Apache Pig的一些基础概念及用法总结
转载必须注明出处:http://www.codelast.com/
本文可以让刚接触pig的人对一些基础概念有个初步的了解。
本文大概是互联网上第一篇公开发表的且涵盖大量实际例子的Apache Pig中文教程(由Google搜索可知),文中的大量实例都是作者Darran Zhang(website: codelast.com)在工作、学习中总结的经验或解决的问题,并且添加了较为详尽的说明及注解,此外,作者还在不断地添加本文的内容,希望能帮助一部分人。
Apache pig是用来处理大规模数据的高级查询语言,配合Hadoop使用,可以在处理海量数据时达到事半功倍的效果,比使用Java,C++等语言编写大规模数据处理程序的难度要小N倍,实现同样的效果的代码量也小N倍。Twitter就大量使用pig来处理海量数据——有兴趣的,可以看Twitter工程师写的这个PPT。
但是,刚接触pig时,可能会觉得里面的某些概念以及程序实现方法与想像中的很不一样,甚至有些莫名,所以,你需要仔细地研究一下基础概念,这样在写pig程序的时候,才不会觉得非常别扭。
本文基于以下环境:
pig 0.8.1
先给出两个链接:pig参考手册1,pig参考手册2。本文的部分内容来自这两个手册,但涉及到翻译的部分,也是我自己翻译的,因此可能理解与英文有偏差,如果你觉得有疑义,可参考英文内容。
【配置Pig语法高亮】
在正式开始学习Pig之前,你首先要明白,配置好编辑器的Pig语法高亮是很有用的,它可以极大地提高你的工作效率。
在Linux下,选择就很多了,大分部人使用的是vi,vim,但我是个Emacs控,所以我就先说说如何配置 Emacs的Pig语法高亮。此插件是一个很好的选择: https://github.com/cloudera/piglatin-mode
其实Emacs也有Windows版的,如果你习惯在Windows下工作,完全可以在Windows下按上面的方法配置一下Pig语法高亮(但是Windows版的Emacs还需要一些额外的配置工作,例如修改注册表等,所以会比在Linux下使用要麻烦一些,具体请看这篇文章)。
文章来源:http://www.codelast.com/
下面开始学习Pig。
(1)关系(relation)、包(bag)、元组(tuple)、字段(field)、数据(data)的关系
- 一个关系(relation)是一个包(bag),更具体地说,是一个外部的包(outer bag)。
- 一个包(bag)是一个元组(tuple)的集合。在pig中表示数据时,用大括号{}括起来的东西表示一个包——无论是在教程中的实例演示,还是在pig交互模式下的输出,都遵循这样的约定,请牢记这一点,因为不理解的话就会对数据结构的掌握产生偏差。
- 一个元组(tuple)是若干字段(field)的一个有序集(ordered set)。在pig中表示数据时,用小括号()括起来的东西表示一个元组。
- 一个字段是一块数据(data)。
“元组”这个词很抽象,你可以把它想像成关系型数据库表中的一行,它含有一个或多个字段,其中,每一个字段可以是任何数据类型,并且可以有或者没有数据。
“关系”可以比喻成关系型数据库的一张表,而上面说了,“元组”可以比喻成数据表中的一行,那么这里有人要问了,在关系型数据库中,同一张表中的每一行都有固定的字段数,pig中的“关系”与“元组”之间,是否也是这样的情况呢?不是的。“关系”并不要求每一个“元组”都含有相同数量的字段,并且也不会要求各“元组”中在相同位置处的字段具有相同的数据类型(太随意了,是吧?)
文章来源:http://www.codelast.com/
(2)一个 计算多维度组合下的平均值 的实际例子
为了帮助大家理解pig的一个基本的数据处理流程,我造了一些简单的数据来举个例子——
假设有数据文件:a.txt(各数值之间是以tab分隔的):
|
1
2
3
4
5
6
7
|
[root@localhost pig]$
cat
a.txt
a 1 2 3 4.2 9.8
a 3 0 5 3.5 2.1
b 7 9 9 - -
a 7 9 9 2.6 6.2
a 1 2 5 7.7 5.9
a 1 2 3 1.4 0.2
|
问题如下:怎样求出在第2、3、4列的所有组合的情况下,最后两列的平均值分别是多少?
