hadoop下mahout kmeans算法研究(1)
KMeans算法和简单命令使用(1)
如果对本文档有任何建议或者认为有错误的地方欢迎联系本人
大家一起进步啊
红色的字体:重点和注意事项
蓝色的字体:出现的问题和解决/未解决
绿色的字体:个人建议
Tips:在要输入路径的命令使用时最好在路径的前后都加”/”分开,这样不容易出错
如:hadoop fs -put /root/input/kmeans.data/ testdata
具体每种命令如何用及参数选择,可以在命令行后面加-h或-help,例如,查看mahout seqdumper -h,这样终端下,就会列出详细的参数选项及说明
算法简介
同一聚类中的对象相似度较高;而不同聚类中的对象相似度较小
以空间中k个点为中心进行聚类,对最靠近他们的对象归类。通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果。
首先从n个数据对象任意选择 k个对象作为初始聚类中心;而对于所剩下其它对象,则根据它们与这些聚类中心的相似度(距离),分别将它们分配给与其最相似的(聚类中心所代表的)聚类;然后再计算每个所获新聚类的聚类中心(该聚类中所有对象的均值);不断重复这一过程直到标准测度函数开始收敛为止。一般都采用均方差作为标准测度函数. k个聚类具有以下特点:各聚类本身尽可能的紧凑,而各聚类之间尽可能的分开。
对于每一个 cluster,我们可以选出一个中心点 (center),使得该 cluster中的所有的点到该中心点的距离小于到其他 cluster的中心的距离
建立文件
https://cwiki.apache.org/confluence/display/MAHOUT/Clustering+of+synthetic+control+data
下载数据集synthetic_control.data,在以上官网上的Input data set. Download it here点击可下载
把里面的内容复制到了testdata文件上并放在了/root/input目录下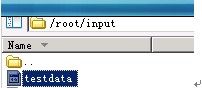
转换成seq文件
首先简单说明下,mahout下处理的文件必须是SequenceFile格式的,所以需要把txtfile转换成sequenceFile。SequenceFile是hadoop中的一个类,允许我们向文件中写入二进制的键值对,具体介绍请看eyjian写的http://www.hadoopor.com/viewthread.php?tid=144&highlight=sequencefile
输入命令: mahout seqdirectory --input /root/input/ --output /root/input/ --charset UTF-8
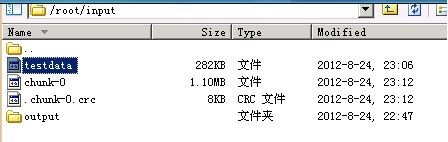
可以看到在input目录下多了2个文件, 这就是我们要的SequenceFile格式文件
把文件导入到分布式文件系统上
hadoop fs -mkdir testdata 在hadoop下建立testdata文件
hadoop fs -put /root/input/kmeans.data/ testdata testdata 把kmean.data放到HDFS上
我们可以看到:

执行使用k-means算法
输入命令:mahoutorg.apache.mahout.clustering.syntheticcontrol.kmeans.Job
出现错误:
Exception in thread "main" org.apache.hadoop.mapreduce.lib.input.InvalidInputException:Input path does not exist: file:/root/testdata
解决:
考虑可能是默认目录为root/testdata
所以cd到input文件名字改成testdata后重新运行命令:mahout org.apache.mahout.clustering.syntheticcontrol.kmeans.Job
后运行成功:
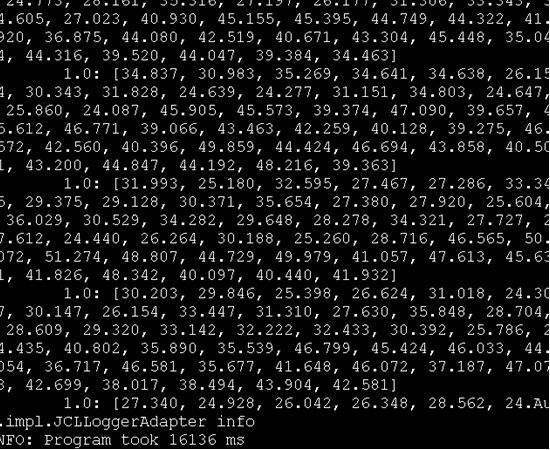
如果是在本地执行的话算法执行完之后在input目录下可以找到output,hadoop集群的话就从hdfs上面导出