NOSQL《一》之MongoDB的理解
问题?NOSQL之MongoDB的理解
NOSQL定义:
NoSQL(Not Only SQL ),意即“不仅仅是SQL” ,指的是非关系型的数据库 。是一项全新的数据库革命性运动,早期就有人提出,发展至2009年趋势越发高涨。NoSQL的拥护者们提倡运用非关系型的数据存储,相对于铺天盖地的关系型数据库运用,这一概念无疑是一种全新的思维的注入。
关系型数据库中的表都是存储一些结构化的数据,每条记录的字段的组成都一样,即使不是每条记录都需要所有的字段,但数据库会为每条数据分配所有的字段。而非关系型数据库以键值对(key-value)存储,它的结构不固定,每一条记录可以有不一样的键,每条记录可以根据需要增加一些自己的键值对,这样就不会局限于固定的结构,可以减少一些时间和空间的开销。
优缺点比较:
在优势方面主要体现在下面几点:
简单的扩展
快速的读写
低廉的成本
灵活的数据模型
在不足方面主要有下面几点:
不提供对SQL的支持
支持的特性不够丰富
现有的产品不够成熟
一、MongoDB是什么?
MongoDB是用C++语言编写的非关系型数据库。特点是高性能、易部署、易使用,存储数据十分方便,主要特有:
(1)面向集合存储,易于存储对象类型的数据
(2)模式自由
(3)支持动态查询
(4)支持完全索引,包含内部对象
(5)支持复制和故障恢复
(6)使用高效的二进制数据存储,包括大型对象
(7)文件存储格式为BSON(一种JSON的扩展)
2.关系比较
MongoDB的单个计算机可以容纳多个独立的数据库,每一个数据库都有自己的集合和权限
MongoDB自带简洁但功能强大的JavaScriptshell,这个工具对于管理MongoDB实例和操作数据作用非常大
每一个文档都有一个特殊的键"_id",它在文档所处的集合中是唯一的,相当于关系数据库中的表的主键
二、MongoDB的应用范围
1.应用场景
◆网站数据:Mongo非常适合实时的插入,更新与查询,并具备网站实时数据存储所需的复制及高度伸缩性。
◆缓存:由于性能很高,Mongo也适合作为信息基础设施的缓存层。在系统重启之后,由Mongo搭建的持久化缓存层可以避免下层的数据源过载。
◆大尺寸,低价值的数据:使用传统的关系型数据库存储一些数据时可能会比较昂贵,在此之前,很多时候程序员往往会选择传统的文件进行存储。
◆高伸缩性的场景:Mongo非常适合由数十或数百台服务器组成的数据库。Mongo的路线图中已经包含对MapReduce引擎的内置支持。
◆用于对象及JSON数据的存储:Mongo的BSON数据格式非常适合文档化格式的存储及查询。
2.不适合的场景
◆高度事务性的系统:例如银行或会计系统。传统的关系型数据库目前还是更适用于需要大量原子性复杂事务的应用程序。
◆传统的商业智能应用:针对特定问题的BI数据库会对产生高度优化的查询方式。对于此类应用,数据仓库可能是更合适的选择。
◆需要SQL的问题
三、搭建MongoDB环境
1.MongoDB安装
官网下载:点击打开链接,下载:mongodb-win32-x86_64-2.4.3.zip
MongoDB的安装非常简单,只需要将下载的MongoDB的压缩文件解压到任意目录,并将其中的bin目录加入到系统的path环境变量中即可。
在启动MongoDB之前,要手动创建一个存放MongoDB数据文件的目录,如F:\mongodbFile
因为要使用mongodb目录下bin的各种命令,所以需要配置环境变量,在path下将
G:\其他、\SpringMvc+MyBatis\day75_mongodb\资料\nosql\mongodb-win32-x86_64-2.4.3\bin
将命令路径配置到Path下进去。
然后在准备一个文件夹,用来存放数据库存放。
使用mongodb的一个命令mongod,存放数据库
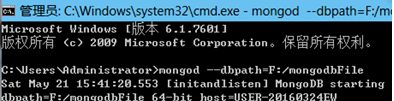
浏览器测试:http://localhost:27017/,出现这个,表示mongodb安装成功

环境就搭建成功了。
2.mongoDB安装到系统服务中去
在解压的Mongo文件目录下,新建一个logs文件夹,打开cmd,输入以下命令:
打开services.exe看到你系统服务中出来名叫MongoDB了没?

