MapReduce源码分析之架构分析1
前言
MapReduce的源码分析是基于Hadoop1.2.1基础上进行的代码分析。
本篇,将不会涉及代码部分的分析,只是简单分析map的整体架构,并介绍map与reduce的运行过程,主要是为后续的分析做一个铺垫。至于MapTask/ReduceTask的原理分析,JobTracker部分,以及TaskTracker如何启动一个Task这些都将在后续章节给出。
MR编程模型
MapReduce的编程模型是来自lisp,源于在函数式编程语言中可以通过reduce(map(fn())这种形式将问题进行拆分处理。
借鉴于此,MapReduce编程分为两个阶段,Map阶段和Reduce阶段。通过这种形式,用户只需要关心map函数和reduce函数的编写,就可以将复杂业务处理通过简单的MapReduce来实现。
map函数,接收输入数据的key/value键值对,进行处理,产生新的key/value键值对,作为中间数据,输出到磁盘上。MapReduce框架会对输出的key/value键值对,进行分区,同一个分区中的数据最后都会被同一个Reduce处理。
reduce函数,读取Map的输出结果,读取完成后进行排序,将排序后的有序的key/value键值对传递给reduce函数处理,处理完成后产生新的key/value键值对,输出到存储上(一般是hdfs上)。
MR架构

MapReduce框架的架构如上图所示,是采用比较常见的Master/Slave的架构模式。
在MapReduce中JobTracker负责作业的管理,资源监控。TaskTracker负责执行Task。Task可以分为MapTask和ReduceTask。
需要知道的是一个Job即代表了用户执行的一个分布式的计算过程的作业,而Task则表示一个作业会被拆分为许多个小的任务中的一个,Task可以分为Map阶段的任务或者是Reduce阶段的任务,也就是说Task是任务处理中的一个单元,有这个小的单元去完成一部分计算的任务,最后所有任务都完成,结果经过汇聚,就代表一个作业的处理完毕。
用户执行一个作业的过程如下:
1.用户提交作业,由JobClient将相关作业信息进行打包并传递到hdfs上,并通知JobTracker。
2.JobTracker接收到新的作业,对作业初始化。根据TaskTracker通过心跳汇报上来的负载信息,得知空闲资源分布情况。由任务调度器决定将任务下发到哪些有空闲资源的节点。
3.Tracker接收到任务后,启动单独的jvm运行Task。Task在运行过程中的状态都会先汇报给TaskTracker,再由TaskTracker汇报给JobTracker。
MapTask运行过程
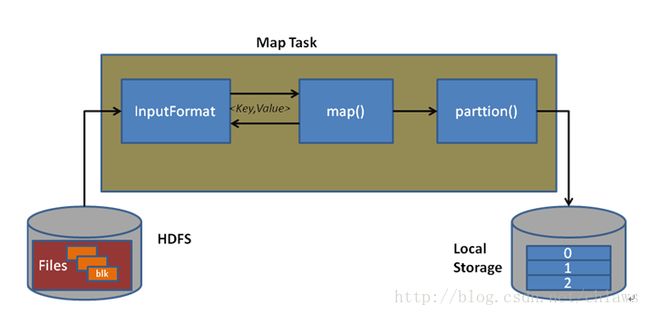
一个MapTask的运行过程如上图所示。运行过程可以分为三个阶段,分别是数据读取阶段,Map阶段,分区阶段。
数据读取阶段,是指InputFormat负责理解数据格式并解析成key,value传递给map函数处理。InputFormat提供了getInputSplit接口,负责将输入数据切分为一个个InputSplit(分片),同时还提供getRecordReader接口,负责解析InputSplit,通过RecordReader提取出key/value键值对。这些键值对就是作为map函数的输入。
Map阶段,是指运行用户实现的Mapper接口中的map函数,该函数负责对输入的key/value数据进行初步处理,产生新的key/value键值对作为中间数据保存在本地磁盘上。
分区阶段,map输出的临时数据,会被分成若干个分区,每个分区都会被一个ReduceTask处理。
ReduceTask运行过程

ReduceTask的执行过程如上图所示。该过程可以分为三个阶段,分别为Shuffle阶段,sort阶段,reduce阶段。
Shuffle阶段,是指ReduceTask通过查询JobTracker知道有哪些Map处理完毕。一旦有MapTask处理完毕,就会远程读取这些MapTask产生的临时数据。
Sort阶段,是指将读取的数据,按照key对key/value键值对进行排序。
Reduce阶段,是指运行用户实现的Reducer接口中的reduce函数,该函数读取sort阶段的有序的key/value键值对,进行处理,并将最终的处理结果存到hdfs上。
多Map和多Reduce运行分析
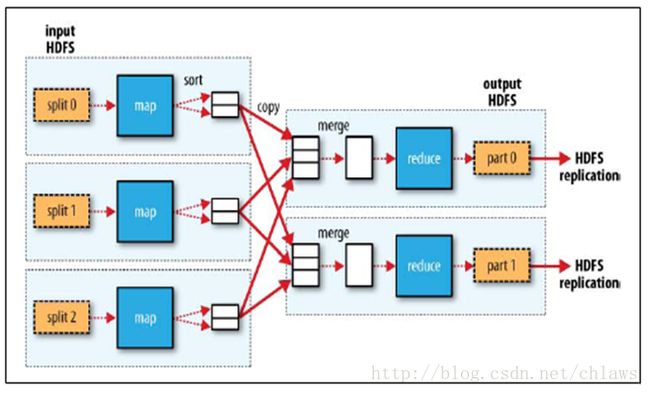
上图所示,是一个多MapTask和多ReduceTask的数据处理流程。这个Job用户指定的是3个Map和2个Reduce。
其处理过程是:
JobTracker启动3个MapTask,每个MapTask都从读取对应的InputSplit。MapTask调用用户实现的map函数,产生新的数据。至于数据会被划到哪个分区,这是有Partitioner控制的,默认情况下使用的HashPartitioner,相同的key最终都会被划到一个分区中,因为指定了2个ReduceTask所以数据会被分为两个分区。在中间数据产生到磁盘前都会对数据进行排序。保证每个分区中的数据都是有序的。
在Map运行中,会根据用户配置的Reduce在Map完成多少进度时启动。根据用户的配置JobTracker会在适当的时候向有空闲资源的TaskTracker下发ReduceTask,由TaskTracker启动ReduceTask。ReduceTask启动后,查询JobTracker获取它的输入源的Map是否已经有可读的数据。有则从发起http请求从这些MapTask输出的节点上拉取数据到本地。因为指定了3个Map,因此一个Reduce需要从3个Map读取数据。读取后需要对读取的数据进行归并排序,以保障数据的有序性。这时,才会调用到用户实现的reduce函数,做最后的处理,在处理完毕后,将数据存储到hdfs上。每个ReduceTask处理完成后,都会在hdfs上产生一个结果文件。因此这里就会在hdfs上看到有两个结果文件。