大小端模式
一、大端模式和小端模式的起源
关于大端小端名词的由来,有一个有趣的故事,来自于Jonathan Swift的《格利佛游记》:Lilliput和Blefuscu这两个强国在过去的36个月中一直在苦战。战争的原因:大家都知道,吃鸡蛋的时候,原始的方法是打破鸡蛋较大的一端,可以那时的皇帝的祖父由于小时侯吃鸡蛋,按这种方法把手指弄破了,因此他的父亲,就下令,命令所有的子民吃鸡蛋的时候,必须先打破鸡蛋较小的一端,违令者重罚。然后老百姓对此法令极为反感,期间发生了多次叛乱,其中一个皇帝因此送命,另一个丢了王位,产生叛乱的原因就是另一个国家Blefuscu的国王大臣煽动起来的,叛乱平息后,就逃到这个帝国避难。据估计,先后几次有11000余人情愿死也不肯去打破鸡蛋较小的端吃鸡蛋。这个其实讽刺当时英国和法国之间持续的冲突。Danny Cohen一位网络协议的开创者,第一次使用这两个术语指代字节顺序,后来就被大家广泛接受。二、什么是大端和小端
Big-Endian和Little-Endian的定义如下:1) Little-Endian就是低位字节排放在内存的低地址端,高位字节排放在内存的高地址端。
2) Big-Endian就是高位字节排放在内存的低地址端,低位字节排放在内存的高地址端。
举一个例子,比如数字0x12 34 56 78在内存中的表示形式为:
1)大端模式:
低地址 -----------------> 高地址0x12 | 0x34 | 0x56 | 0x78
2)小端模式:
低地址 ------------------> 高地址0x78 | 0x56 | 0x34 | 0x12
可见,大端模式和字符串的存储模式类似。
3)下面是两个具体例子:
| 内存地址 | 小端模式存放内容 | 大端模式存放内容 |
| 0x4000 | 0x34 | 0x12 |
| 0x4001 | 0x12 | 0x34 |
32bit宽的数0x12345678在Little-endian模式以及Big-endian模式)CPU内存中的存放方式(假设从地址0x4000开始存放)为:
| 内存地址 | 小端模式存放内容 | 大端模式存放内容 |
| 0x4000 | 0x78 | 0x12 |
| 0x4001 | 0x56 | 0x34 |
| 0x4002 | 0x34 | 0x56 |
| 0x4003 | 0x12 | 0x78 |
4)大端小端没有谁优谁劣,各自优势便是对方劣势:
小端模式 :强制转换数据不需要调整字节内容,1、2、4字节的存储方式一样。
大端模式 :符号位的判定固定为第一个字节,容易判断正负。
三、数组在大端小端情况下的存储:
以unsigned int value = 0x12345678为例,分别看看在两种字节序下其存储情况,我们可以用unsigned char buf[4]来表示value:Big-Endian: 低地址存放高位,如下:
高地址
---------------
buf[3] (0x78) -- 低位
buf[2] (0x56)
buf[1] (0x34)
buf[0] (0x12) -- 高位
---------------
低地址
Little-Endian: 低地址存放低位,如下:
高地址
---------------
buf[3] (0x12) -- 高位
buf[2] (0x34)
buf[1] (0x56)
buf[0] (0x78) -- 低位
--------------
低地址
四、为什么会有大小端模式之分呢?
这是因为在计算机系统中,我们是以字节为单位的,每个地址单元都对应着一个字节,一个字节为8bit。但是在C语言中除了8bit的char之外,还有16bit的short型,32bit的long型(要看具体的编译器),另外,对于位数大于8位的处理器,例如16位或者32位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如果将多个字节安排的问题。因此就导致了大端存储模式和小端存储模式。例如一个16bit的short型x,在内存中的地址为0x0010,x的值为0x1122,那么0x11为高字节,0x22为低字节。对于大端模式,就将0x11放在低地址中,即0x0010中,0x22放在高地址中,即0x0011中。小端模式,刚好相反。我们常用的X86结构是小端模式,而KEIL C51则为大端模式。很多的ARM,DSP都为小端模式。有些ARM处理器还可以由硬件来选择是大端模式还是小端模式。
五、如何判断机器的字节序
可以编写一个小的测试程序来判断机器的字节序:
int checkSystem()
{
union check
{
int i;
char ch;
}c;
c.i = 1;
return (c.ch==1); //true 1 表示小端模式
}
或者用下面这个代码也可以测试大小端模式:
bool IsBigEndian()
{
union NUM
{
int a;
char b;
}num;
num.a = 0x1234;
if( num.b == 0x12 )
{
return true;
}
return false;
}
六、常见的字节序
一般操作系统都是小端,而通讯协议是大端的。常见CPU的字节序
Big Endian : PowerPC、IBM、SunLittle Endian : x86、DEC
ARM既可以工作在大端模式,也可以工作在小端模式。
常见文件的字节序
Adobe PS – Big EndianBMP – Little Endian
DXF(AutoCAD) – Variable
GIF – Little Endian
JPEG – Big Endian
MacPaint – Big Endian
RTF – Little Endian
一个例子,请看下面的输出结果是多少?我的机器用上面的代码测试后是小端模式。
int main(void)
{
int a[5] = {1,2,3,4,5};
int* ptr1 = (int *)(&a+1);
int* ptr2 = (int *)((int)a+1);
printf("%x,%x\n",ptr1[-1],*ptr2);
printf("%d,%d\n",ptr1[-1],*ptr2);
system("pause");
}
先把结果拿出来
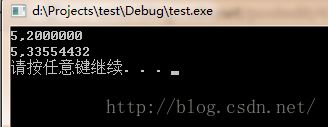
For ptr1:
经过调试数组a的首地址为0x002dfb80, &a+1表示把指针从a的首地址处移a数组大小,即移动5个int的大小(20)。20的16进制为0x14。所有&a+1的地址为0x002dfb80+0x14=0x002dfb94, 即ptr1的地址为0x002dfb94,ptr1[-1]就是地址0x002dfb94减一个int的大小,即ptr1[-1]=0x002dfb94-0x4=0x002dfb90。这里0x002dfb90的地址正好是a[4]的地址,所以结果是5。
For ptr2:
(int)a+1表示的是先把a转换为整形,然后再加1。最后把加1后的值作为一个指向int的指针。这里a本来就是数组的首地址。前面提到a的首地址为0x002dfb80,所有ptr2的地址为0x002dfb81.
这里注意,把ptr2输出来的时候就要考虑大小端模式了,我的环境为小端模式,所以地址的低位存储的是数据的高位。具体在内存中的存储为如下情况
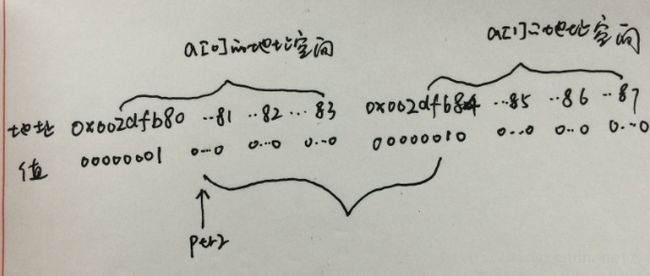
因ptr2指向的是int类型,所有把*ptr2输出的时候它会连续取四个字节。地址空间为0x002dfb81~0x002dfb84。该地址空间对应的数据为 00000000 00000000 00000000 00000010,把此数据用小端模式读取出来为0x02000000。所以以16进制输出的结果2000000,0x02000000转换为十进制为33554432.
Reference:http://blog.csdn.net/ce123_zhouwei/article/details/6971544