例如,第2、3、4列有一个组合为(1,2,3),即第一行和最后一行数据。对这个维度组合来说,最后两列的平均值分别为:
(4.2+1.4)/2=2.8
(9.8+0.2)/2=5.0
而对于第2、3、4列的其他所有维度组合,都分别只有一行数据,因此最后两列的平均值其实就是它们自身。
特别地,组合(7,9,9)有两行记录:第三、四行,但是第三行数据的最后两列没有值,因此它不应该被用于平均值的计算,也就是说,在计算平均值时,第三行是无效数据。所以(7,9,9)组合的最后两列的平均值为 2.6 和 6.2。
我们现在用pig来算一下,并且输出最终的结果。
先进入本地调试模式(pig -x local),再依次输入如下pig代码:
|
1
2
3
4
|
A =
LOAD
'a.txt'
AS
(col1:chararray, col2:
int
, col3:
int
, col4:
int
, col5:
double
, col6:
double
);
B =
GROUP
A
BY
(col2, col3, col4);
C = FOREACH B GENERATE
group
,
AVG
(A.col5),
AVG
(A.col6);
DUMP C;
|
pig输出结果如下:
|
1
2
3
4
|
((1,2,3),2.8,5.0)
((1,2,5),7.7,5.9)
((3,0,5),3.5,2.1)
((7,9,9),2.6,6.2)
|
这个结果对吗?手工算一下就知道是对的。
文章来源:http://www.codelast.com/
下面,我们依次来看看每一句pig代码分别得到了什么样的数据。
①加载 a.txt 文件,并指定每一列的数据类型分别为 chararray(字符串),int,int,int,double,double。同时,我们还给予了每一列别名,分别为 col1,col2,……,col6。这个别名在后面的数据处理中会用到——如果你不指定别名,那么在后面的处理中,就只能使用索引($0,$1,……)来标识相应的列了,这样可读性会变差,因此,在列固定的情况下,还是指定别名的好。
将数据加载之后,保存到变量A中,A的数据结构如下:
|
1
|
A: {col1: chararray,col2:
int
,col3:
int
,col4:
int
,col5:
double
,col6:
double
}
|
可见,A是用大括号括起来的东西。根据本文前面的说法,A是一个包(bag)。
这个时候,A与你想像中的样子应该是一致的,也就是与前面打印出来的 a.txt 文件的内容是一样的,还是一行一行的类似于“二维表”的数据。
文章来源:http://www.codelast.com/
②按照A的第2、3、4列,对A进行分组。pig会找出所有第2、3、4列的组合,并按照升序进行排列,然后将它们与对应的包A整合起来,得到如下的数据结构:
|
1
|
B: {
group
: (col2:
int
,col3:
int
,col4:
int
),A: {col1: chararray,col2:
int
,col3:
int
,col4:
int
,col5:
double
,col6:
double
}}
|
可见,A的第2、3、4列的组合被pig赋予了一个别名:group,这很形象。同时我们也观察到,B的每一行其实就是由一个group和若干个A组成的——注意,是若干个A。这里之所以只显示了一个A,是因为这里表示的是数据结构,而不表示具体数据有多少组。
实际的数据为:
|
1
2
3
4
|
((1,2,3),{(a,1,2,3,4.2,9.8),(a,1,2,3,1.4,0.2)})
((1,2,5),{(a,1,2,5,7.7,5.9)})
((3,0,5),{(a,3,0,5,3.5,2.1)})
((7,9,9),{(b,7,9,9,,),(a,7,9,9,2.6,6.2)})
|
可见,与前面所说的一样,组合(1,2,3)对应了两行数据,组合(7,9,9)也对应了两行数据。
这个时候,B的结构就不那么明朗了,可能与你想像中有一点不一样了。
文章来源:http://www.codelast.com/
③计算每一种组合下的最后两列的平均值。
根据上面得到的B的数据,你可以把B想像成一行一行的数据(只不过这些行不是对称的),FOREACH 的作用是对 B 的每一行数据进行遍历,然后进行计算。
GENERATE 可以理解为要生成什么样的数据,这里的 group 就是上一步操作中B的第一项数据(即pig为A的第2、3、4列的组合赋予的别名),所以它告诉了我们:在数据集 C 的每一行里,第一项就是B中的group——类似于(1,2,5)这样的东西)。
而 AVG(A.col5) 这样的计算,则是调用了pig的一个求平均值的函数 AVG,用于对 A 的名为 col5 的列求平均值。前文说了,在加载数据到A的时候,我们已经给每一列起了个别名,col5就是倒数第二列。
到这里,可能有人要迷糊了:难道 AVG(A.col5) 不是表示对 A 的col5这一列求平均值吗?也就是说,在遍历B(FOREACH B)的每一行时候,计算结果都是相同的啊!
