共享一例 硬解析过多引起的系统挂起
现象:
客户做应用程序升级后,数据库服务器CPU攀升到100%,数据库挂起。重启数据库,两小时后,再次攀升到100%,数据库再次挂起。
分析:
1)查看系统近期的TOP5等待事件
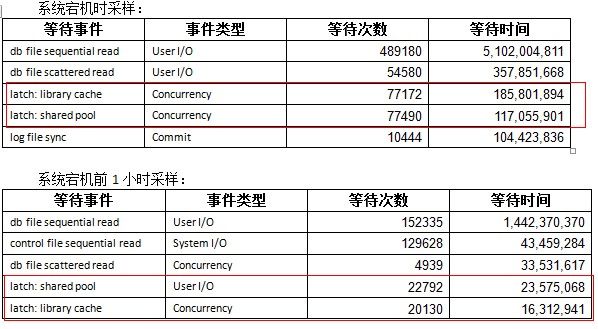
可以看到,latch: library cache及latch: shared pool进了等待事件TOP5。我们知道过多latch的争用,会引起系统CPU攀升。结合客户数据库CPU2小时内缓慢攀升到100%的特点,初步考虑,是由于过多硬解析引起。
小贴士:硬解析为什么会引起高CPU占用
数据库解析SQL语句流程:
首先会获取library cache latch,然后根据该SQL语句的hash value到库高速缓存中查找可共享的代码,
如果找到则为软解析,server进程获得该执行计划。释放library cache latch,开始执行SQL语句。
如果没找到,则执行硬解析。
a) 释放library cache latch,获取shared pool latch,分配空闲空间。
b) 释放shared pool latch,获得library cache latch,将该SQL语句及执行计划存入刚分配的空闲空间。
c) 释放library cache latch,保持null模式的library cache pin/lock,开始执行SQL语句。
系统中latch资源有限,不能获得latch的部分进程将会进入spin状态,开始轮询尝试获取CPU使用权(这个过程会消耗CPU)。轮询一定次数后如果还未获得CPU使用权,进入睡眠状态。
多个进程的spin,就会引起CPU的攀升。随着等待latch的进程越来越多,最终将导致CPU100%,系统接近宕机。
2)对猜想的验证:
通过分析系统最近一段时间的latch: library cache及latch: shared pool争用,绘图如下:
可以看到系统升级后,这两latch争用明显上升。
查看系统v$sql中的硬解析语句,可以看到,改程序用户执行的SQL语句确实存在过多硬解析。
具体SQL就不贴了,放一图吧。
查看下parse time / db time*100%情况:
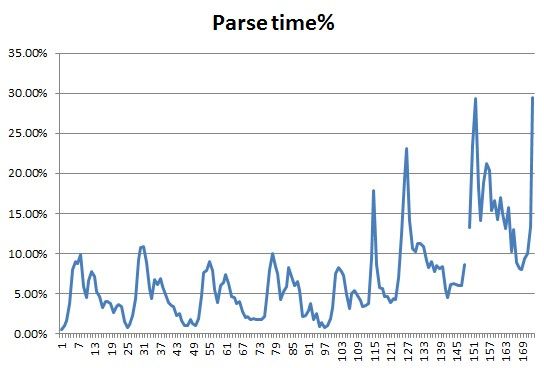
到这里,基本可以确定CPU攀升就是硬解析过多引起的了。
解决办法:
修改应用程序代码,应该是治本之法。不过这个一时半会也改不好,暂时考虑修改CURSOR_SHARING为SIMILAR。修改后重启了数据库,系统CPU基本平稳下来。
剩下的工作,就是等应用程序开发商修改代码,然后改回原来配置。因为10g下CURSOR_SHARING=SIMILAR存在不少bug,容易引起其他问题。
如:以前执行很快的语句,客户也会等待很长时间出不来SQL结果。 因为设置系统级的CURSOR_SHARING=SIMILAR,对数据库上所有SQL的执行计划都有影响。
设置CURSOR_SHARING=SIMILAR后,数据库会将相似的SQL语句,转化为绑定变量,使用第一次的执行计划,降低SQL硬解析次数,进而降低CPU利用率。注意,这里是第一次生成的执行计划。也就是SQL第一次被载入内存时,所生成的执行计划。
这可能会引起严重的性能问题。
例如:某表(在col1上有b-tree索引)查询select col1 ,count(*) from table group by col1;的返回结果如下:
col1 count(*)
1 30000
2 100
如果第一次执行的是,select col1,col2,col3 from table where col1=2;此时生成的执行计划,肯定是索引范围扫描。这个执行计划会被后续的SQL使用。
用户再次执行 select col1,col2,col3 from table where col1=1;时,会使用上次的计划。很明显,全表扫描是最佳方式,但oracle还是会根据上次的计划,执行索引范围扫描。这时会引起大量的磁盘I/O。以前执行很快的语句,客户也会等待很长时间出不来SQL结果。
10g中,如果谓词不是 = ,或该列上收集了直方图信息,就不会出现上面的情况。不同的绑定值,会生成不同的执行计划。
11g后,oracle使用ASC技术,这个缺点得到一定改善。
其他CURSOR_SHARING=SIMILAR引起的问题,还可能有:物化视图刷新报错、expdp 时间显著增加以及一些莫名其妙的bug。