Lua源代码阅读(五)数据栈与调用栈组成的 线程(协程)
3: C 语言本身并不支持协程或延续点,一旦中断 lua 协程,就面临 C 语言中调用栈如何处理的难题。
4: 直接操作 C 层面的堆栈,可以较为容易的作到协程的切换。但这样做,会和硬件平台绑定。这是一个在 C 中实现延续点的不错的方法。但这个做法不符合 lua的设计原则。lua为了解决这个问题,对 lua语言的 实现以及和 C 交互的接口设计上做了大量的努力。最终使用标准的 C 语言,实现了完整功能的 lua协程。
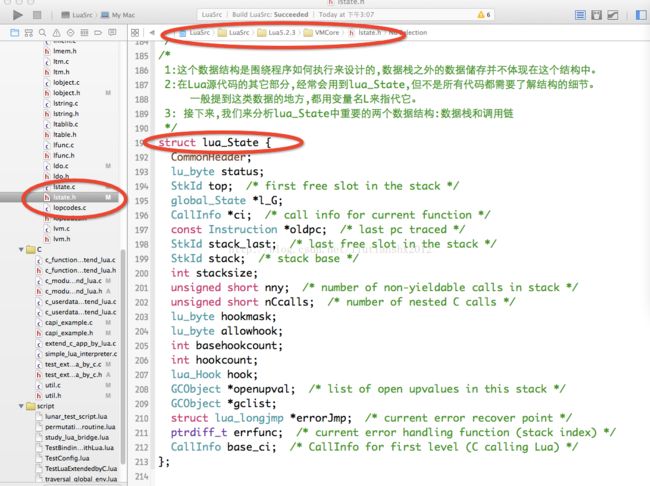
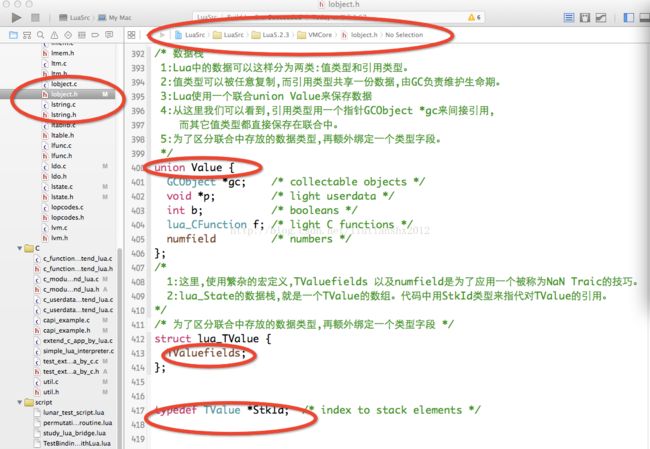
5: 刚接触 lua时,从 C 层面看待 lua,lua的虚拟机对象就是一个 lua_State 。但实际上,真正的 lua虚拟机对象被隐藏起来了。那就是lstate.h中定义的结构体 global_State 。
lua_State 是暴露给用户的数据类型。从名字上看,它想表示一个 lua程序的执行状态,在官方文档中, 它指代 lua的一个线程。每个线程拥有独立的数据栈以及函数调用链,还有独立的调试钩子和错误处理设 施。所以我们不应当简单的把 lua_State 看成一个静态的数据集,它是一组 lua程序的执行状态机。所有的 luaC API 都是围绕这个状态机,改变其状态的:或把数据压入堆栈,或取出,或执行栈顶的函数,或继续 上次被中断的执行过程。
同一 lua虚拟机中的所有执行线程,共享了一块全局数据 global_State 。在 lua的实现代码中,需要访 问这个结构体的时候,会调用宏
忽略lstate.h中涉及GC 的复杂部分,我们可以先看一眼 lua_State 的数据结构。
/* Lua数据栈的初始化
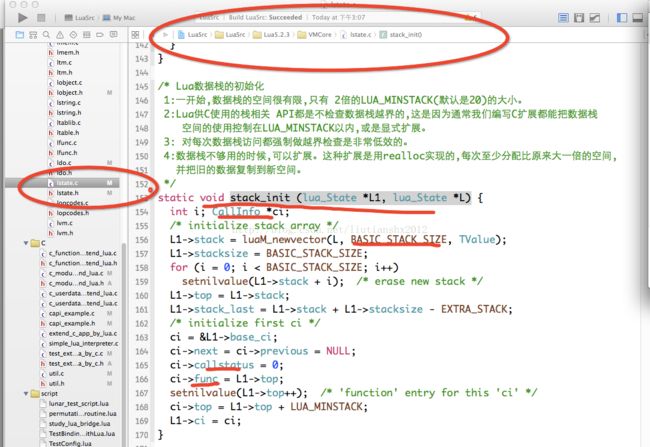
1:一开始,数据栈的空间很有限,只有 2倍的LUA_MINSTACK(默认是20)的大小。
2:Lua供C使用的栈相关 API都是不检查数据栈越界的,这是因为通常我们编写C扩展都能把数据栈