事实上并不是这样。我们遍历的是B,我们需要注意到,B的数据结构中,每一行数据里,一个group对应的是若干个A,因此,这里的 A.col5,指的是B的每一行中的A,而不是包含全部数据的那个A。拿B的第一行来举例:
((1,2,3),{(a,1,2,3,4.2,9.8),(a,1,2,3,1.4,0.2)})
遍历到B的这一行时,要计算AVG(A.col5),pig会找到 (a,1,2,3,4.2,9.8) 中的4.2,以及(a,1,2,3,1.4,0.2)中的1.4,加起来除以2,就得到了平均值。
同理,我们也知道了AVG(A.col6)是怎么算出来的。但还有一点要注意的:对(7,9,9)这个组,它对应的数据(b,7,9,9,,)里最后两列是无值的,这是因为我们的数据文件对应位置上不是有效数字,而是两个“-”,pig在加载数据的时候自动将它置为空了,并且计算平均值的时候,也不会把这一组数据考虑在内(相当于忽略这组数据的存在)。
到了这里,我们不难理解,为什么C的数据结构是这样的了:
|
1
|
C: {
group
: (col2:
int
,col3:
int
,col4:
int
),
double
,
double
}
|
文章来源:http://www.codelast.com/
④DUMP C就是将C中的数据输出到控制台。如果要输出到文件,需要使用:
|
1
|
STORE C
INTO
'output'
;
|
这样pig就会在当前目录下新建一个“output”目录(该目录必须事先不存在),并把结果文件放到该目录下。
请想像一下,如果要实现相同的功能,用Java或C++写一个Map-Reduce应用程序需要多少时间?可能仅仅是写一个build.xml或者Makefile,所需的时间就是写这段pig代码的几十倍了!
正因为pig有如此优势,它才得到了广泛应用。
文章来源:http://www.codelast.com/
(3)怎样统计数据行数
在SQL语句中,要统计表中数据的行数,很简单:
|
1
|
SELECT
COUNT
(*)
FROM
table_name
WHERE
condition
|
在pig中,也有一个COUNT函数,在pig手册中,对COUNT函数有这样的说明:
Computes the number of elements in a bag.
假设要计算数据文件a.txt的行数:
|
1
2
3
4
5
6
7
|
[root@localhost pig]$
cat
a.txt
a 1 2 3 4.2 9.8
a 3 0 5 3.5 2.1
b 7 9 9 - -
a 7 9 9 2.6 6.2
a 1 2 5 7.7 5.9
a 1 2 3 1.4 0.2
|
你是否可以这样做呢:
|
1
2
3
|
A =
LOAD
'a.txt'
AS
(col1:chararray, col2:
int
, col3:
int
, col4:
int
, col5:
double
, col6:
double
);
B =
COUNT
(*);
DUMP B;
|
答案是:绝对不行。pig会报错。pig手册中写得很明白:
Note: You cannot use the tuple designator (*) with COUNT; that is, COUNT(*) will not work.
那么,这样对某一列计数行不行呢:
|
1
|
B =
COUNT
(A.col2);
|
答案是:仍然不行。pig会报错。
这就与我们想像中的“正确做法”有点不一样了:我为什么不能直接统计一个字段的数目有多少呢?刚接触pig的时候,一定非常疑惑这样明显“不应该出错”的写法为什么行不通。
要统计A中含col2字段的数据有多少行,正确的做法是:
|
1
2
3
4
|
A =
LOAD
'a.txt'
AS
(col1:chararray, col2:
int
, col3:
int
, col4:
int
, col5:
double
, col6:
double
);
B =
GROUP
A
ALL
;
C = FOREACH B GENERATE
COUNT
(A.col2);
DUMP C;
|
输出结果:
|
1
|
(6)
|
表明有6行数据。
如此麻烦?没错。这是由pig的数据结构决定的。
文章来源:http://www.codelast.com/
在这个例子中,统计COUNT(A.col2)和COUNT(A)的结果是一样的,但是,如果col2这一列中含有空值:
|
1
2
3
4
5
6
7
|
[root@localhost pig]$
cat
a.txt
a 1 2 3 4.2 9.8
a 0 5 3.5 2.1
b 7 9 9 - -
a 7 9 9 2.6 6.2
a 1 2 5 7.7 5.9
a 1 2 3 1.4 0.2
|
则以下pig程序及执行结果为:
|
1
2
3
4
5
|
grunt> A =
LOAD
'a.txt'
AS
(col1:chararray, col2:
int
, col3:
int
, col4:
int
, col5:
double
, col6:
double
);
grunt> B =
GROUP
A
ALL
;
grunt> C = FOREACH B GENERATE
COUNT
(A.col2);
grunt> DUMP C;
(5)
|
可见,结果为5行。那是因为你LOAD数据的时候指定了col2的数据类型为int,而a.txt的第二行数据是空的,因此数据加载到A以后,有一个字段就是空的:
|
1
2
3
4
5
6
7
|
grunt> DUMP A;
(a,1,2,3,4.2,9.8)
(a,,0,5,3.5,2.1)
(b,7,9,9,,)
(a,7,9,9,2.6,6.2)
(a,1,2,5,7.7,5.9)
(a,1,2,3,1.4,0.2)
|
在COUNT的时候,null的字段不会被计入在内,所以结果是5。
The COUNT function follows syntax semantics and ignores nulls. What this means is that a tuple in the bag will not be counted if the first field in this tuple is NULL. If you want to include NULL values in the count computation, use COUNT_STAR.
