hadoop2.2.0安装详解
- ①新的 Hadoop MapReduce框架 YARN
- ②HDFS 高可用性
- ③HDFS Federation(HDFS联盟):使得 HDFS支持多个命名空间,并且允许在 HDFS中同时存在多个 Name Node
- ④HDFS 快照
- ⑤NFSv3 可访问 HDFS中的数据
- ⑥支持在 Windows平台上运行 Hadoop
- ⑦兼容基于 Hadoop 1.x构建的 MapReduce 应用
- ⑧大量针对生态系统中其他项目的集成测试
关于Hadoop2.2.0升级的注意事项
- ①HDFS 社区建议将 symlinks功能从 2.3版本中移除,目前该功能已停用
- ②在新的 YARN/MapReduce中,用户需要更改 ShuffleHandler服务名称——需要将 mapreduce.shuffle改为 mapreduce_shuffle
关于YARN的介绍
- ①这个设计大大减小了 JobTracker(也就是现在的 ResourceManager)的资源消耗,并且让监测每一个 Job 子任务 (tasks)状态的程序分布式化了,更安全、更优美。
- ②在新的 Yarn中,ApplicationMaster 是一个可变更的部分,用户可以对不同的编程模型写自己的AppMst,让更多类型的编程模型能够跑在 Hadoop 集群中
- ③对于资源的表示以内存为单位 ( 在目前版本的 Yarn中,没有考虑 cpu的占用 ),比之前以剩余 slot数目更合理。
- ④老的框架中,JobTracker一个很大的负担就是监控 job下的 tasks 的运行状况,现在,这个部分就扔给 ApplicationMaster 做了,而 ResourceManager中有一个模块叫做 ApplicationsMasters(注意不是 ApplicationMaster),它是监测ApplicationMaster 的运行状况,如果出问题,会将其在其他机器上重启。
- ⑤Container 是 Yarn为了将来作资源隔离而提出的一个框架。这一点应该借鉴了 Mesos 的工作,目前是一个框架,仅仅提供 java虚拟机内存的隔离 ,hadoop团队的设计思路应该后续能支持更多的资源调度和控制 , 既然资源表示成内存量,那就没有了之前的 map slot/reduce slot分开造成集群资源闲置的尴尬情况。
Hadoop2.2.0部署安装
准备工作 :关于防火墙、SSH通信、JDK的安装、hosts配置、文件的上传等等就不一一介绍了,直切主题.
安装环境:Red Hat 6
单机模式:192.168.5.130 v
注:网上大多数教程都是扯犊子,乱七八糟,希望本文对大家有所帮助,运行起来Hadoop2.2从单机做起~~~
①上传Hadoop2.2.0到/usr/local目录下,并解压、重命名
目录结构如下:
[root@v hadoop2]# ls bin include libexec NOTICE.txt sbin etc lib LICENSE.txt README.txt share
其配置文件结构如下:
[root@v hadoop2]# cd etc/hadoop/ [root@v hadoop]# lscapacity-scheduler.xml httpfs-site.xmlconfiguration.xsl log4j.properties container-executor.cfg mapred-env.cmdcore-site.xml mapred-env.shhadoop-env.cmd mapred-queues.xml.templatehadoop-env.sh mapred-site.xml.template hadoop-metrics2.properties slaveshadoop-metrics.properties ssl-client.xml.examplehadoop-policy.xml ssl-server.xml.example hdfs-site.xml yarn-env.cmdhttpfs-env.sh yarn-env.sh httpfs-log4j.properties yarn-site.xmlhttpfs-signature.secret
②配置JAVA_HOME
Yarn 框架中由于启动HDFS分布式文件系统和启动 MapReduce框架分离,JAVA_HOME 需要在 hadoop-env.sh和 Yarn-env.sh 中分别配置
[root@v hadoop]# vi hadoop-env.sh
# export JAVA_HOME=${JAVA_HOME}【默认,蛋疼 却不认,需要修改】
export JAVA_HOME=/usr/local/jdk
[root@v hadoop]# vi yarn-env.sh
# some Java parameters export JAVA_HOME=/usr/local/jdk【需要手动修改】
③配置环境变量
export HADOOP_HOME=/usr/local/hadoop2 exportPATH=.:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$JAVA_HOME/bin:$PATH
然后执行命令:source/etc/profile
④配置HADOOP_LOG_DIR
老框架在 LOG, conf, tmp 目录等均默认为脚本启动的当前目录下的 log, conf, tmp 子目录,无需配置 但Yarn新框架中Log 默认创建在 Hadoop用户的 home目录下的 log子目录,因此最好在${hadoop_home_dir}/etc/hadoop/hadoop-env.sh配置 HADOOP_LOG_DIR,否则有可能会因为你启动hadoop的用户的 .bashrc或者.bash_profile 中指定了其他的 PATH 变量而造成日志位置混乱,而该位置没有访问权限的话启动过程中会报错
# Where log files are stored. $HADOOP_HOME/logs bydefault.export HADOOP_LOG_DIR=/usr/local/hadoop2/logs
⑤配置core-site.xml
<configuration> < property> <name>fs.default.name</name> < value>hdfs://v:9000</value>< /property> < property> < name>hadoop.tmp.dir</name>< value>/usr/local/hadoop2/tmp</value> < /property> </configuration>
⑥配置hdfs-site.xml
