R-CNN论文笔记《Rich feature hierarchical for accurate object detection and semantic segmentation》
近期由于毕设需求,开始涉及深度学习方向,由于基础为零,故一切都只好从论文开始看起。写下论文笔记,就当作是对自己的鼓励吧。以下出现的序号都是原论文的序号。
Abstract
物体检测的性能表现,在本文出现之前,已经沉寂了多年。以前的方法基本都是使用多重的低层次图像特征和高层次的文本环境。在本文中,最主要有两大亮点:①把大容量的卷积神经网络应用到从底向上的区域建议框(Region Proposal 实在不知道该怎么翻译这个单词)中来定位物体②当标记的训练数据比较少时,可以先在一个辅助的数据集上进行监督预训练(supervised pre-training),然后在进行一次特定区域的微调(domain-specific fine-tuning)
1.Introduction
首先介绍了一些背景知识,这里不再赘述。这篇文章的思想就是利用图片分类的原理来做物体检测,为了完成这个任务,需要处理两大问题:
一、如何使用深度网络来定位物体?
传统的方式是使用滑动窗口检测器(Sliding-windows detector)来做,但是如果在深度网络中这样使用的话,神经单元会过多,使得比较有挑战性。取而代之的是,我们采用“recognition using Regions”的策略,对每一张输入图片都提取出2000个类别独立的区域建议框,然后再使用CNN对每一个Region Proposal 提取固定长度的特征向量。
二、如何用有限的标记数据来训练一个比较大的网络?
另外一个挑战就是当前可用的标记数据对于训练一个大的神经网是不够用的。传统的方式是先来一个非监督预训练,再加上监督微调(unsupervised pre-training + supervised fine-tuning)。本文则采取的方式是先在一个辅助的数据集(ILSVRC)上进行监督预训练(supervised pre-training),然后再在小的数据集(PASCAL)上进行指定区域的微调(Domain-specific fine-tuning)。
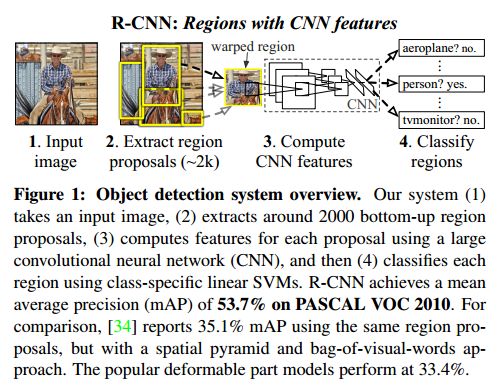
可以看到,整体结构如上所示,比较简单
- 用selective search代替传统的滑动窗口,提取出2k个候选region proposal
- 对于每个region,用摘掉了最后一层softmax层的AlexNet来提取特征
- 训练出来K个L-SVM作为分类器,使用AlexNet提取出来的特征作为输出,得到每个region属于某一类的得分
- 最后对每个类别用NMS来舍弃掉一部分region,得到detection的结果
2.Object detection with R-CNN
2.1 Module design
主要分三大模块
①Region Proposal模块:使用Selective Search方法对每一个输入图片提取出2000个Region Proposals
②Feature Extraction模块:利用Caffe实现的AlexNet对每一个Region Proposal提取出一个4096-D的特征向量。注意在提取之前,都要将每一个Region中的图片强制缩放到227*227 size,本文中不管该区域的大小和分辨率,而且最后还在外面加了一个16 piexl的边框(p=16)
③第三个就是一组线性的SVM分类器,来获得每个region属于某一类别的得分
2.2 Test-time detection
没什么特别重要的东西
2.3 Training
Supervised pre-training:使用ILSVRC 2012的数据训练一个模型,效果比AlexNet略差2.2%
Domain-specific fine-tuning:将上面训练出来的模型用到new task(dection)和new domain(warped region proposals)上,作者将最后一个softmax从1000路输出替换成了N+1路输出(N个类别+1背景)。然后将IoU大于50%的region当成正样本,否则是负样本。将fine-tuning学习率设置成pre-train模型中的1/10(目的是为了既能学到新东西但是不会完全否定旧的东西)。batch为128,其中正负样本比例是1:3。
Object category classifiters:选择SVM对每一类都做一个二分类,在选择样本的时候,区分正负样本的IoU取多少很重要,取IoU=0.5时候,mAP下降5%,取IoU=0,mAP下降4%,作者最后取了0.3
3.Visualization,ablation,and modes of error
3.1 Visualizaing learned features
3.2 Ablation studies
3.4 Bounding box Regression
最后,作者有对Region proposal做了一次回归来进一步定位物体,使整体结果提高3-4个百分点。
为何要做一次bounding box regression,个人认为是为了修订bounding box的位置,前面已经提到过,在对region 进行强制变换的时候,加了一个16piexl的padding,同时也是为了得到该区域在原图中的位置,因为以后的输出都是在原图中输出检测框。下面是知乎网友“魏晋”的回答,我觉得也挺恰当的
<如果把boundingbox回归单独拆出来看,这个回归的输入是图像局部region的CNN feature,这个region既可能正好包含一个完整的object(比如人),也有可能只包含object的一部分(比如人的上半身)。如果是第一种情况,这个region可以有很高的置信度,而且给出的boundingbox也很准确。但如果是第二种情况,这个region的置信度可能也很高,但是按照region本身的范围给出的boundingbox的话就不准确了,这时候需要根据局部的feature来调整boundingbox,这个调整的过程就是boundingbox回归。
如果类比人类视觉,可以看作由局部推断整体范围。更具体的例子是,你有一张全身照,但是下半身被染上污渍,完全模糊看不清了,但是如果让一个人来画一个关于照片上人的boundingbox的话,那么这个人不会只画上半身,而是会自己做推断,把模糊的下半身也画进来。>