项目:文件压缩与解压
前段时间研究了一下哈夫曼树,也知道了其主要应用是哈夫曼编码,那么我想既然有编码那么我们是否可以利用这点来实现一个文件压缩呢?答案是可以的,而且我已经实现了,源码URL,这里我就不将代码放在下面了,下面我就说一下主要思路吧
1.统计:首先读取一个文件,统计出256个字符中各个字符出现的次数以及字符出现的总数
2.建树:按照字符出现的次数,并以次数作为权值建立哈夫曼编码树;建好树后找出各个字符的编码
3.压缩:再次读取文件,按照该字符对应的编码压缩文件
4.加工:将文件的长度,文件中各个字符以及它出现的次数写进配置文件中
5.解压:利用压缩文件和配置文件恢复出原文件
6.测试:首先观察解压的文件和原文件是否相同,再通过beyond compare软件进行对比,验证程序的正确性
步骤大概就是以上五步,但是这里包含的细节却远不止那些,其中的问题具体如下:
(1).为什么要使用配置文件呢,不使用不照样能行吗?
对于配置文件的使用,我要说明一下原因。首先我们是将字符对应的编码转化为位,在unsigned char中填充位,填满后就写入到压缩文件中。
问题1:最后一个字节是不是很有可能没有填满,我们该如何判断他是否填满以及填了几个字符的编码?
问题2:若我依次压缩一些文件,压缩完后再去解压,那么你的编码此时已经没有了,你该怎么解压呢?
上面的问题的解决方法就是通过配置文件,假如我们要压缩的文件叫做xxx,那么我们可以生成一个xxx.config的配置文件,在该配置文件中写入<文件的总长度>(恢复时知道应该应该恢复多少个字符),<char-times>(字符以及期出现的次数,用于解压时重建哈夫曼树),利用一个配置文件上述的问题就很好解决了。
(2).在文件恢复的时候需要注意哪些问题呢?
有些特殊的字符的处理需要好好注意一下,比如 '\n',我的程序中有一个函数就是读取一行字符,但是若是该字符本身就是'\n'呢,我们写入的<char-times>的char就是\n呢?那么我们就比较棘手了,对于这个问题,我们千万不能漏掉,否则就不能恢复出原来的文件。读取配置文件的时候若读到’\n‘则说明该字符就是'\n',应该继续读取它的次数。
另一个问题就是需要注意机器的存储方式,X86架构的机器的存储方式是小端存储,所以在存放的时候需要注意一下这个特性
最后解压的时候我们需要利用哈夫曼树来找到对应的编码,具体方法不好讲解清楚,我画了一个图,可以帮助理解:
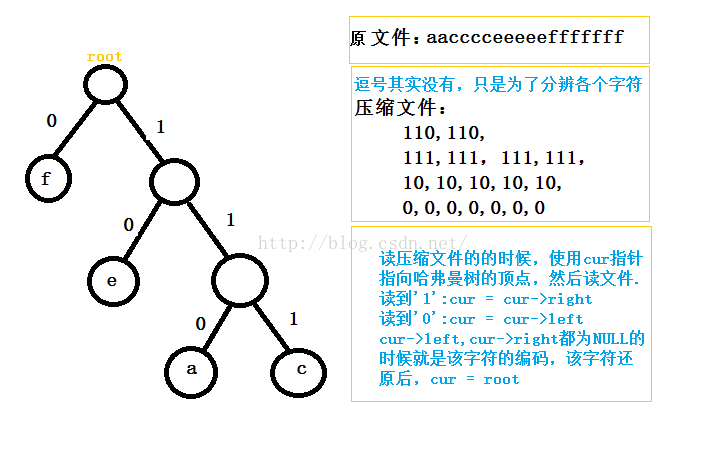
(3).其他的问题
其他的问题都是写小问题,例如我们在该项目中使用到了Heap,HuffmanTree等等,而且都是使用模板实现的,所以在模板的推演,以及模板参数等等需要注意,例如:在实现堆的时候,我们可以通过模板参数compare的行为(重载operator())决定最终建立的堆是最大堆还是最小堆。
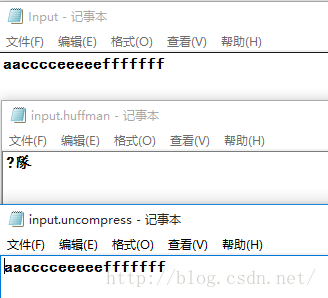
我使用了一个测试用例作为说明,原文件为“aacccceeeeefffffff”(名为 input),经过压缩(input.huffman),解压后(output.uncompress)的文件的内容如下:
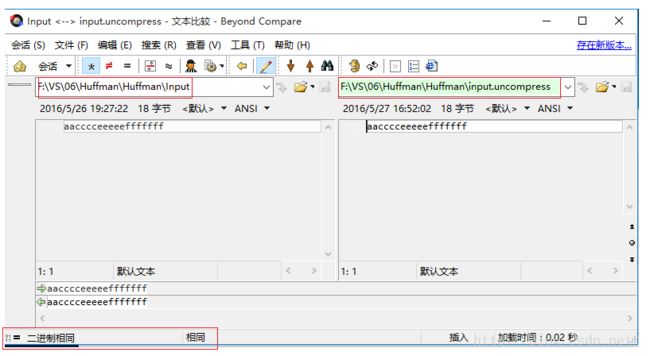
为了更进一步说明解压后的文件与原文件是相同的,我使用了beyond Compare 软件将两者进行对比,看是否相同,结果如下:
以上就是哈夫曼编码实现文件压缩与解压的过程,你可能会发现没有给出代码,其实代码我托管到 github 上去了,开始的一个超链接就是代码的url,这里再给出一下吧:https://github.com/admin-zou/FileCompress
这是一个小小的项目,跟高大尚没有关系,不过还是希望能够给大家一些帮助吧,有什么问题的话可以给我留言。