空间的使用控制在LUA_MINSTACK以内,或是显式扩展。
3: 对每次数据栈访问都强制做越界检查是非常低效的。
4:数据栈不够用的时候,可以扩展。这种扩展是用realloc实现的,每次至少分配比原来大一倍的空间,
并把旧的数据复制到新空间。
*/
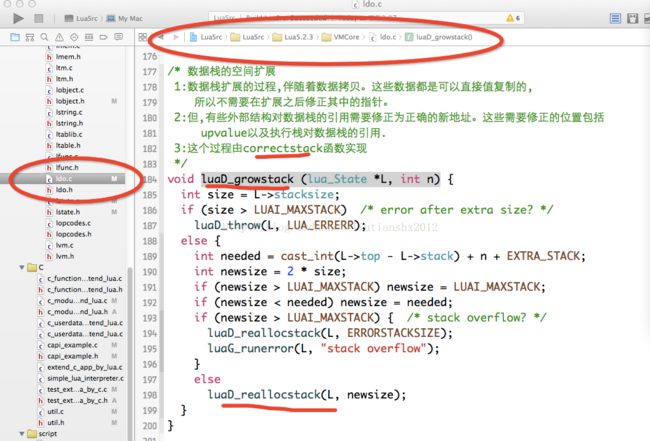
/* 数据栈的空间扩展
1:数据栈扩展的过程,伴随着数据拷贝。这些数据都是可以直接值复制的,
所以不需要在扩展之后修正其中的指针。
2:但,有些外部结构对数据栈的引用需要修正为正确的新地址。这些需要修正的位置包括
upvalue以及执行栈对数据栈的引用.
3:这个过程由correctstack函数实现
*/
Lua调用栈
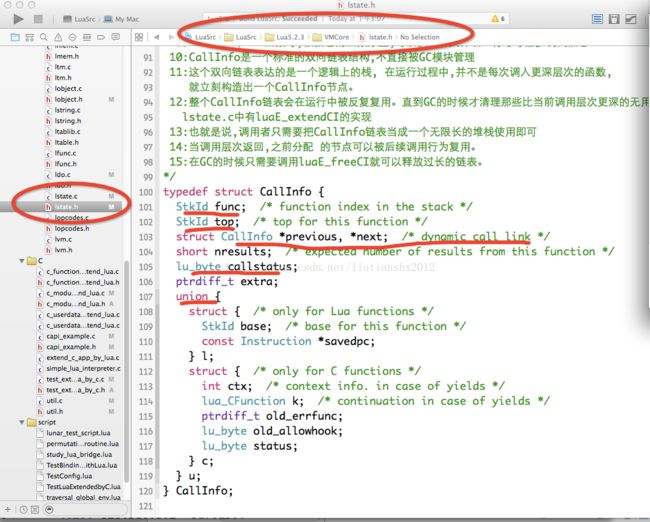
/*Lua调用栈
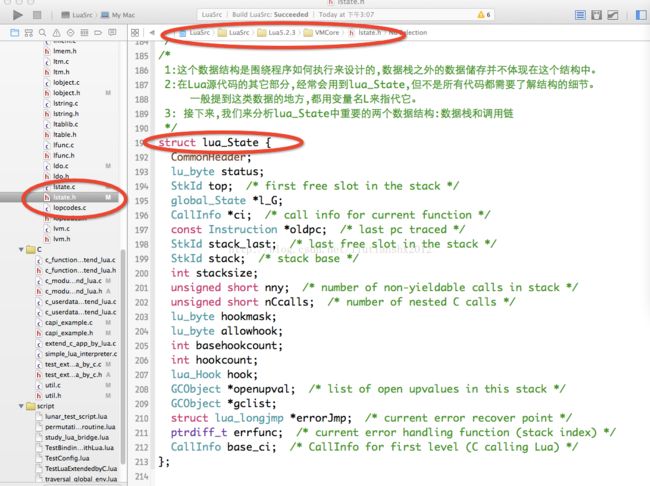
1:Lua把调用栈和数据栈分开保存。
2:调用栈放在一个叫做CallInfo的结构中,以双向链表的形式储存在线程对象里。
3:CallInfo 保存着正在调用的函数的运行状态;状态标示存放在lu_byte callstatus中。
4:部分数据和函数的类型有关,以联合形式存放
5:C 函数与 Lua函数的结构不完全相同
6:callstatus中保存了一位标志用来区分是C函数还是Lua函数
7:正在调用的函数一定存在于数据栈上,在CallInfo结构中,func指向正在执行的函数在数据栈上的位置
需要记录这个信息,是因为如果当前是一个Lua函数,且传入的参数个数不定的时候,需要用这个位置和当
前数据栈底的位置相减,获得不定参数的准确数量
8:同时,func还可以帮助我们调试嵌入式Lua代码:在用 GDB这样的调试器调试代码时,可以方便的查看C中
的调用栈信息,但一旦嵌入Lua ,我们很难理解运行过程中的Lua代码的调用栈;不理解Lua的内部结构,
就可能面对一个简单的lua_State变量束手无策.
