大话Sheepdog 1 – 智能节点管理
Sheepdog是开源的分布式块存储项目,具有零配置、Thin-Provision、高可靠、智能节点管理、容量线性扩展、虚拟机感知(底层支持冷热迁移和快照、克隆等)、支持计算与存储混合架构的特点等,可扩展到上千级别的物理节点。开源软件如QEMU、Libvirt以及Openstack都很好的集成了对Sheepdog的支持。
本系列将手把手让读者体验Sheepdog的各种功能,并解释背后的工作机制和原理。Sheepdog目前只支持Linux的环境,对文件系统没有任何假设。本文以Ubuntu 12.04为背景,假设GIT、GCC、Autoconf以及Make等常见的编译环境已经配置好了。读者可以根据自己的环境微调命令。
建立环境
|
1
2
3
4
5
6
7
8
9
|
# 编译一个最新的Sheepdog执行文件
$
sudo
apt-get
install
liburcu-dev
$ git clone git:
//github
.com
/collie/sheepdog
.git
$
cd
sheepdog
$ .
/autogen
.sh; .
/configure
--disable-corosync
$
make
;
sudo
make
install
# 建立一个3节点的Sheepdog集群,利用操作系统的IPC和SHM机制来实现节点管理
$
for
i
in
0 1 2;
do
sheep
/tmp/store
$i -c
local
-z $i -p 700$i;
done
$ collie cluster
format
-b plain
|
编译后的Sheepdog主要由两个部分组成,一个是守护程序sheep,一个是集群管理程序collie。守护程序sheep同时兼备了节点路由和和对象存储的功能。整体架构如下图所示:
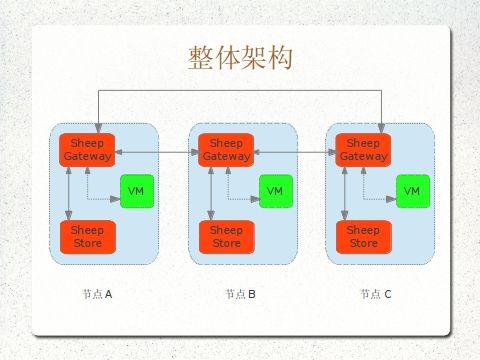
sheep进程之间通过节点路由(gateway)的逻辑转发请求,而具体的对象通过对象存储的逻辑保存在各个节点上,这就把所有节点上的存储空间聚合起来,形成一个共享的存储空间。
体验节点的智能管理
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
# 安装QEMU-kvm
$
sudo
apt-get
install
kvm
# 下载一个镜像
$ wget http:
//wiki
.qemu.org
/download/linux-0
.2.img.bz2
$ bunzip2 linux-0.2.img.bz2
# 将下载的镜像转换成sheepdog卷,默认为raw格式
# Sheepdog支持所有的QEMU格式,比如qcow2,但是默认的raw的性能是最好的
$ kvm-img convert -t directsync linux-0.2.img sheepdog:
test
$ collie vdi list
# 可以看见已经转化为Sheepdog卷了
$ collie node info
# 查看节点的信息
$ collie vdi create data 1G
# 创建一个1G data卷,同样可以通过'collie vdi list'确认下
$ kvm -hda sheepdog:
test
-hdb sheepdog:data
# 启动镜像并挂载data
# 进入虚拟机后,可以尝试dd if=/dev/urandom of=/dev/hdb把data卷写满
# 做IO的同时,我们尝试加入新的节点。注意到节点的添加和删除对于IO操作是没有影响的。
$ sheep
/tmp/store3
-c
local
-z 3 -p 7003
# 加入一个新节点就这么简单
$ collie node info
# 再次查看一下,集群的容量动态的增加了,数据也在各节点间自动均衡
$ pkill -f
"sheep /tmp/store2"