文章来源:http://www.codelast.com/
我们还是采用前面的a.txt数据文件来说明:
|
1
2
3
4
5
6
7
|
[root@localhost pig]$
cat
a.txt
a 1 2 3 4.2 9.8
a 3 0 5 3.5 2.1
b 7 9 9 - -
a 7 9 9 2.6 6.2
a 1 2 5 7.7 5.9
a 1 2 3 1.4 0.2
|
如果我们按照前文的做法,计算多维度组合下的最后两列的平均值,则:
|
1
2
3
4
5
6
7
8
|
grunt> A =
LOAD
'a.txt'
AS
(col1:chararray, col2:
int
, col3:
int
, col4:
int
, col5:
double
, col6:
double
);
grunt> B =
GROUP
A
BY
(col2, col3, col4);
grunt> C = FOREACH B GENERATE
group
,
AVG
(A.col5),
AVG
(A.col6);
grunt> DUMP C;
((1,2,3),2.8,5.0)
((1,2,5),7.7,5.9)
((3,0,5),3.5,2.1)
((7,9,9),2.6,6.2)
|
可见,输出结果中,每一行的第一项是一个tuple(元组),我们来试试看 FLATTEN 的作用:
|
1
2
3
4
5
6
7
8
|
grunt> A = LOAD
'a.txt'
AS (col1:chararray, col2:
int
, col3:
int
, col4:
int
, col5:
double
, col6:
double
);
grunt> B = GROUP A BY (col2, col3, col4);
grunt> C = FOREACH B GENERATE FLATTEN(group), AVG(A.col5), AVG(A.col6);
grunt> DUMP C;
(1,2,3,2.8,5.0)
(1,2,5,7.7,5.9)
(3,0,5,3.5,2.1)
(7,9,9,2.6,6.2)
|
看到了吗?被 FLATTEN 的group本来是一个元组,现在变成了扁平的结构了。按照pig文档的说法,FLATTEN用于对元组(tuple)和包(bag)“解嵌套”(un-nest):
The FLATTEN operator looks like a UDF syntactically, but it is actually an operator that changes the structure of tuples and bags in a way that a UDF cannot. Flatten un-nests tuples as well as bags. The idea is the same, but the operation and result is different for each type of structure.For tuples, flatten substitutes the fields of a tuple in place of the tuple. For example, consider a relation that has a tuple of the form (a, (b, c)). The expression GENERATE $0, flatten($1), will cause that tuple to become (a, b, c).
文章来源:http://www.codelast.com/
所以我们就看到了上面的结果。
在有的时候,不“解嵌套”的数据结构是不利于观察的,输出这样的数据可能不利于外围数程序的处理(例如,pig将数据输出到磁盘后,我们还需要用其他程序做后续处理,而对一个元组,输出的内容里是含括号的,这就在处理流程上又要多一道去括号的工序),因此,FLATTEN提供了一个让我们在某些情况下可以清楚、方便地分析数据的机会。
(5)关于GROUP操作符
在上文的例子中,已经演示了GROUP操作符会生成什么样的数据。在这里,需要说得更理论一些:
- 用于GROUP的key如果多于一个字段(正如本文前面的例子),则GROUP之后的数据的key是一个元组(tuple),否则它就是与用于GROUP的key相同类型的东西。
- GROUP的结果是一个关系(relation),在这个关系中,每一组包含一个元组(tuple),这个元组包含两个字段:(1)第一个字段被命名为“group”——这一点非常容易与GROUP关键字相混淆,但请区分开来。该字段的类型与用于GROUP的key类型相同。(2)第二个字段是一个包(bag),它的类型与被GROUP的关系的类型相同。
(6)把数据当作“元组”(tuple)来加载
还是假设有如下数据:
|
1
2
3
4
5
6
7
|
[root@localhost pig]$
cat
a.txt
a 1 2 3 4.2 9.8
a 3 0 5 3.5 2.1
b 7 9 9 - -
a 7 9 9 2.6 6.2
a 1 2 5 7.7 5.9
a 1 2 3 1.4 0.2
|
如果我们按照以下方式来加载数据:
|
1
|
A =
LOAD
'a.txt'
AS
(col1:chararray, col2:
int
, col3:
int
, col4:
int
, col5:
double
, col6:
double
);
|
那么得到的A的数据结构为:
|
1
2
|
grunt> DESCRIBE A;
A: {col1: chararray,col2:
int
,col3:
int
,col4:
int
,col5:
double
,col6:
double
}
|
