电商大促特辑:蘑菇街致美丽新世界的架构礼
6月15日,蘑菇街、美丽说、淘世界正式对外宣布合并消息,新合并的“美丽联合集团”将成为国内新晋的独角兽。现在让我们聚焦它的前身之一蘑菇街,看看蘑菇街创业5年转型3次,经历社区、导购、电商、社交+电商的历程中背后不凡的架构成长故事吧。
2016年7月15-16日,ArchSummit全球架构师峰会将在深圳举行。本届大会,我们邀请了蘑菇街技术经理苏武,前来分享《蘑菇街背后系统的稳定性保障实践》的内容,讲述的是蘑菇街对电商稳定性保障玩法的探索以及对稳定性系统的实践过程。
现在我们就来采访苏武老师,看看蘑菇街经历多年多次转型后的技术沉淀与经验吧!
受访嘉宾介绍:
苏武,蘑菇街工程师,12年加入蘑菇街,经历过这几年蘑菇街系统的改造升级,负责了14、15年双十一稳定性保障工作,目前主要负责全站稳定性工作。
InfoQ: 您目前负责蘑菇街的全站稳定性工作,能否详细介绍一下你们这个团队承担的具体工作?
苏武:稳定性的工作其实每个团队都在做,有些是流程上的,有些是系统上的,有些还是人肉去处理,有些是工具去处理的。我们团队做的事情是一些共性的事情,通过技术实现一些工具和服务平台给全部研发人员使用来促进全站的稳定性工作。
举些例子,我们开发了一个限流降级的系统,统一了接入层、Web层、服务层的限流降级,可以在统一的后台编辑限流配置,进行配置推送。这样的好处是统一管控,并且其他团队也不用重复去建设。
另外根据Google Dapper的论文我们实现了自己的全链路跟踪系统,这个系统可以将用户的一个请求所进过的所有系统都追踪到。当出现问题的时候,这个系统可以给你指出是哪一个点出现了问题,问题的影响面大小。在这个之前我们只能通过监控和统计看到点上的问题,这之后就能看到线和面上的问题。在全链路跟踪的基础上我们实现了全链路的压测,全链路压测解决了我们之前压测不准确的问题,特别是大促的压测,它可以自定义压测的链路和场景,可以自定义压测数据和业务模型。
InfoQ: 您于2012年加入蘑菇街,从最初“运维和基础架构也只是听说过”,到如今负责全站稳定性,可以说是一步步从底层做起,能否谈谈这些年的工作历程及心路历程?
苏武:在蘑菇街我有过DBA、图片CDN相关的运维经验,做过日志相关和数据平台,也写过失败的中间件产品,慢慢地对全站有了一些了解,就帮忙一起解决一些全局性质的问题,后面就开始负责全站的稳定性工作。
看我的经历会发现横向的事情还比较多,也非常幸运在公司高速发展的过程中参与其中,经历了一些技术演进和发展,我也获得了自己的技术成长和软技能成长。之前只要做好自己的一块就可以了,到后面往往需要从全局上考虑,努力权衡各个方面,给出当下最合适的方案。
另外我的内心是挺焦虑的,工作里面有很多横向的事情,就要求我对技术广度要高,也因为横向的事情,感觉在技术深度上的积累还不够,在技术上我还想更进一步,这块我既兴奋也焦虑。
InfoQ: 蘑菇街作为专注于时尚女性的电商网站,而创始人都是清一色的理工男,如何深度挖掘用户心理,保持高用户粘度,制定精确的业务目标?这背后有什么样的技术支撑,或者做了哪些不一样的工作?
