Mahout实例(UserCF,ItermCF,SlopOne)
一般,电影推荐系统测试数据来源:http://grouplens.org/datasets/movielens/
最近,在研究数据挖掘中的推荐系统,很深奥,还专门买了一本《推荐系统实践》的书,里面讲解的还行吧,凑活!在网上也是看各种博客,各种资料!!
自己也尝试了自己动手实现一下,但是比起Mahout开源项目中的算法效率,我写的效率很低,所以就决定使用Mahout了,虽然Mahout只是封装了一些基本的推荐算法,但是基本上够我用了~~
在这里需要说明一下,推荐算法是一个不断优化,不断提升的循序渐进的过程,是不可能一蹴而就的~~~而且推荐算法的效率要视情况而定,适合你的项目的才是最好的!!
在这里贴出,我用Mahout实现的简单的三个算法:UserCF,ItemCF,SlopeOne
基于用户的协同过滤算法(UserCF)
import java.io.File;
import java.io.IOException;
import java.util.List;
import org.apache.mahout.cf.taste.eval.RecommenderBuilder;
import org.apache.mahout.cf.taste.hadoop.item.RecommenderJob;
import org.apache.mahout.cf.taste.impl.common.FastByIDMap;
import org.apache.mahout.cf.taste.impl.common.FastIDSet;
import org.apache.mahout.cf.taste.impl.common.LongPrimitiveIterator;
import org.apache.mahout.cf.taste.impl.model.GenericBooleanPrefDataModel;
import org.apache.mahout.cf.taste.impl.model.file.FileDataModel;
import org.apache.mahout.cf.taste.impl.neighborhood.NearestNUserNeighborhood;
import org.apache.mahout.cf.taste.impl.recommender.GenericUserBasedRecommender;
import org.apache.mahout.cf.taste.impl.similarity.PearsonCorrelationSimilarity;//EuclideanDistanceSimilarity;
import org.apache.mahout.cf.taste.impl.similarity.UncenteredCosineSimilarity;
import org.apache.mahout.cf.taste.model.DataModel;
import org.apache.mahout.cf.taste.model.PreferenceArray;
import org.apache.mahout.cf.taste.recommender.RecommendedItem;
import org.apache.mahout.cf.taste.recommender.Recommender;
import org.apache.mahout.cf.taste.similarity.UserSimilarity;
/*
*
*
* 基于用户的协同过滤
*
* 利用apache mahout开源项目
*
* 通过基于用户的协同过滤算法,来给用户推荐商品
*
*/
public class UserBaseCFMain {
final static int NEIGHBORHOOD_NUM =3;//邻居数目
final static int RECOMMENDER_NUM = 7;//推荐物品数目
public static void main(String[] args) throws Exception {
String file = "E:\\test2.txt";
DataModel model =new FileDataModel(new File(file));//FileDataModel要求文件数据存储格式(必须用“,”分割):userID,itemID[,preference[,timestamp]]
UserSimilarity user = new PearsonCorrelationSimilarity(model);
NearestNUserNeighborhood neighbor = new NearestNUserNeighborhood(NEIGHBORHOOD_NUM, user, model);
Recommender r = new GenericUserBasedRecommender(model, neighbor, user);
LongPrimitiveIterator iter = model.getUserIDs();
while (iter.hasNext()) {
long uid = iter.nextLong();
List<RecommendedItem> list = r.recommend(uid, RECOMMENDER_NUM);
System.out.printf("uid:%s", uid);
for (RecommendedItem ritem : list) {
System.out.printf("(%s,%f)", ritem.getItemID(), ritem.getValue());
}
System.out.println();
}
}
}
基于物品的协同过滤(ItermCF)
import java.io.File;
import java.util.List;
import org.apache.mahout.cf.taste.impl.common.LongPrimitiveIterator;
import org.apache.mahout.cf.taste.impl.model.GenericBooleanPrefDataModel;
import org.apache.mahout.cf.taste.impl.model.file.FileDataModel;
import org.apache.mahout.cf.taste.impl.recommender.GenericItemBasedRecommender;
import org.apache.mahout.cf.taste.impl.similarity.PearsonCorrelationSimilarity;
import org.apache.mahout.cf.taste.model.DataModel;
import org.apache.mahout.cf.taste.recommender.RecommendedItem;
import org.apache.mahout.cf.taste.recommender.Recommender;
import org.apache.mahout.cf.taste.similarity.ItemSimilarity;
/*
*
* 基于物品相似度的推荐引擎
*
*
*/
public class MyItemBasedRecommender {
public static void main(String[] s) throws Exception{