如果你要把A当作一个元组(tuple)来加载:
|
1
|
A =
LOAD
'a.txt'
AS
(T : tuple (col1:chararray, col2:
int
, col3:
int
, col4:
int
, col5:
double
, col6:
double
));
|
也就是想要得到这样的数据结构:
|
1
2
|
grunt> DESCRIBE A;
A: {T: (col1: chararray,col2:
int
,col3:
int
,col4:
int
,col5:
double
,col6:
double
)}
|
那么,上面的方法将得到一个空的A:
|
1
2
3
4
5
6
7
|
grunt> DUMP A;
()
()
()
()
()
()
|
那是因为数据文件a.txt的结构不适合于这样加载成元组(tuple)。
文章来源:http://www.codelast.com/
如果有数据文件b.txt:
|
1
2
3
4
5
6
7
|
[root@localhost pig]$
cat
b.txt
(a,1,2,3,4.2,9.8)
(a,3,0,5,3.5,2.1)
(b,7,9,9,-,-)
(a,7,9,9,2.6,6.2)
(a,1,2,5,7.7,5.9)
(a,1,2,3,1.4,0.2)
|
则使用上面所说的加载方法及结果为:
|
1
2
3
4
5
6
7
8
|
grunt> A = LOAD
'b.txt'
AS (T : tuple (col1:chararray, col2:int, col3:int, col4:int, col5:double, col6:double));
grunt> DUMP A;
((a,1,2,3,4.2,9.8))
((a,3,0,5,3.5,2.1))
((b,7,9,9,,))
((a,7,9,9,2.6,6.2))
((a,1,2,5,7.7,5.9))
((a,1,2,3,1.4,0.2))
|
可见,加载的数据的结构确实被定义成了元组(tuple)。
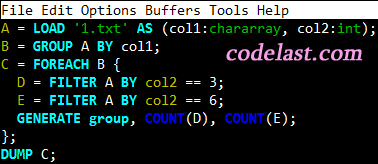
(7)在多维度组合下,如何计算某个维度组合里的不重复记录的条数
以数据文件 c.txt 为例:
|
1
2
3
4
5
6
7
|
[root@localhost pig]$
cat
c.txt
a 1 2 3 4.2 9.8 100
a 3 0 5 3.5 2.1 200
b 7 9 9 - - 300
a 7 9 9 2.6 6.2 300
a 1 2 5 7.7 5.9 200
a 1 2 3 1.4 0.2 500
|
问题:如何计算在第2、3、4列的所有维度组合下,最后一列不重复的记录分别有多少条?例如,第2、3、4列有一个维度组合是(1,2,3),在这个维度维度下,最后一列有两种值:100 和 500,因此不重复的记录数为2。同理可求得其他的记录条数。
pig代码及输出结果如下:
|
1
2
3
4
5
6
7
8
|
grunt> A = LOAD
'c.txt'
AS (col1:chararray, col2:int, col3:int, col4:int, col5:double, col6:double, col7:int);
grunt> B = GROUP A BY (col2, col3, col4);
grunt> C = FOREACH B {D = DISTINCT A.col7; GENERATE group, COUNT(D);};
grunt> DUMP C;
((1,2,3),2)
((1,2,5),1)
((3,0,5),1)
((7,9,9),1)
|
我们来看看每一步分别生成了什么样的数据:
①LOAD不用说了,就是加载数据;
②GROUP也不用说了,和前文所说的一样。GROUP之后得到了这样的数据:
|
1
2
3
4
5
|
grunt> DUMP B;
((1,2,3),{(a,1,2,3,4.2,9.8,100),(a,1,2,3,1.4,0.2,500)})
((1,2,5),{(a,1,2,5,7.7,5.9,200)})
((3,0,5),{(a,3,0,5,3.5,2.1,200)})
((7,9,9),{(b,7,9,9,,,300),(a,7,9,9,2.6,6.2,300)})
|
其实到这里,我们肉眼就可以看出来最后要求的结果是什么了,当然,必须要由pig代码来完成,要不然怎么应对海量数据?
文章来源:http://www.codelast.com/
③这里的 FOREACH 与前面有点不一样,这就是所谓的“嵌套的FOREACH”。第一次看到这种写法,肯定会觉得很奇怪。先看一下用于去重的DISTINCT关键字的说明:
Removes duplicate tuples in a relation.
然后再解释一下:FOREACH 是对B的每一行进行遍历,其中,B的每一行里含有一个包(bag),每一个包中含有若干元组(tuple)A,因此,FOREACH 后面的大括号里的操作,其实是对所谓的“内部包”(inner bag)的操作(详情请参看FOREACH的说明),在这里,我们指定了对A的col7这一列进行去重,去重的结果被命名为D,然后再对D计数(COUNT),就得到了我们想要的结果。
④输出结果数据,与前文所述的差不多。
这样就达成了我们的目的。从总体上说,刚接触pig不久的人会觉得这些写法怪怪的,就是扭不过来,但是要坚持,时间长了,连倒影也会让你觉得是正的了。
(8)如何将关系(relation)转换为标量(scalar)
在前文中,我们要统计符合某些条件的数据的条数,使用了COUNT函数来计算,但在COUNT之后,我们得到的还是一个关系(relation),而不是一个标量的数字,如何把一个关系转换为标量,从而可以在后续处理中便于使用呢?