苏武: 这个问题很大,对于业务上怎么去做我不是很了解。从系统上看,我们也会做机器学习、数据挖掘和推荐等事情,这一块我不是很熟悉,不过他们的上游我可以说一说:
日志收集:
在不涉及用户隐私的情况下我们会收集一些日志,比如点击日志(在某个页面,某个位置点击了某个商品)。这一块我们使用了Kafka作为日志收集的中转站,每台机器上部署有logAgent,logAgent会根据配置信息拉取相应的日志,然后发送到Kafka里面,Kafka作为下游系统如数据平台、推荐系统等的日志源头,logAgent是自研的,有一些特性:
- 收集的日志文件名是可配置的,配置放在Zookeeper上面(和Kafka日志共用Zookeeper集群),Web后台设置哪些文件名要收集,推送到ZooKeeper,logAgent可以监听到改动。
- logAgent定时将自己收集的文件的offset上报给Zookeeper,当logAgent重启时可以从Zookeeper获取offset,做到日志不重和不丢。
- 满足一些小的特性:如对日志文件滚动,日志文件名更改的支持。
Kafka集群目前大约几十台机器的规模,Kafka还是比较稳定的,最近在看Kafka集群间的跨机房数据同步怎么做 。
数据库:
还有一些数据来自于数据库,我们实现了一个数据变更分发平台:基于MySQL的Binlog解析,将解析完的数据入到MQ,这样有需求的应用可以订阅MQ进行消费。 至于后面的数据平台和实时计算等是用的开源的系统,例如Hadoop ,Hive, Presto, Spark, Storm等。
InfoQ: 据了解,去年双11蘑菇街大量压力来自移动端,能否介绍移动端压力的特点?来自移动端与来自PC的压力在优化方案或处理方式有何区别,分别如何进行?
苏武:说一下我们在移动端发现的一些现象以及一些做法:
BGP网络
移动端有很大一部分是3G、4G的网络,并且很多是移动用户。网络层面你会发现如果你有BGP网络,对移动线路支持会好一些;如果没有BGP或者没有移动线路,有一部分用户的体验就不会很好。域名劫持
这个在app和pc端都会存在,但在app端可以做一些应对:比如使用HTTPDNS,直接给app提供IP列表,通过IP直接访问图片这一块,可以在不同的网络情况下给予不同质量和格式的图片(如Webp),不同的屏幕尺寸可以用不同分辨率的图片。接入层
对于后端来说,移动端可以认为是很纯粹的前后端分离后的前端。我们在app和后端之间做了一层接入层,从而使得app和接入层交互而不用管后端是怎么变化的。这个对于app端的意义很大,比如想把HTTP协议去掉,直接使用TCP,那么只需要app和接入层的改造,同时不管后端怎么改造,只需要保持接入层的接口向前兼容就可以。同时接入层也会做很多事情,比如路由转发、实时的配置下发、安全控制、限流、防刷和应用权限等。
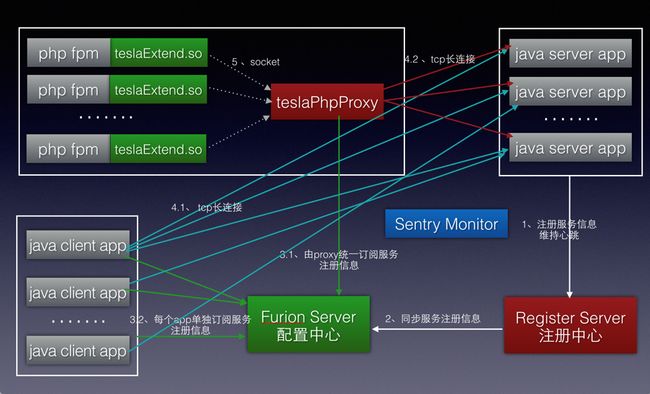
InfoQ: 蘑菇街在服务层分布式上使用了自研的Tesla ,为什么取名为Tesla?在DB分布式问题上使用了分布式数据库中间件,请详细介绍一下它们的具体应用?