DataModel model = new FileDataModel(new File("E:\\test2.txt"));//构造数据模型,File-based
//DataModel model=new GenericBooleanPrefDataModel(GenericBooleanPrefDataModel.toDataMap(model1));
ItemSimilarity similarity = new PearsonCorrelationSimilarity(model);//计算内容相似度
Recommender recommender = new GenericItemBasedRecommender(model, similarity);//构造推荐引擎
LongPrimitiveIterator iter = model.getUserIDs();
while (iter.hasNext()) {
long uid = iter.nextLong();
List<RecommendedItem> list = recommender.recommend(uid,3);
System.out.printf("uid:%s", uid);
for (RecommendedItem ritem : list) {
System.out.printf("(%s,%f)", ritem.getItemID(), ritem.getValue());
}
System.out.println();
}
}
}
SlopeOne
import java.io.File;
import java.util.List;
import org.apache.mahout.cf.taste.impl.common.LongPrimitiveIterator;
import org.apache.mahout.cf.taste.impl.model.file.FileDataModel;
import org.apache.mahout.cf.taste.impl.recommender.CachingRecommender;
import org.apache.mahout.cf.taste.impl.recommender.GenericItemBasedRecommender;
import org.apache.mahout.cf.taste.impl.recommender.slopeone.SlopeOneRecommender;
import org.apache.mahout.cf.taste.impl.similarity.PearsonCorrelationSimilarity;
import org.apache.mahout.cf.taste.model.DataModel;
import org.apache.mahout.cf.taste.recommender.RecommendedItem;
import org.apache.mahout.cf.taste.recommender.Recommender;
import org.apache.mahout.cf.taste.similarity.ItemSimilarity;
/*
* 基于Slop One的推荐引擎
*
* 基于用户和基于内容是最常用最容易理解的两种推荐策略,但在大数据量时,它们的计算量会很大,从而导致推荐效率较差。因此 Mahout 还提供了一种更加轻量级的 CF 推荐策略:Slope One。
Slope One 是有 Daniel Lemire 和 Anna Maclachlan 在 2005 年提出的一种对基于评分的协同过滤推荐引擎的改进方法,下面简单介绍一下它的基本思想。
假设系统对于物品 A,物品 B 和物品 C 的平均评分分别是 3,4 和 4。基于 Slope One 的方法会得到以下规律:
•用户对物品 B 的评分 = 用户对物品 A 的评分 + 1
•用户对物品 B 的评分 = 用户对物品 C 的评分
基于以上的规律,我们可以对用户 A 和用户 B 的打分进行预测:
•对用户 A,他给物品 A 打分 4,那么我们可以推测他对物品 B 的评分是 5,对物品 C 的打分也是 5。
•对用户 B,他给物品 A 打分 2,给物品 C 打分 4,根据第一条规律,我们可以推断他对物品 B 的评分是 3;而根据第二条规律,推断出评分是 4。当出现冲突时,我们可以对各种规则得到的推断进行就平均,所以给出的推断是 3.5。
这就是 Slope One 推荐的基本原理,它将用户的评分之间的关系看作简单的线性关系:
Y = mX + b;
当 m = 1 时就是 Slope One,也就是我们刚刚展示的例子。
*
*
*
*/
public class MySlopeOneRecommender {
public static void main(String[] s) throws Exception{
DataModel model = new FileDataModel(new File("E:\\test2.txt"));//构造数据模型
Recommender recommender = new CachingRecommender(new SlopeOneRecommender(model));//构造推荐引擎
LongPrimitiveIterator iter = model.getUserIDs();
while (iter.hasNext()) {
long uid = iter.nextLong();
List<RecommendedItem> list = recommender.recommend(uid,3);
System.out.printf("uid:%s", uid);
for (RecommendedItem ritem : list) {
System.out.printf("(%s,%f)", ritem.getItemID(), ritem.getValue());
}
System.out.println();
}
}
}
测试数据:
test2.txt部分数据
格式:用户ID,物品ID,评分,时间戳(默认前三项有用,时间戳忽略不计,在这里必须用“,”隔开)
1,1193,5,978300760
1,661,3,978302109
1,914,3,978301968
1,3408,4,978300275
1,2355,5,978824291
1,1197,3,978302268
1,1287,5,978302039
1,2804,5,978300719
1,594,4,978302268
1,919,4,978301368
1,595,5,978824268
1,938,4,978301752
1,2398,4,978302281
1,2918,4,978302124
1,1035,5,978301753
1,2791,4,978302188
1,2687,3,978824268
1,2018,4,978301777
1,3105,5,978301713
1,2797,4,978302039
1,2321,3,978302205
1,720,3,978300760
1,1270,5,978300055
1,527,5,978824195
1,2340,3,978300103
1,48,5,978824351
1,1097,4,978301953
在这里呢,我还没有实现用其他标点分割,也没实现“用户ID,物品ID”存储结构的读取~~请大家谁知道的,留言!
在此呢,我利用上述三种算法实现了一个web版的推荐,下面是截图:

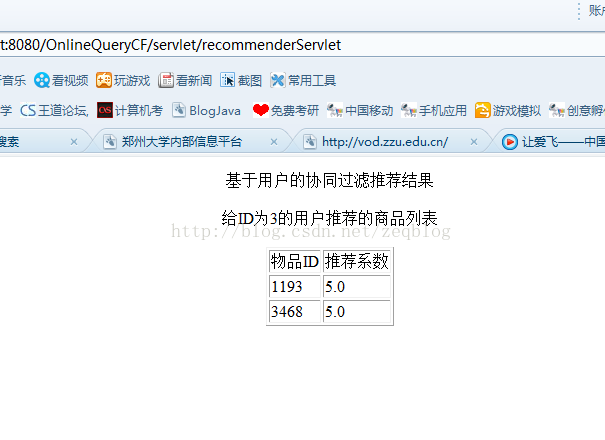
源代码(包含测试数据):http://download.csdn.net/detail/zeq9069/6572319