# 模拟节点2挂掉,IO还是在继续,数据在重新自动恢复!
$ sheep
/tmp/store2
-c
local
-z 2 -p 7002
# 重新加回节点2
# 模拟动态扩容,瞬间加入6个节点
$
for
i
in
`
seq
4 9`;
do
sheep
/tmp/store
$i -c
local
-z $i -p 700$i;
done
# 更多操作请看collie的帮助
|
智能节点管理背后的机制
在分布式文件系统中,一个大问题就是如何知道数据存放的位置。在本地文件系统中,通常通过元数据来索引数据具体的位置。因为元数据同数据可以放到一块逻辑卷(分区)上,所以通过简单的位图或者树等数据结构就可以建立一个完整的(数据,块号)映射表。而在分布式文件系统中,同样需要一定的机制来索引数据。如果使用元数据来索引数据,由于这些数据的地址空间远远超过了本地硬盘提供的容量,如Hadoop中的HDFS,元数据数据量非常大,需要单独的节点或者集群来存放大量的元数据。而Sheepdog同很多其它开源软件如GlusterFS一样基于对象存储,通过把数据对象与节点都映射到一个巨大的哈希空间来避免彻底避免元数据。对于块设备的对象存储,通俗的说就是把模拟的设备的块号同对象映射起来,然后分散存储这些对象,通常是一个对象有多个拷贝,以提高数据的可靠性。
对象、哈希空间以及节点的关系如何呢?这里做个简化的类比,比如,我们把哈希空间假设为[0, 300),然后A,B,C节点通过sheep定义的哈希函数计算ID的哈希值分别落在了0, 100, 200的位置,我们规定顺时针向后直到遇见下一个节点的空间都是属于这个节点的,那么A,B,C三个节点分别分得的空间为A[0, 100), B[100, 200), C[200, 300)。这样通过计算对象的ID我们得到一个哈希值,落在哪个空间就属于哪一个节点,这样我们就建立起了一个映射表。当一个节点,比如B挂掉的时候,这个时候空间在节点中重新分布,得到A[0,200),C[200,300)。可以看到B的数据空间分配到了A中,对于sheep也意味着B的数据将重新恢复到A中,而对于C是没有任何影响的。这就是Sheeepdog采用的一致性哈希算法最核心的思想。当然现实中,sheep的实现比这个稍微复杂点,为了更好的数据均衡,用到了虚拟节点的概念。
有了(对象,节点号)的映射,剩下的事情就是sheep进程之间如何定位然传递数据对象。很多开源软件如GlusterFS是实现DHT(Distributed Hash Table)来提供查找服务的。DHT最初是为广域网上的海量节点设计的,所以实现比较复杂。同时,为了实现节点的智能化管理,成员列表这个数据结构在所有的节点中都必须任何时刻完全一致,如果分散到各个节点中列表视图一致性维护起来异常复杂。节点之间通信时分布式查找也会是一个不小的开销。Sheepdog采用了全对称的结构,也就是每个节点都保存一个本地的节点数组(视图),数组的成员代表一个节点,其中包括IP地址等信息。这样通过节点ID查找节点位置,只是一个数组的下标解引用操作。找到目标节点对应的IP后,Sheepdog通过TCP的方式以点对点的形式来传递数据。
接下来的问题就是Sheepdog如何保证各个节点的视图一致性。Sheepdog是通过外部成熟的开源软件来实现可靠的视图一致性,比如Corosync和Zookeeper。对于这个视图,我们有两种操作,分别是添加和删除,对应的是节点的加入和(主动以及被动)退出。比如说我们有3个节点组成的集群(A,B,C),添加节点D进去就是向每一个成员包括D发送一个新的视图(A,B,C,D)。当然这是最简化的过程,实际中除了一个完整的新视图,sheep进程还需要知道谁是新添加的或者离开的节点。如果我们把视图抽象为消息,那么整个节点变化形成的新视图就成了一个消息序列。分布式系统中维护各个节点看到的消息序列的是一致的问题,是一个历史悠久而复杂的难题。目前有很多成熟的理论,比如Virtual Synchrony(Corosync采用),Paxos(Zookeeper采用),来保证消息序列的一致性。实现这些消息系统本身的难度已经大大超过了Sheepdog自己。正是站在这些巨人的肩膀上,才有了Sheepdog简单而智能的节点管理。
特别的指出,Sheepdog有内在的请求重试机制,所以节点变化的时候,很多无效的请求会根据新的视图进行重试,直到成功为止。所以节点的变化对于虚拟机来说,完全是透明的。对于IO路径会在以后的章节进行描述。