具体请看这个链接。
(9)pig中如何使用shell进行辅助数据处理
pig中可以嵌套使用shell进行辅助处理,下面,就以一个实际的例子来说明。
假设我们在某一步pig处理后,得到了类似于下面 b.txt 中的数据:
|
1
2
3
4
|
[root@localhost pig]$
cat
b.txt
1 5 98 = 7
34 8 6 3 2
62 0 6 = 65
|
问题:如何将数据中第4列中的“=”符号全部替换为9999?
pig代码及输出结果如下:
|
1
2
3
4
5
6
|
grunt> A = LOAD
'b.txt'
AS (col1:int, col2:int, col3:int, col4:chararray, col5:int);
grunt> B = STREAM A THROUGH `
awk
'{if($4 == "=") print $1"\t"$2"\t"$3"\t9999\t"$5; else print $0}'
`;
grunt> DUMP B;
(1,5,98,9999,7)
(34,8,6,3,2)
(62,0,6,9999,65)
|
我们来看看这段代码是如何做到的:
①加载数据,这个没什么好说的。
②通过“STREAM … THROUGH …”的方式,我们可以调用一个shell语句,用该shell语句对A的每一行数据进行处理。此处的shell逻辑为:当某一行数据的第4列为“=”符号时,将其替换为“9999”;否则就照原样输出这一行。
③输出B,可见结果正确。
(10)向pig脚本中传入参数
假设你的pig脚本输出的文件是通过外部参数指定的,则此参数不能写死,需要传入。在pig中,使用传入的参数如下所示:
|
1
|
STORE A
INTO
'$output_dir'
;
|
则这个“output_dir”就是个传入的参数。在调用这个pig脚本的shell脚本中,我们可以这样传入参数:
|
1
|
pig -param output_dir=
"/home/my_ourput_dir/"
my_pig_script.pig
|
这里传入的参数“output_dir”的值为“/home/my_output_dir/”。
文章来源:http://www.codelast.com/
(11)就算是同样一段pig代码,多次计算所得的结果也有可能是不同的
例如用AVG函数来计算平均值时,同样一段pig代码,多次计算所得的结果中,小数点的最后几位也有可能是不相同的(当然也有可能相同),大概是因为精度的原因吧。不过,一般来说小数点的最后几位已经不重要了。例如我对一个数据集进行处理后,小数点后13位才开始有不同,这样的精度完全足够了。
(12)如何编写及使用自定义函数(UDF)
请看这个链接:《Apache Pig中文教程(进阶)》
(13)什么是聚合函数(Aggregate Function)
在pig中,聚合函数就是那些接受一个输入包(bag),返回一个标量(scalar)值的函数。COUNT函数就是一个例子。
(14)COGROUP做了什么
与GROUP操作符一样,COGROUP也是用来分组的,不同的是,COGROUP可以按多个关系中的字段进行分组。
还是以一个实例来说明,假设有以下两个数据文件:
|
01
02
03
04
05
06
07
08
09
10
|
[root@localhost pig]$
cat
a.txt
uidk 12 3
hfd 132 99
bbN 463 231
UFD 13 10
[root@localhost pig]$
cat
b.txt
908 uidk 888
345 hfd 557
28790 re 00000
|
现在我们用pig做如下操作及得到的结果为:
|
1
2
3
4
5
6
7
8
9
|
grunt> A =
LOAD
'a.txt'
AS
(acol1:chararray, acol2:
int
, acol3:
int
);
grunt> B =
LOAD
'b.txt'
AS
(bcol1:
int
, bcol2:chararray, bcol3:
int
);
grunt> C = COGROUP A
BY
acol1, B
BY
bcol2;
grunt> DUMP C;
(re,{},{(28790,re,0)})
(UFD,{(UFD,13,10)},{})
(bbN,{(bbN,463,231)},{})
(hfd,{(hfd,132,99)},{(345,hfd,557)})
(uidk,{(uidk,12,3)},{(908,uidk,888)})
|
每一行输出的第一项都是分组的key,第二项和第三项分别都是一个包(bag),其中,第二项是根据前面的key找到的A中的数据包,第三项是根据前面的key找到的B中的数据包。
来看看第一行输出:“re”作为group的key时,其找不到对应的A中的数据,因此第二项就是一个空的包“{}”,“re”这个key在B中找到了对应的数据(28790 re 00000),因此第三项就是包{(28790,re,0)}。
其他输出数据也类似。
(15)安装pig后,运行pig命令时提示“Cannot find hadoop configurations in classpath”等错误的解决办法
pig安装好后,运行pig命令时提示以下错误:
ERROR org.apache.pig.Main - ERROR 4010: Cannot find hadoop configurations in classpath (neither hadoop-site.xml nor core-site.xml was found in the classpath).If you plan to use local mode, please put -x local option in command line
显而易见,提示找不到与hadoop相关的配置文件。所以我们需要把hadoop安装目录下的“conf”子目录添加到系统环境变量PATH中:
修改 /etc/profile 文件,添加:
|
1
2
3
4
|
export
HADOOP_HOME=
/usr/local/hadoop
export
PIG_CLASSPATH=$HADOOP_HOME
/conf
PATH=$JAVA_HOME
/bin
:$HADOOP_HOME
/bin
:$PIG_CLASSPATH:$PATH
|
然后重新加载 /etc/profile 文件:
|
1
|
source
/etc/profile
|
文章来源:http://www.codelast.com/
(16)piggybank是什么东西
Pig also hosts a UDF repository called piggybank that allows users to share UDFs that they have written.