注意:一定要重启,不然不成功开启,
如果不将这个服务加入系统服务中,那么每次都需要开启链接Mongodb,
注意这个时候我们要链接mongodb了,这个cmd不要关,要操作数据库另外起一个cmd命令链接服务
3.数据库操作
如果没有将服务加入系统服务中,先链接mongodb,在开启另外一个cmd,否则起一个cmd命令链接服务。
mongo命令连接到MongoDB服务器,如下,输入mongo命令默认连接到本地的名称为test的数据库,如果希望连接到远程数据库,可以使用mongo ip:port
删除数据库
4.集合操作
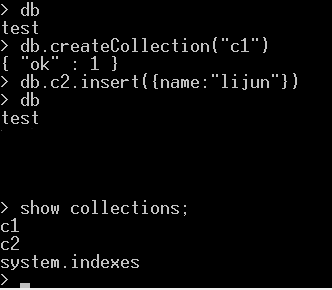
db.collectionName.drop()是用来从数据库中删除一个集合
5.文档的操作(增删改查)
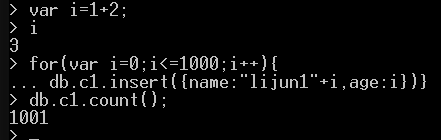
前面提过mongodb是支持js的,而且可以速度很快的创建了很多集合。
删除集合中的文档,使用命令 db.集合名称.remove({删除条件}),不加删除条件为删除集合中的所有文档,例如:db.c1.remove() 为删除c1集合中的所有文档,db.c1.remove({name:”user1”})为删除c1集合中name为user1的文档

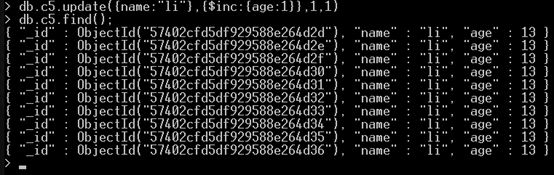
最麻烦的就是更新,更新一条,但是不能更新单个文档
共有四个参数:条件,更新列,**,含有多个文档,是否同时更新1(默认是不更新0,)
第三个参数,看如下:当不存在这个条件的时候,设置1的时候,自动新建一个文档,当为0的时候,不执行操作。

自增,自减$inc
查询文档:db.集合名词.find({条件},{文档key:1 or 0});

大于10的数据
![]()
小于10的
![]()
小于等于10
大于等于10
条件统计

从15开始后面5条数据

排序1为升序,-1为降序
db.customer.count();
db.customer.find().count();
db.customer.find({age:{$lt:5}}).count();
db.customer.find().sort({age:1}); 降序-1
db.customer.find().skip(2).limit(3);
db.customer.find().sort({age:-1}).skip(2).limit(3);
db.customer.find().sort({age:-1}).skip(2).limit(3).count();
db.customer.find().sort({age:-1}).skip(2).limit(3).count(0);
db.customer.find().sort({age:-1}).skip(2).limit(3).count(1);
插入异类的json数据

查询包含1.2.3的数据—相应的nall就是取没有在这些结果里的数据
$all主要用来查询数组中的包含关系,查询条件中只要有一个不包含就不返回
查询在结果1.2.3中的数据—相应的nin就是取没有在这些结果里的数据
或运算
![]()
异或运算
![]()
存在着age列的显示出来
Var I = db.c1.find();
hasNext();//是否有值
next();//取值
6.普通索引
索引就是用来加速查询的。数据库索引与书籍的索引类似:有了索引就不需要翻遍整本书,数据库则可以直接在索引中查找,使得查找速度能提高几个数量级。在索引中找到条目以后,就可以直接跳转到目标文档的位置。
普通索引语法:
db.collectionName.ensureIndex({key:1})
首先,在普通的集合当中是以"_id"作为索引的(默认)

