USACO5.3 IDDFS_强连通_二维树状数组_斐蜀定理_矩形切割
启发式搜索
启发式搜索的主要思想是通过评价一个状态有”多好”来改进对于解的搜索.
方法#1:启发式剪枝
估价函数最简单最普通的用法是进行剪枝.假设有一个求最小代价的一个搜索,使用一个可行的估价函数.如果搜到当前状态时代价为A,这个状态的估价函数是B,那么从这个状态开始搜所能得到的最小代价是A+B.如果当前最优解是C满足C
方法#2:最佳优先搜索
最佳搜索可以看成贪心的深度优先搜索.
与一般搜索随意扩展后继节点不同,最优优先搜索按照估价函数所给的他们的”好坏”的顺序扩展节点.与只扩展最优节点的贪心不同,最佳优先搜索先扩展较”优”的后继,然后再扩展较”差”的后继.与上面的启发式剪枝组合,它可以很好地提升效率.
方法#3:A*搜索
A*搜索和”贪心”的广度优先搜索相似.
广度优先搜索总是扩展已达到的代价最小节点.但是,A*搜索,扩展最”有可能”的节点(就是说,到达1节点的代价和这个节点的估价函数之和最小)
状态被保存在优先队列中,优先级是状态的代价与估价函数之和.每一步,算法移除优先级最小的节点,将它的后继加入优先队列中.
如果估价函数可行,A*搜索到的第一个结束状态可以保证是最优的.
Milk Measuring
求一元不定方程是否有正整数解
一开始思路是求一元不定方程是否有整数解,WA一次后发现是正整数解
然后在枚举到最后完全背包过了,时间没有前面的同学快.但是思路特别简单…
第一个判断方法就是裴蜀定理被选数的gcd能被Q整除,TEST7和10用了0.1s…..-leidar
好像写出了DFSID(迭代加深搜索)的感觉…
//别人0s过的代码
void dfs(int depth, int rv, int bc)
{
if (depth == i)
{
if (rv == 0)
{
memcpy(ans, cur, i << 2);
flag = true;
}
return;
}
if (bc > n || ans[depth] < v[bc]) return; //最优性剪枝
cur[depth] = v[bc];
for (int m = 1; m * v[bc] <= rv; ++m)
dfs(depth + 1, rv - m * v[bc], bc + 1);
if (bc < n) dfs(depth, rv, bc + 1);
}window
模拟一堆矩形(窗口)的上下波动,求可见面积
有删除创造,放到顶端和低端四种操作以及对于面积的动态询问
第八次提交终于过了0.0
一开始觉得这是在模拟一个栈
但是可以放到底端(一开始以为最小化..)所以不能用STL中stack模拟
- 所以这里用一个两倍长最大值的高度数组,以及在结构体内反对应高度
然后前面四个操作就很简单了,模拟位置变化
第五个操作
一开始尝试随机数撒..真是sa…精度从来没对过还调了好久
再尝试暴力TLE(想必也是..不过想炸出数据…)
暴力的时候发现矩形给的位置不同很麻烦
//在结构体内加上sx,sy,mx,my来存四个极端位置 inline bool INRECT(DD p,int i){ int x = p.first,y = p.second; if (x < n[i].sx || x > n[i].mx) {//x >= return false; } if (y < n[i].sy || y > n[i].my) {//y >= return false; } return true; } //其实这个判断函数应该一边有等于的,但是由于后面测试函数的修改就懒得加了
看nocow上大家都说矩形切割…(WHAT’S THIS…?)最后一个小哥说了句离散化简直给予了希望
然后在创造操作里面加上了这句话来离散坐标
set<int>xpos,ypos;//set对于离散化真是神器(自动排序寻找hhh) //插入 xpos.insert(n[id].x); xpos.insert(n[id].X); ypos.insert(n[id].y); ypos.insert(n[id].Y); //找到对应位置的指针: set<int>::iterator x=xpos.find(n[id].sx); /* cout << *test.lower_bound(5) << endl; cout << *test.lower_bound(6) << endl; 找到 */ //删除 不需要删除!!!万一有重复的呢..再用离散后的坐标做
但是面积很麻烦…用bfx记录上一个x,bfy记录上一个y
距离判断真的很麻烦…一开始设了一个flag变量随着y变化是否变
WA两次后调整算法
//不过加了一点常数嘛.. //把测试函数对于矩形四条边都表示包含进去..不管它 int suc = 0; if (tt(mp(*x, *y),id) || tt(mp(((*x + bfx)>>1),*y), id) || tt(mp(*x,((*y+bfy)>>1)), id) || tt(mp(((*x + bfx)>>1), ((*y+bfy)>>1)), id)) suc = ((*y - bfy)*len); //恩 然后测试内点...(写的时候突然发现只需要测一个...