自己实现 一个MapReduce 示例
有这样一个实际的问题需要要通过hadoop的来解决一下。
有一个学生成绩表,有学生姓名 和成绩格式如下
zs 89 zs 100 ls 98 ls 100 zs 20 ww 89 ww 67 ls 30 ww 20
一个学生 有多个科目,有不同的成绩。
需要对每个同学的成绩求平均值。
同时,把这个student.txt 上传到 hadoop的 file System 中。
./bin/hadoop fs -put ~/file/student.txt
代码如下:
package com.picc.test;
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import com.picc.mapreducetest.MyMapReduceTest;
/***
* 定义一个AvgScore 求学生的平均值 要实现一个Tool 工具类,是为了初始化一个hadoop配置实例
*/
public class AvgScore implements Tool{
public static final Logger log=LoggerFactory.getLogger(AvgScore.class);
Configuration configuration;
// 是版本 0.20.2的实现
public static class MyMap extends Mapper<Object, Text, Text, IntWritable>{
@Override
protected void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String stuInfo = value.toString();//将输入的纯文本的数据转换成String
System.out.println("studentInfo:"+stuInfo);
log.info("MapSudentInfo:"+stuInfo);
//将输入的数据先按行进行分割
StringTokenizer tokenizerArticle = new StringTokenizer(stuInfo, "\n");
//分别对每一行进行处理
while(tokenizerArticle.hasMoreTokens()){
// 每行按空格划分
StringTokenizer tokenizer = new StringTokenizer(tokenizerArticle.nextToken());
String name = tokenizer.nextToken();//学生姓名
String score = tokenizer.nextToken();//学生成绩
Text stu = new Text(name);
int intscore = Integer.parseInt(score);
log.info("MapStu:"+stu.toString()+" "+intscore);
context.write(stu,new IntWritable(intscore));//输出学生姓名和成绩
}
}
}
public static class MyReduce extends Reducer<Text, IntWritable, Text, IntWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritable> values,Context context)
throws IOException, InterruptedException {
int sum=0;
int count=0;
Iterator<IntWritable> iterator= values.iterator();
while(iterator.hasNext()){
sum+=iterator.next().get();//计算总分
count++;//统计总科目
}
int avg= (int)sum/count;
context.write(key,new IntWritable(avg));//输出学生姓名和平均值
}
}
public int run(String [] args) throws Exception{
Job job = new Job(getConf());
job.setJarByClass(AvgScore.class);
job.setJobName("avgscore");
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setMapperClass(MyMap.class);
job.setCombinerClass(MyReduce.class);
job.setReducerClass(MyReduce.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.addInputPath(job, new Path(args[0]));//设置输入文件路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));//设置输出文件路径
boolean success= job.waitForCompletion(true);
return success ? 0 : 1;
}
public static void main(String[] args) throws Exception {
//在eclipse 工具上配置输入和输出参数
int ret = ToolRunner.run(new AvgScore(), args);
System.exit(ret);
}
@Override
public Configuration getConf() {
return configuration;
}
@Override
public void setConf(Configuration conf) {
conf = new Configuration();
configuration=conf;
}
}我在eclipse 上配置参数。会报异常。所以,我把以上代码导出成 avgscore.jar
把这个avgscore.jar 放到hadoop 0.20.2/目录下。
输入命令 ./bin/hadoop jar avgscore.jar com/picc/test/AvgScore input/student.txt out1
结果 图:


和计算的结果 没有错。
以下是对 以上算法的一个分析:
package com.picc.test;
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import com.picc.mapreducetest.MyMapReduceTest;
public class AvgScore implements Tool{
public static final Logger log=LoggerFactory.getLogger(AvgScore.class);
Configuration configuration;
public static class MyMap extends Mapper<Object, Text, Text, IntWritable>{
Configuration config = HBaseConfiguration.create();//获取hbase 的操作上下文
private static IntWritable linenum = new IntWritable(1);//初始化一个变量值
@Override
protected void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String stuInfo = value.toString();
System.out.println("studentInfo:"+stuInfo);
log.info("MapSudentInfo:"+stuInfo);
StringTokenizer tokenizerArticle = new StringTokenizer(stuInfo, "\n");
while(tokenizerArticle.hasMoreTokens()){
StringTokenizer tokenizer = new StringTokenizer(tokenizerArticle.nextToken());
String name = tokenizer.nextToken();
String score = tokenizer.nextToken();
Text stu = new Text(name);
int intscore = Integer.parseInt(score);
log.info("MapStu:"+stu.toString()+" "+intscore);
context.write(stu,new IntWritable(intscore)); //zs 90
//create 'stu','name','score'
HTable table=new HTable(config,"stu");
byte[] row1 = Bytes.toBytes("name"+linenum);
Put p1=new Put(row1);
byte[] databytes = Bytes.toBytes("name");
p1.add(databytes, Bytes.toBytes("1"), Bytes.toBytes(name));
table.put(p1);//put 'stu','name','name:1','zs'
table.flushCommits();
byte [] row2 = Bytes.toBytes("score"+linenum);
Put p2 = new Put(row2);
byte [] databytes2 = Bytes.toBytes("score");
p2.add(databytes2, Bytes.toBytes("1"), Bytes.toBytes(score));
table.put(p2);//put 'stu','score','score:1','90'
table.flushCommits();
linenum= new IntWritable(linenum.get()+1);//对变量值进行变值处理
}
}
}
public static class MyReduce extends Reducer<Text, IntWritable, Text, IntWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritable> values,Context context)
throws IOException, InterruptedException {
int sum=0;
int count=0;
Iterator<IntWritable> iterator= values.iterator();
while(iterator.hasNext()){
sum+=iterator.next().get();
count++;
}
int avg= (int)sum/count;
context.write(key,new IntWritable(avg));
}
}
public int run(String [] args) throws Exception{
Job job = new Job(getConf());
job.setJarByClass(AvgScore.class);
job.setJobName("avgscore");
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setMapperClass(MyMap.class);
job.setCombinerClass(MyReduce.class);
job.setReducerClass(MyReduce.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
boolean success= job.waitForCompletion(true);
return success ? 0 : 1;
}
public static void main(String[] args) throws Exception {
int ret = ToolRunner.run(new AvgScore(), args);
System.exit(ret);
}
@Override
public Configuration getConf() {
return configuration;
}
@Override
public void setConf(Configuration conf) {
conf = new Configuration();
configuration=conf;
}
}
这个代码是对上一个代码的调试分析处理后的代码,
把map 处理的过程放到的数据库中,在MapReduce 中处理 hbase数据时,需要 把hbase 的数据包放到hadoop的lib 包下。
处理的结果,见视图:
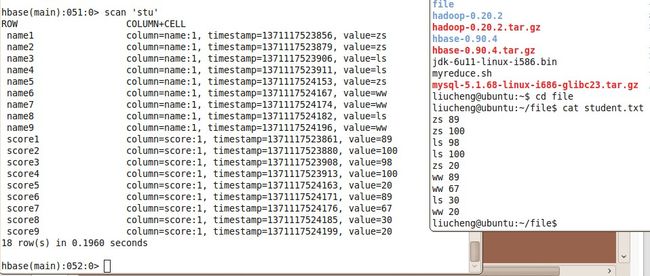
注意,在hbase数据库中 row中的Key是不能相同的,否则会 后一条会覆盖前一条值。需要保让其唯一性。
name1 和score1 是一条数据,这两列表是一个学生的成绩,和关系型数据库不同,以列值存储,思想需要转换一下。