说白了就是Apache把大家写的自定义函数放在一块儿,起了个名字,就叫做piggybank。你可以把它理解为一个SVN代码仓库。具体请看这里。
(17)UDF的构造函数会被调用几次
你可能会想在UDF的构造函数中做一些初始化的工作,例如创建一些文件,等等。但是你不能假设UDF的构造函数只被调用一次,因此,如果你要在构造函数中做一些只能做一次的工作,你就要当心了——可能会导致错误。
(18)LOAD数据时,如何一次LOAD多个目录下的数据
例如,我要LOAD两个HDFS目录下的数据:/abc/2010 和 /abc/2011,则我们可以这样写LOAD语句:
|
1
|
A =
LOAD
'/abc/201{0,1}'
;
|
(19)怎样自己写一个UDF中的加载函数(load function)
请看这个链接:《Apache Pig中文教程(进阶)》
(20)重载(overloading)一个UDF
请看这个链接:《Apache Pig中文教程(进阶)》。
(21)pig运行不起来,提示“org.apache.hadoop.ipc.Client - Retrying connect to server:
请看这个链接:《Apache Pig中文教程(进阶)》
(22)用含有null的字段来GROUP,结果会如何
假设有数据文件 a.txt 内容为:
|
1
2
3
4
|
1 2 5
1 3
1 3
6 9 8
|
其中,每两列数据之间是用tab分割的,第二行的第2列、第三行的第3列没有内容(也就是说,加载到Pig里之后,对应的数据会变成null),如果把这些数据按第1、第2列来GROUP的话,第1、2列中含有null的行会被忽略吗?
来做一下试验:
|
1
2
3
|
A =
LOAD
'a.txt'
AS
(col1:
int
, col2:
int
, col3:
int
);
B =
GROUP
A
BY
(col1, col2);
DUMP B;
|
输出结果为:
|
1
2
3
4
|
((1,2),{(1,2,5)})
((1,3),{(1,3,)})
((1,),{(1,,3)})
((6,9),{(6,9,8)})
|
从上面的结果(第三行)可见,原数据中第1、2列里含有null的行也被计入在内了,也就是说,GROUP操作是不会忽略null的,这与COUNT有所不同(见本文前面的部分)。
(23)如何统计数据中某些字段的组合有多少种
假设有如下数据:
|
1
2
3
4
5
|
[root@localhost]
# cat a.txt
1 3 4 7
1 3 5 4
2 7 0 5
9 8 6 6
|
现在我们要统计第1、2列的不同组合有多少种,对本例来说,组合有三种:
|
1
2
3
|
1 3
2 7
9 8
|
也就是说我们要的答案是3。
用Pig怎么计算?
文章来源:http://www.codelast.com/
先写出全部的Pig代码:
|
1
2
3
4
5
|
A =
LOAD
'a.txt'
AS
(col1:
int
, col2:
int
, col3:
int
, col4:
int
);
B =
GROUP
A
BY
(col1, col2);
C =
GROUP
B
ALL
;
D = FOREACH C GENERATE
COUNT
(B);
DUMP D;
|
然后再来看看这些代码是如何计算出上面的结果的:
①第一行代码加载数据,没什么好说的。
②第二行代码,得到第1、2列数据的所有组合。B的数据结构为:
|
1
2
|
grunt> DESCRIBE B;
B: {
group
: (col1:
int
,col2:
int
),A: {col1:
int
,col2:
int
,col3:
int
,col4:
int
}}
|
把B DUMP出来,得到:
|
1
2
3
|
((1,3),{(1,3,4,7),(1,3,5,4)})
((2,7),{(2,7,0,5)})
((9,8),{(9,8,6,6)})
|
非常明显,(1,3),(2,7),(9,8)的所有组合已经被排列出来了,这里得到了若干行数据。下一步我们要做的就是统计这样的数据一共有多少行,也就得到了第1、2列的组合有多少组。
③第三和第四行代码,就实现了统计数据行数的功能。参考本文前面部分的“怎样统计数据行数”一节。就明白这两句代码是什么意思了。
这里需要特别说明的是:
a)为什么倒数第二句代码中是COUNT(B),而不是COUNT(group)?
