http://yugouai.iteye.com/blog/1851606
整理了一下网上的几种Hive文件存储格式的性能与Hadoop的文件存储格式。
Hive的三种文件格式:TEXTFILE、SEQUENCEFILE、RCFILE中,TEXTFILE和SEQUENCEFILE的存储格式都是基于行存储的,RCFILE是基于行列混合的思想,先按行把数据划分成N个row group,在row group中对每个列分别进行存储。另:Hive能支持自定义格式,详情见:Hive文件存储格式
基于HDFS的行存储具备快速数据加载和动态负载的高适应能力,因为行存储保证了相同记录的所有域都在同一个集群节点。但是它不太满足快速的查询响应时间的要求,因为当查询仅仅针对所有列中的 少数几列时,它就不能跳过不需要的列,直接定位到所需列;同时在存储空间利用上,它也存在一些瓶颈,由于数据表中包含不同类型,不同数据值的列,行存储不 易获得一个较高的压缩比。RCFILE是基于SEQUENCEFILE实现的列存储格式。除了满足快速数据加载和动态负载高适应的需求外,也解决了SEQUENCEFILE的一些瓶颈。
下面对这几种几个作一个简单的介绍:
TextFile:
Hive默认格式,数据不做压缩,磁盘开销大,数据解析开销大。
可结合Gzip、Bzip2、Snappy等使用(系统自动检查,执行查询时自动解压),但使用这种方式,hive不会对数据进行切分,从而无法对数据进行并行操作。
SequenceFile:
SequenceFile是Hadoop API 提供的一种二进制文件,它将数据以<key,value>的形式序列化到文件中。这种二进制文件内部使用Hadoop 的标准的Writable 接口实现序列化和反序列化。它与Hadoop API中的MapFile 是互相兼容的。Hive 中的SequenceFile 继承自Hadoop API 的SequenceFile,不过它的key为空,使用value 存放实际的值, 这样是为了避免MR 在运行map 阶段的排序过程。
SequenceFile的文件结构图:
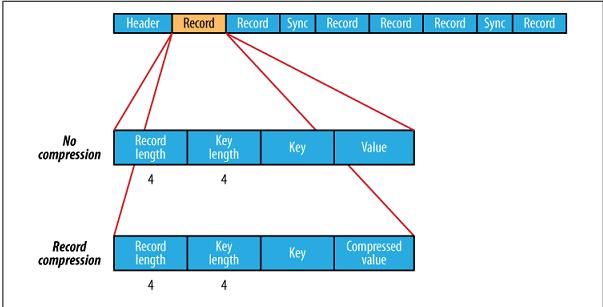
Header通用头文件格式:
| SEQ |
3BYTE |
| Nun |
1byte数字 |
| keyClassName |
|
| ValueClassName |
|
| compression |
(boolean)指明了在文件中是否启用压缩 |
| blockCompression |
(boolean,指明是否是block压缩) |
| compression |
codec |
| Metadata |
文件元数据 |
| Sync |
头文件结束标志 |
Block-Compressed SequenceFile格式

RCFile
RCFile是Hive推出的一种专门面向列的数据格式。 它遵循“先按列划分,再垂直划分”的设计理念。当查询过程中,针对它并不关心的列时,它会在IO上跳过这些列。需要说明的是,RCFile在map阶段从 远端拷贝仍然是拷贝整个数据块,并且拷贝到本地目录后RCFile并不是真正直接跳过不需要的列,并跳到需要读取的列, 而是通过扫描每一个row group的头部定义来实现的,但是在整个HDFS Block 级别的头部并没有定义每个列从哪个row group起始到哪个row group结束。所以在读取所有列的情况下,RCFile的性能反而没有SequenceFile高。
下面介绍行存储、列存储(详细参照:Facebook数据仓库揭秘:RCFile高效存储结构)
行存储
HDFS块内行存储的例子:

基于Hadoop系统行存储结构的优点在于快速数据加载和动态负载的高适应能力,这是因为行存储保证了相同记录的所有域都在同一个集群节点,即同一个 HDFS块。不过,行存储的缺点也是显而易见的,例如它不能支持快速查询处理,因为当查询仅仅针对多列表中的少数几列时,它不能跳过不必要的列读取;此 外,由于混合着不同数据值的列,行存储不易获得一个极高的压缩比,即空间利用率不易大幅提高。
列存储
HDFS块内列存储的例子