//其实并没有,只是更换一下顺序能优化时间)//test学习~ #include <iostream> #include <set> using namespace std; set<int>test; void print(){ for (set<int>::iterator it = test.begin(); it != test.end(); it++) { cout << *it << " "; } cout << endl; } int main(){ for (int i =0; i < 10; i+=2) { test.insert(i); }//0 2 4 6 8 //< cout << *test.upper_bound(5) << endl;//6 cout << *test.upper_bound(6) << endl;//8 //>= cout << *test.lower_bound(5) << endl;//6 cout << *test.lower_bound(6) << endl;//8 print();//0 2 4 6 8 test.erase(1); print();//0 2 4 6 8 test.erase(2); print();//0 4 6 8 test.erase(test.find(0));//这里还用了find函数,返回指针 print();//4 6 8 cout << *test.find(0) <<" " << *test.find(8) << endl;//注意第一个是test.end() return 0; }- 别人代码的方法:
//求切割 int calc_area(int x1,int x2,int y1,int y2,int floor){ int ans=0; while ((floor<=sum_window) && ((x1>=win[floor].x2) || (x2<=win[floor].x1) || (y1>=win[floor].y2) || (y2<=win[floor].y1))) ++floor; if (floor>sum_window) {ans+=(x2-x1)*(y2-y1);return ans;} if (x1<win[floor].x1) {ans+=calc_area(x1,win[floor].x1,y1,y2,floor+1);x1=win[floor].x1;} if (x2>win[floor].x2) {ans+=calc_area(win[floor].x2,x2,y1,y2,floor+1);x2=win[floor].x2;} if (y1<win[floor].y1) {ans+=calc_area(x1,x2,y1,win[floor].y1,floor+1);y1=win[floor].y1;} if (y2>win[floor].y2) {ans+=calc_area(x1,x2,win[floor].y2,y2,floor+1);y2=win[floor].y2;} return ans; }
Network of Schools
题意: 给出一个有向图图,求两个东西
- 要给多少个节点资源才能”流”到所有节点
- 要补上多少条(有向)边才能让整个图强连通
思路(3A):
一开始思考第一个问题觉得就是并查有多少个集合
但是发现有向图后发现可能有多个入度为0的点转变成思考有多少个入度为0的点,统计输出.然后对于没有入度为0的弱连通区域记作1
第十个样例画了一个这样的图.当时就懵逼了一会
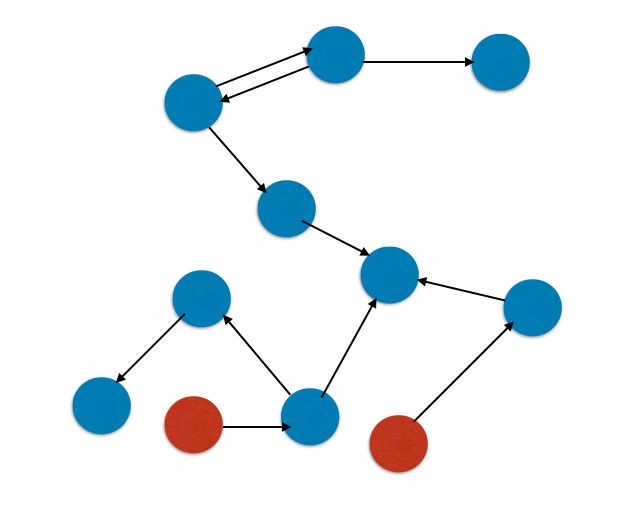
这样算红色点(入度为0)的话紫色点是遍历不到的
于是在去高数课的路上苦思冥想(因为没赶上小白XD).想起了IDDFS.
也就是说在每次测0indeg的之后,dfs一次统计每个点的DFS入度.再扫一遍看是否有入度小于实际入度,如果有的话就是上图的紫色部分(可能不止一块区域),然后再迭代加深搜索(需要多少/哪些点),算出来需要剩下的数目.
所以这里的方法也就是贪心(因为入度为0的必须要)+迭代加深
第二问还是一道图论题,一开始发现两种情况
- 有一个单独的强连通区域,那么就不需要
- 区域不止一个,那么强联通区域就可以穿插在弱联通区域的补边上
弱连通区域可以每一个”叶子”给每一个”根”相连,第三个数据挂了后发现应该是
max(inZero[i],outZero(i))然后因为不同的区域之间可以通过叶子的循环相连也就是说可以我的叶子连你的根,你的连回我的这样就不需要多补边.总结一下用了并查集来优化搜索范围,IDDFS来优化搜索深度.0S过~不过中间写到一半发现有个变量应该作为一个参数传递下(被引用的函数)去就用了一个乱七八糟名字的全局变量传了过去..毁了代码风格
正确思路(no cow)
可以把该题中所有强连通分量收缩成分别一个顶点,则入度为0的顶点就是最少要接受新软件副本的学校。
第二问就是,问至少添加多少条边,才能使原图强连通。也就问在收缩后的图至少添加多少条边,才能使之强连通。
强连通分类计算方法
用floyed算出两点间是否可以互相到达。然后枚举任意两个顶点Vi还有Vj,如果两个点互相可以到达,那么他们就是属于同一个强连通分量了。O(n3)
Kosaraju算法、Tarjan算法和Gabow算法,它们都可以在线性时间内找到图的强连通分支。
Kosaraju算法
逆后序遍历
转置得到RG
对RG依照第一步得到顺序DFS,每一颗搜索树就是一个强连通分类
void dfs(long u){ hash[u]=1; for(long i=1;i<=n;i++) if(!hash[i]&&a[u][i]) dfs(i); f[++tim]=u;//存下访问顺序 }//第一次遍历 void dfs2(long u){ hash[u]=1; big[u]=cnt; for(long i=n;i>=1;i--) if(!hash[f[i]]&&a[f[i]][u]) dfs2(f[i]); }//第二次遍历 for(long i=1;i<=n;i++) if(!hash[i])//标记数组 dfs(i); memset(hash,0,sizeof hash); for(long j=n;j>=1;j--) if(!hash[f[j]]){//用访问顺序访问 cnt++; dfs2(f[j]);//第cnt个联通区域 } for(long i=1;i<=n;i++) for(long j=1;j<=n;j++) if(a[i][j]&&big[i]!=big[j]) c[big[i]][big[j]]=true; for(long i=1;i<=cnt;i++) for(long j=1;j<=cnt;j++) if(c[i][j]){ inp[j]++;oup[i]++; }