我们是对C进行FOREACH,所以要先看看C的数据结构:
|
1
2
|
grunt> DESCRIBE C;
C: {
group
: chararray,B: {
group
: (col1:
int
,col2:
int
),A: {col1:
int
,col2:
int
,col3:
int
,col4:
int
}}}
|
可见,你可以把C想像成一个map的结构,key是一个group,value是一个包(bag),它的名字是B,这个包中有N个元素,每一个元素都对应到②中所说的一行。根据②的分析,我们就是要统计B中元素的个数,因此,这里当然就是COUNT(B)了。
b)COUNT函数的作用是统计一个包(bag)中的元素的个数:
COUNTComputes the number of elements in a bag.
如果你试图把COUNT应用于一个非bag的数据结构上,会发生错误,例如:
|
1
|
java.lang.ClassCastException: org.apache.pig.data.BinSedesTuple cannot be cast to org.apache.pig.data.DataBag
|
这是把Tuple传给COUNT函数时发生的错误。
(24)两个整型数相除,如何转换为浮点型,从而得到正确的结果
这个问题其实很傻,或许不用说你也知道了:假设有int a = 3 和 int b = 2两个数,在大多数编程语言里,a/b得到的是1,想得到正确结果1.5的话,需要转换为float再计算。在Pig中其实和这种情况一样,下面就拿几行数据来做个实验:
|
1
2
3
|
[root@localhost ~]# cat a.txt
3 2
4 5
|
在Pig中:
|
1
2
3
4
5
|
grunt> A =
LOAD
'a.txt'
AS
(col1:
int
, col2:
int
);
grunt> B = FOREACH A GENERATE col1/col2;
grunt> DUMP B;
(1)
(0)
|
可见,不加类型转换的计算结果是取整之后的值。
那么,转换一下试试:
|
1
2
3
4
5
|
grunt> A =
LOAD
'a.txt'
AS
(col1:
int
, col2:
int
);
grunt> B = FOREACH A GENERATE (
float
)(col1/col2);
grunt> DUMP B;
(1.0)
(0.0)
|
这样转换还是不行的,这与大多数编程语言的结果一致——它只是把取整之后的数再转换为浮点数,因此当然是不行的。
文章来源:http://www.codelast.com/
正确的做法应该是:
|
1
2
3
4
5
|
grunt> A =
LOAD
'a.txt'
AS
(col1:
int
, col2:
int
);
grunt> B = FOREACH A GENERATE (
float
)col1/col2;
grunt> DUMP B;
(1.5)
(0.8)
|
或者这样也行:
|
1
2
3
4
5
|
grunt> A =
LOAD
'a.txt'
AS
(col1:
int
, col2:
int
);
grunt> B = FOREACH A GENERATE col1/(
float
)col2;
grunt> DUMP B;
(1.5)
(0.8)
|
这与我们的通常做法是一致的,因此,你要做除法运算的时候,需要注意这一点。
(25)UNION的一个例子
假设有两个数据文件为:
|
1
2
3
4
5
6
7
8
|
[root@localhost ~]
# cat 1.txt
0 3
1 5
0 8
[root@localhost ~]
# cat 2.txt
1 6
0 9
|
现在要求出:在第一列相同的情况下,第二列的和分别为多少?
例如,第一列为 1 的时候,第二列有5和6两个值,和为11。同理,第一列为0的时候,第二列的和为 3+8+9=20。
计算此问题的Pig代码如下:
|
1
2
3
4
5
6
|
A =
LOAD
'1.txt'
AS
(a:
int
, b:
int
);
B =
LOAD
'2.txt'
AS
(c:
int
, d:
int
);
C =
UNION
A, B;
D =
GROUP
C
BY
$0;
E = FOREACH D GENERATE FLATTEN(
group
),
SUM
(C.$1);
DUMP E;
|
输出为:
|
1
2
|
(0,20)
(1,11)
|
文章来源:http://www.codelast.com/
我们来看看每一步分别做了什么:
①第1行、第2行代码分别加载数据到关系A、B中,没什么好说的。
②第3行代码,将关系A、B合并起来了。合并后的数据结构为:
|
1
2
|
grunt> DESCRIBE C;
C: {a:
int
,b:
int
}
|
其数据为:
|
1
2
3
4
5
6
|
grunt> DUMP C;
(0,3)
(1,5)
(0,8)
(1,6)
(0,9)
|
③第4行代码按第1列(即$0)进行分组,分组后的数据结构为:
|
1
2
|
grunt> DESCRIBE D;
D: {
group
:
int
,C: {a:
int
,b:
int
}}
|
其数据为: