果位置如果用当前的样本空间表示, 维度和 样本X是一致的。
要特别注意, PCA降维和linear regression是不一样的, 虽然看上去很一致, 但是linear regression的cost function的计算是样本上线垂直的到拟合线的距离, 而PCA的cost function 是样本点到拟合线的垂直距离。 差别如下图所示:

3.3 PCA 计算过程
(A) Feature Normalization
- function [X_norm, mu, sigma] = featureNormalize(X)
- %FEATURENORMALIZE Normalizes the features in X
- % FEATURENORMALIZE(X) returns a normalized version of X where
- % the mean value of each feature is 0 and the standard deviation
- % is 1. This is often a good preprocessing step to do when
- % working with learning algorithms.
- mu = mean(X);
- X_norm = bsxfun(@minus, X, mu);
- sigma = std(X_norm);
- X_norm = bsxfun(@rdivide, X_norm, sigma);
- % ============================================================
- end
注意: 这里的X是一个m * n 的矩阵, 有 m 个样本, 每个样本包含 n 个特征, 每一行表示一个样本。 X_norm是最终得到的特征, 首先计算了所有训练样本每个特征的均值, 然后减去均值, 然后除以标准差。
(B) 计算降维矩阵


(C) 降维计算
获得降维矩阵后, 即可通过降维矩阵将样本映射到低维空间上。 降维公式如下图所示:
3.4 贡献率 (降维的k的值的选择)
在 http://blog.csdn.net/watkinsong/article/details/8234766 这篇文章中, 很多人问了关于贡献率的问题, 这就是相当于选择k的值的大小。 也就是选择降维矩阵 U 中的特征向量的个数。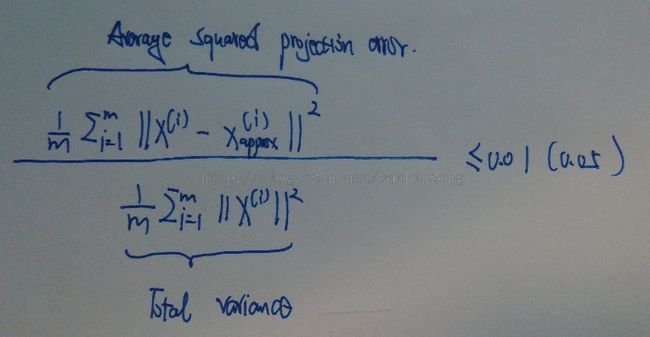

3.5 重构 (reconstruction, 根据降维后数据重构原数据), 数据还原
获得降维后的数据, 可以根据降维后的数据还原原始数据。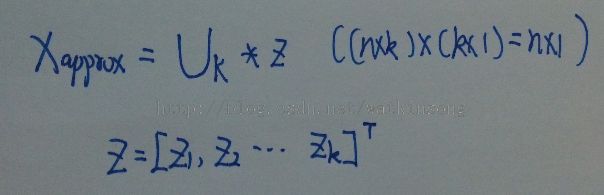
4. PCA的应用示例
貌似本页已经写的太多了, 所以这里示例另外给出。- %% Initialization
- clear ; close all; clc
- fprintf('this code will load 12 images and do PCA for each face.\n');
- fprintf('10 images are used to train PCA and the other 2 images are used to test PCA.\n');
- m = 4000; % number of samples
- trainset = zeros(m, 32 * 32); % image size is : 32 * 32
- for i = 1 : m
- img = imread(strcat('./img/', int2str(i), '.bmp'));
- img = double(img);
- trainset(i, :) = img(:);
- end
- %% before training PCA, do feature normalization
- mu = mean(trainset);
- trainset_norm = bsxfun(@minus, trainset, mu);
- sigma = std(trainset_norm);
- trainset_norm = bsxfun(@rdivide, trainset_norm, sigma);
- %% we could save the mean face mu to take a look the mean face
- imwrite(uint8(reshape(mu, 32, 32)), 'meanface.bmp');
- fprintf('mean face saved. paused\n');
- pause;
- %% compute reduce matrix
- X = trainset_norm; % just for convience
- [m, n] = size(X);
- U = zeros(n);
- S = zeros(n);
- Cov = 1 / m * X' * X;
- [U, S, V] = svd(Cov);
- fprintf('compute cov done.\n');
- %% save eigen face
- for i = 1:10
- ef = U(:, i)';
- img = ef;
- minVal = min(img);
- img = img - minVal;
- max_val = max(abs(img));
- img = img / max_val;
- img = reshape(img, 32, 32);
- imwrite(img, strcat('eigenface', int2str(i), '.bmp'));
- end
- fprintf('eigen face saved, paused.\n');
- pause;
- %% dimension reduction
- k = 100; % reduce to 100 dimension
- test = zeros(10, 32 * 32);
- for i = 4001:4010
- img = imread(strcat('./img/', int2str(i), '.bmp'));
- img = double(img);
- test(i - 4000, :) = img(:);
- end
- % test set need to do normalization
- test = bsxfun(@minus, test, mu);
- % reduction
- Uk = U(:, 1:k);
- Z = test * Uk;
- fprintf('reduce done.\n');
- %% reconstruction
- %% for the test set images, we only minus the mean face,
- % so in the reconstruct process, we need add the mean face back
- Xp = Z * Uk';
- % show reconstructed face
- for i = 1:5
- face = Xp(i, :) + mu;
- face = reshape((face), 32, 32);
- imwrite(uint8(face), strcat('./reconstruct/', int2str(4000 + i), '.bmp'));
- end
- %% for the train set reconstruction, we minus the mean face and divide by standard deviation during the train
- % so in the reconstruction process, we need to multiby standard deviation first,
- % and then add the mean face back
- trainset_re = trainset_norm * Uk; % reduction
- trainset_re = trainset_re * Uk'; % reconstruction
- for i = 1:5
- train = trainset_re(i, :);
- train = train .* sigma;
- train = train + mu;
- train = reshape(train, 32, 32);
- imwrite(uint8(train), strcat('./reconstruct/', int2str(i), 'train.bmp'));
- end
- fprintf('job done.\n');