苏武: 给应用、类或方法起名字在工程师界堪称一大难题。起Tesla是为了纪念Nikola Tesla。分布式数据库中间件的名字叫Raptor,Raptor是一辆车,觉得数据库中间层要做的稳定耐操。Tesla 架构图如下:
Tesla有如下优点:
支持多语言:目前支持PHP和Java,C++的支持正在开发当中。PHP的方案里面有一个proxy,这个proxy和PHP是同机部署的,proxy的作用是收拢连接数,一个机器上的proxy对某个服务只会建立一个长连接。我们在使用PHP的时候遇到过Redis和MySQL端来自于PHP的连接数过多的问题,这一点需要特别注意。
异步调用支持:client端支持异步调用,server端支持调用结果异步返回。
支持多机房部署与跨机房调用,支持限流,支持全链路压测中压测标志的透传。
Raptor是一个基于Java语言、实现了标准JDBC协议的DataSource,主要的特性有:
数据源管理:最上层是逻辑数据源层,面向业务,管理着数据拆分层;中间是组数据源层,面向单个数据分片,管理着主从数据源集群;最下层是原子数据源层,面向主从结构,管理着物理上的数据源信息。三层结构的好处去可以根据业务的需要,使用其中的任何一层;同时在Raptor开发的时候,各种功能也可以比较明确的落到这其中的一层。
分库分表(水平拆分):这个过程包括SQL解析和约束、SQL路由和改写、SQL分发执行、结果合并与重新处理。
安全性,基于sql解析和拦截:提供防SQL注入、非规范SQL拦截、SQL异常报警、慢SQL、慢事务报告等SQL安全性功能。同时应用数据源配置不再本地配置用户名密码,是通过配置中心获取加密的数据源配置。
基于配置中心:在数据源出现故障后,可以很快地通过配置中心来统一下发新的数据源配置,提高故障处理效率。
InfoQ: 经过了前两年两次双11,蘑菇街系统架构和稳定保障拥有了怎样的经验与教训?今年年中大促做了哪些准备?现在的架构体系是否有不一样的调整和优化?
苏武: 说起大促问题,那是非常多的:我们有过慢SQL导致出现问题;有过设计上的问题导致MySQL行级锁竞争,导致系统并发能力下降;也有过架构风险梳理失误,导致数据库双写,把数据库打挂的经历。所以后面我们也重新梳理了下应该怎么去做稳定性的保障,目前我们已经有了一套比较成熟的方法论,然后也在做一些工具和系统去替代之前人肉做的一些事情。
在架构系统上,我们将大部分的系统迁移到了Java技术体系下面,之前我们是在PHP上面的。迁移原因是PHP资深的人不好找,感觉这样下去hold不住。Java这一块的人会比较多,社区活跃,很多体量大的公司遇到的问题的解决方案在网络上也能找到。
今年年中大促做的准备有:
架构梳理:所有人一起梳理当前架构的风险是什么,这个梳理的结果将会指导后面去做什么,同时会将结果进行分类:有一类风险是可以通过系统改造消除的,这种去评估改造的时间点和风险,如果不行则会寻求另外的解决方案或者整理处理问题的预案;还有一类风险是短时间内改变不了的,这种重点整理处理问题的预案,如果真的出问题,要求在短时间内去恢复。
系统容量评估:根据业务的目标以及业务的模型和玩法,将业务的数据映射到系统上面,将会得系统链路层面的容量目标。比如1秒钟需要支持多少下单,根据这个目标再分解到一个个相关依赖的系统需要准备多少容量。
全链路压测:用的是线上的真实环境,通过隔离压测数据和线上数据做到数据不污染,但是其他的环境和资源都是一样的,这样压测出来的数据会比较准确。
依赖关系梳理:讲过前面的压测后,会发现有些系统服务能力有问题,不能达到你想要的目标,去改造的话时间不够,加资源又解决不了问题,这种比较头疼。这里我们就做了一个事情,就是去梳理各类系统的依赖关系,将不能提供有损服务的系统定义为强依赖,反之为弱依赖。弱依赖如果有服务能力问题那么可以通过开关、降级等手段摘掉,对这些弱依赖我们植入开关和降级代码,在关键时刻可以启用。
限流:在用户请求入口,我们也做了限流方案,包括QPS限流和根据后端服务反馈的监控数据做的动态限流。限流主要是为了防止流量超出评估的容量,将系统打死。
InfoQ: 您曾说过:“架构没有完美,只求在时间、资源、需求三者之间有比较好的平衡”,对于刚入门或者有志于从事这项事业的架构师们,您如何跟他们分享您的感悟和经验?
苏武:我是事情驱动着我走过来的,有这么个机会让我去实践,我觉得从两个方面入手:
一方面:自己平时可以多关注和学习技术,做好准备。
另一方面: 有机会的话一定要去尝试实践,方案有可能被毙掉,方案有可能不能落地,但是这个过程能学习到很多。
InfoQ:感谢苏武老师接受我们的采访。期待您在ArchSummit全球架构师峰会上的分享。
感谢陈兴璐对本文的审校。
给InfoQ中文站投稿或者参与内容翻译工作,请邮件至[email protected]。也欢迎大家通过新浪微博(@InfoQ,@丁晓昀),微信(微信号:InfoQChina)关注我们。