我们在集合当中建立五百万条文档,然后进行索引看看花费多少时间:
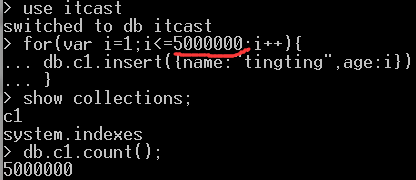
索引250万那条文档查看相关时间:使用explain()方法,我们可以看到花费了2秒,也许你这个时候会想区区2秒,不多啊,但是当数据量达到P的时候,那就不一样了。可能会花费几小时都有可能。

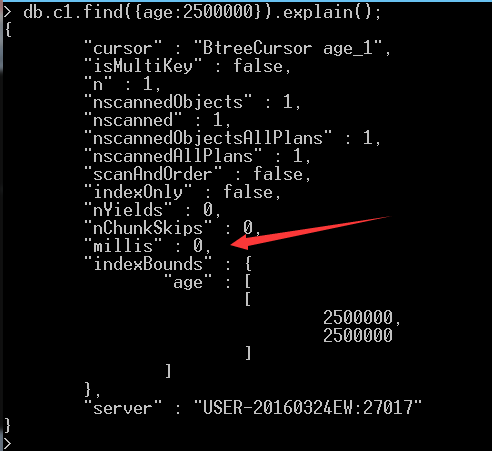
好,我们在age上建立普通索引,然后再来对age进行索引:发现时间很快,都基本为零(相当于建立了书籍的目录,直接在目录上找,肯定快啊!)《普通索引的建立》
普通索引语法:
db.collectionName.ensureIndex({key:1})
这个时候在看看索引项:发现有两个索引,再看看索引一样的250万那条数据,很明显跟先前默认的索引相比,明显速度提高了,几乎速度为0.
7.唯一索引


再看看唯一索引:

不管是普通索引还是唯一索引,它都相当于建立了一个索引目录(比如书的目录),然后和文档条目相关联,查找的时候,直接就找索引目录,就可以找到文档条目。(查看书目录的时候,就可以找到书的页数)
8.固定集合
固定集合指的是事先创建而且大小固定的集合。
固定集合特性:固定集合很像环形队列,如果空间不足,最早的文档就会被删除,为新的文档腾出空间。一般来说,固定集合适用于任何想要自动淘汰过期属性的场景,没有太多的操作限制。
创建固定集合使用命令:
db.createCollection(“collectionName”,{capped:true,size:100000,max:100});
size指定集合大小,单位为KB,max指定文档的数量
当指定文档数量上限时,必须同时指定大小。淘汰机制只有在容量还没有满时才会依据文档数量来工作。要是容量满了,淘汰机制会依据容量来工作。
Capped:表示创建固定集合,Size表示大小,max表示文档数,创建c2集合

9.备份及备份还原
一定要返回到cmd界面进行备份:以下是备份命令:

删除了数据库后,用以下命令即可还原备份:
10.导入导出
导出
导出为txt格式,当然也可以为xls格式或者其他的。
Txt格式:
Xls格式:

参数说明:
-h 数据库地址
-d 指明使用的库
-c 指明要导入的集合


11.数据库安全及权限
每个MongoDB实例中的数据库都可以有许多用户。如果开启了安全性检查,则只有数据库认证用户才能执行读或者写操作。在认证的上下文中,MongoDB会将普通的数据作为admin数据库处理。admin数据库中的用户被视为超级用户(即管理员)。在认证之后,管理员可以读写所有数据库,执行特定的管理命令,如listDatabases和shutdown。
在开启安全检查之前,一定要至少有一个管理员账号.
db.help();
添加用户
为itcast分配两个用户(其中一个只读)
登录这个用户成功:
四、MongoDB的总结