在HDFS上按照列组存储表格的例子。在这个例子中,列A和列B存储在同一列组,而列C和列D分别存储在单独的列组。查询时列存储能够避免读不必要的列, 并且压缩一个列中的相似数据能够达到较高的压缩比。然而,由于元组重构的较高开销,它并不能提供基于Hadoop系统的快速查询处理。列存储不能保证同一 记录的所有域都存储在同一集群节点,行存储的例子中,记录的4个域存储在位于不同节点的3个HDFS块中。因此,记录的重构将导致通过集群节点网络的大 量数据传输。尽管预先分组后,多个列在一起能够减少开销,但是对于高度动态的负载模式,它并不具备很好的适应性。
RCFile结合行存储查询的快速和列存储节省空间的特点:首先,RCFile保证同一行的数据位于同一节点,因此元组重构的开销很低;其次,像列存储一样,RCFile能够利用列维度的数据压缩,并且能跳过不必要的列读取。
HDFS块内RCFile方式存储的例子:

数据测试
源表数据记录数:67236221
第一步:创建三种文件类型的表,建表语法参考Hive文件存储格式
-
- set hive.exec.compress.output=true;
- set mapred.output.compress=true;
- set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec;
- set io.compression.codecs=org.apache.hadoop.io.compress.GzipCodec;
- INSERT OVERWRITE table hzr_test_text_table PARTITION(product='xxx',dt='2013-04-22')
- SELECT xxx,xxx.... FROM xxxtable WHERE product='xxx' AND dt='2013-04-22';
-
-
- set hive.exec.compress.output=true;
- set mapred.output.compress=true;
- set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec;
- set io.compression.codecs=org.apache.hadoop.io.compress.GzipCodec;
- set io.seqfile.compression.type=BLOCK;
- INSERT OVERWRITE table hzr_test_sequence_table PARTITION(product='xxx',dt='2013-04-22')
- SELECT xxx,xxx.... FROM xxxtable WHERE product='xxx' AND dt='2013-04-22';
-
-
- set hive.exec.compress.output=true;
- set mapred.output.compress=true;
- set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec;
- set io.compression.codecs=org.apache.hadoop.io.compress.GzipCodec;
- INSERT OVERWRITE table hzr_test_rcfile_table PARTITION(product='xxx',dt='2013-04-22')
- SELECT xxx,xxx.... FROM xxxtable WHERE product='xxx' AND dt='2013-04-22';
第二步:测试insert overwrite table tablename select.... 耗时,存储空间
| 类型 |
insert耗时(S) |
存储空间(G) |
| Sequence |
97.291 |
7.13G |
| RCFile |
120.901 |
5.73G |
| TextFile |
290.517
|
6.80G |
insert耗时、count(1)耗时比较:


第三步:查询响应时间
测试一
- 方案一,测试整行记录的查询效率:
- select * from hzr_test_sequence_table where game='XXX' ;
- select * from hzr_test_rcfile_table where game='XXX' ;
- select * from hzr_test_text_table where game='XXX' ;
-
- 方案二,测试特定列的查询效率:
- select game,game_server from hzr_test_sequence_table where game ='XXX';
- select game,game_server from hzr_test_rcfile_table where game ='XXX';
- select game,game_server from hzr_test_text_table where game ='XXX';
| 文件格式 |
查询整行记录耗时(S) |
查询特定列记录耗时(S) |
| sequence |
42.241 |
39.918 |
| rcfile |
37.395 |
36.248 |
| text |
43.164 |
41.632 |
方案耗时对比:

测试二:
本测试目的是验证RCFILE的数据读取方式和Lazy解压方式是否有性能优势。数据读取方式只读取元数据和相关的列,节省IO;Lazy解压方式只解压相关的列数据,对不满足where条件的查询数据不进行解压,IO和效率都有优势。
方案一:
记录数:698020
- insert overwrite local directory 'XXX/XXXX' select game,game_server from hzr_test_xxx_table where game ='XXX';
方案二:
记录数:67236221
- insert overwrite local directory 'xxx/xxxx' select game,game_server from hzr_test_xxx_table;
方案三:
记录数:
- insert overwrite local directory 'xxx/xxx'
- select game from hzr_xxx_rcfile_table;
| 文件类型 |
方案一 |
方案二 |
方案三 |
| TextFile |
54.895 |
69.428 |
167.667 |
| SequenceFile |
137.096 |
77.03 |
123.667 |
| RCFile |
44.28 |
57.037 |
89.9 |

上图表现反应在大小数据集上,RCFILE的查询效率高于SEQUENCEFILE,在特定字段数据读取时,RCFILE的查询效率依然优于SEQUENCEFILE。

- 大小: 21.8 KB

- 大小: 19.1 KB

- 大小: 165 KB

- 大小: 91.6 KB

- 大小: 94.1 KB

- 大小: 20.3 KB

- 大小: 18.7 KB

- 大小: 20 KB

- 描述: aaa
- 大小: 16.4 KB