<configuration> < property> <name>dfs.default.name</name> <value>/usr/local/hadoop2/tmp</value> < /property> <property> < name>dfs.replication</name> <value>1</value> < /property> < property> <name>dfs.permissions</name> < value>false</value> </property> < /configuration>
⑦重命名 mapred-site.xml.template为mapred-site.xml并配置
<configuration> < property> <name>mapreduce.framework.name</name> < value>Yarn</value>< /property>
</configuration>
【注意】:此处无需配置mapred.job.tracker,因为JobTracker已经变成客户端的一个库,它可能被随机调度到任意一个slave上面,也就是说 它的位置是动态生成的.
该配置文件中mapreduce.framework.name必须指定采用的框架名称,默认是将作业提交到MRv1的JobTracker端.
⑧配置yarn-site.xml
<configuration>
<property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>v:8990</value> < description>host is the hostname of theresource manager and port is the port on which the NodeManagers contact theResource Manager. < /description> < /property>
<property> <name>yarn.resourcemanager.scheduler.address</name> <value>v:8991</value> < description>host is the hostname of theresourcemanager and port is the port on which the Applications in the clustertalk to the Resource Manager. < /description> < /property>
<property> <name>yarn.resourcemanager.scheduler.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>< description>In case you do not want to use the defaultscheduler</description> < /property>
<property> <name>yarn.resourcemanager.address</name> <value>v:8993</value> < description>the host is the hostname ofthe ResourceManager and the port is the port on which the clients can talk tothe Resource Manager. </description> < /property>
<property> <name>yarn.nodemanager.local-dirs</name> <value>/usr/local/hadoop2/tmp/node</value> < description>thelocal directories used by the nodemanager</description> </property>
<property> <name>yarn.nodemanager.address</name> <value>v:8994</value> < description>the nodemanagers bind to thisport</description> < /property>
<property> < name>yarn.nodemanager.resource.memory-mb</name>< value>10240</value> < description>the amount of memory onthe NodeManager in GB</description> < /property>
<property> <name>yarn.nodemanager.remote-app-log-dir</name> <value>/usr/local/hadoop2/tmp/app-logs</value> < description>directoryon hdfs where the application logs are moved to </description> </property>
<property> <name>yarn.nodemanager.log-dirs</name> <value>/usr/local/hadoop2/tmp/node</value> < description>thedirectories used by Nodemanagers as log directories</description> </property>
<property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> < description>shuffle servicethat needs to be set for Map Reduce to run </description> </property> < /configuration>
【注意】:为了运行MapReduce,需要让各个NodeManager在启动时加载shuffleserver, shuffle server实际是Jetty/Netty Server, Reduce Task通过该server从各个NodeManager上远程拷贝MapTask产生的中间结果.上面增加的两个配置用于指定shuffle server. 如果YARN集群有多个节点,还需要配置yarn.resourcemanager.address等参数
⑨修改slaves
localhost
到此配置完成
初始化Hadoop: hadoop namenode -format
欧了~~~~
进程如下:
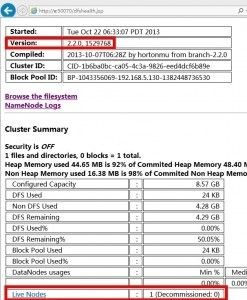
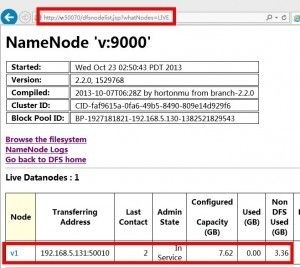
来张图,,哈哈,, 写的可能有细节疏漏,如果大家实际配置遇到问题欢迎随时留言给我
分布式就更简单喽 ,改一下slaves就欧啦 ~~~