9:实际上,遍历L中的Ci域指向的CallInfo链表可以获得完整的Lua调用链;
而每一级的CallInfo中,都可以进一步的通过 func域取得所在函数的更详细信息。
当func为一个Lua函数时,根据它的函数原型,可以获得源文件名、行号等诸多调试信息。
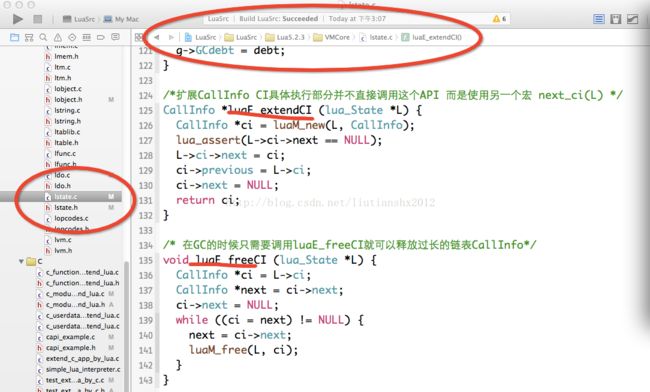
10:CallInfo是一个标准的双向链表结构,不直接被GC模块管理
11:这个双向链表表达的是一个逻辑上的栈, 在运行过程中,并不是每次调入更深层次的函数,
就立刻构造出一个CallInfo节点。
12:整个CallInfo链表会在运行中被反复复用。直到GC的时候才清理那些比当前调用层次更深的无用节点。
lstate.c中有luaE_extendCI的实现
13:也就是说,调用者只需要把CallInfo链表当成一个无限长的堆栈使用即可
14:当调用层次返回,之前分配的节点可以被后续调用行为复用。
15:在GC的时候只需要调用luaE_freeCI就可以释放过长的链表。
*/
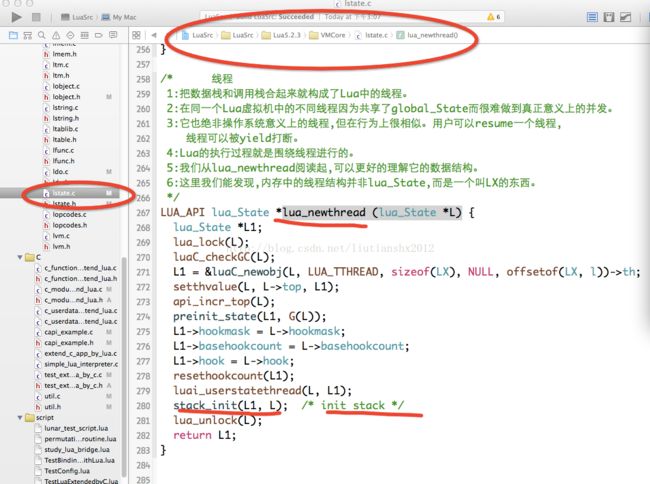
/* 线程
1:把数据栈和调用栈合起来就构成了Lua中的线程。
2:在同一个Lua虚拟机中的不同线程因为共享了global_State而很难做到真正意义上的并发。
3:它也绝非操作系统意义上的线程,但在行为上很相似。用户可以resume一个线程,
线程可以被yield打断。
4:Lua的执行过程就是围绕线程进行的。
5:我们从lua_newthread阅读起,可以更好的理解它的数据结构。
6:这里我们能发现,内存中的线程结构并非lua_State,而是一个叫LX的东西。
*/
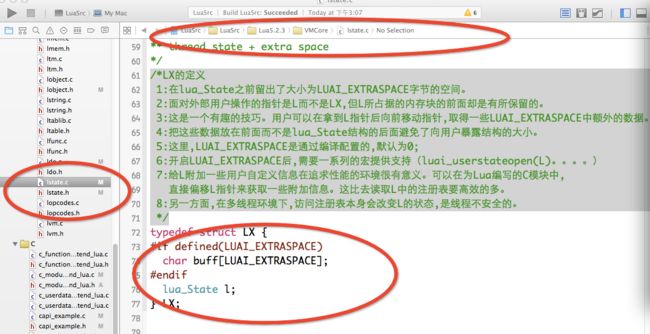
/*LX的定义
1:在lua_State之前留出了大小为LUAI_EXTRASPACE字节的空间。
2:面对外部用户操作的指针是L而不是LX,但L所占据的内存块的前面却是有所保留的。
3:这是一个有趣的技巧。用户可以在拿到L指针后向前移动指针,取得一些LUAI_EXTRASPACE中额外的数据。
4:把这些数据放在前面而不是lua_State结构的后面避免了向用户暴露结构的大小。
5:这里,LUAI_EXTRASPACE是通过编译配置的,默认为0;
6:开启LUAI_EXTRASPACE后,需要一系列的宏提供支持(luai_userstateopen(L)。。。。)
7:给L附加一些用户自定义信息在追求性能的环境很有意义。可以在为Lua编写的C模块中,
直接偏移L指针来获取一些附加信息。这比去读取L中的注册表要高效的多。
8:另一方面,在多线程环境下,访问注册表本身会改变L的状态,是线程不安全的。
*/