Tarjan算法
Tarjan基于递归实现的深度优先搜索,在搜索过程中将顶点不断压入堆栈中,并在回溯时判断堆栈中顶点是否在同一联通分支。函数借助两个辅助数组pre和low,其中pre[u]为顶点u搜索的次序编号,low[u]为顶点u能回溯到的最早的顶点的次序编号。当pre[u]=low[u]时,则弹出栈中顶点并构成一个连通分支。
- 数组的初始化:当首次搜索到点p时,Dfn与Low数组的值都为到该点的时间。
- 堆栈:每搜索到一个点,将它压入栈顶。
- 当点p有与点p’相连时,如果此时(时间为dfn[p]时)p’不在栈中,p的low值为两点的low值中较小的一个。
- 当点p有与点p’相连时,如果此时(时间为dfn[p]时)p’在栈中,p的low值为p的low值和p’的dfn值中较小的一个。
- 每当搜索到一个点经过以上操作后(也就是子树已经全部遍历)的low值等于dfn值,则将它以及在它之上的元素弹出栈。这些出栈的元素组成一个强连通分量。
- 继续搜索(或许会更换搜索的起点,因为整个有向图可能分为两个不连通的部分),直到所有点被遍历。
```c++
void tarjan(int u){
LOW[u] = DFN[u] = ++step;
visit[u] = true;
slack[++top] = u;
for (int i = 1 ; i <= links[u][0] ; i++)
{
int v = links[u][i];
if (!DFN[v])
{
tarjan(v);
LOW[u] = min(LOW[u] , LOW[v]);
}
else
{
if (visit[v])
LOW[u] = min(LOW[u] , DFN[v]);
}
}
if (LOW[u] == DFN[u])
{
Cnt++;
int v;
do
{
v = slack[top--];
Belong[v] = Cnt;
visit[v] = false;
}
while (u!=v);
}
}
```
bigbarn
给个正方形撒一些点,求最大没有点的正方形..
好像以前做过..dp[LINE][ROW] = (maze[LINE][ROW] == 1)?0:MIN(dp[LINE-1][ROW-1],dp[LINE-1][ROW],dp[LINE][ROW-1])+1;
滚动数组优化
k=min(f[i-1][j],f[i][j-1]); f[i][j]=hash[i-k][j-k]?k:k+1; ans=max(ans,f[i][j]);二维树状数组+二分
二维树状数组,预先保存每个正方形的面积,然后二分边长是否符合即面积等于0 /*ID: zyz91361 LANG: C++ TASK: bigbrn */ #include <cstdio> #include <cstring> const int N = 1001; int g[N][N],s[N][N]; int row,col,n; inline int lowbit(const int &x){ return x &(-x); } int sum(int i,int j){ int tempj,sum = 0; while(i > 0){ tempj = j; while(tempj > 0){ sum += g[i][tempj]; tempj -= lowbit(tempj); } i -= lowbit(i); } return sum; } void update(int i,int j,int num){ int tempj; while(i <= row){ tempj = j; while(tempj <= col){ g[i][tempj] += num; tempj += lowbit(tempj); } i+=lowbit(i); } } int is_ok(int k){ for(int i = k; i <= n; i++) for(int j = k; j <= n; j++){ if(!g[i][j]&&(s[i][j]-s[i-k][j]-s[i][j-k]+s[i-k][j-k]==0)) return 1; } return 0; } int main(){ freopen("bigbrn.in","r",stdin); freopen("bigbrn.out","w",stdout); // memset(g,0,sizeof(g)); int T; scanf("%d%d",&n,&T); row = col = n; for(int i = 0; i < T; i++){ int u,v; scanf("%d%d",&u,&v); update(u,v,1); } for(int i = 1; i <= n; i++) for(int j = 1; j <= n; j++) s[i][j] = sum(i,j); int l = 0,r = n; int maxn = 1; while(l <= r){ int mid = (l+r)/2; if(is_ok(mid)){ l = mid+1; if(maxn < mid) maxn = mid; else break; }else r = mid-1; } printf("%d\n",maxn); }据说枚举也能过..