Service与Android系统实现(1)-- 应用程序里的Service
转载:http://blog.csdn.net/21cnbao/article/details/8086487
特别声明:本系列文章作者系吴赫。分多次连载,讲述Android Service(JAVA Service、Native Service等)背后的实现原理,透析基于Binder的RPC以及Linux Binder驱动。
Service与Android系统实现(1)-- 应用程序里的Service
Service与Android系统设计(2)-- Parcel
Service与Android系统设计(3)-- ActivityManager的实现
Service与Android系统设计(4)-- ServiceManager
Service与Android系统设计(5)-- libbinder
Service与Android系统设计(6)--- Native Service
Service与Android系统设计(7)--- Binder驱动
Service
Service在Android应用程序里四大实体之一。Android的应用程序不光是需要有图形界面来进行交互,有时也会需要在没有交互的情况下进行的操作,比如下载、更新、监听等。比如目前对我们网络生存影响如此之大的社交网络、或是更老一些聊天工具,总需要这类应用程序可以一直在后台运行,以等待可能过来的消息。:
Service拥有一部分Activity所无法完成的能力。一是后台运行,有时我们并不希望有过多对话框来影响用户体验,开机自动启动,便可默默地在后台运行。另一特性,就是不被Activity生命周期所管理,Activity处于完全活跃的周期是onResume()与onPause()之间,如果这周期之外发生了事件,实际上Activity构成的执行部分也不会被执行到,从而无法响应处理,但Service由于本身过于简单,则会通过一定的辅助手段来达到这个目标。
从Android应用程序的设计原理来看,Service同样也是主线程里执行的(这点尤为重要,Service由于在主线程里执行,于是也会因为执行耗时操作而触发ANR)。一个应用程序既然可以通过拓展Activity得到可交互的代码逻辑,同样也可以通过拓展Service来得到不交互在后台执行的逻辑。如下图加强部分所示:
Activity对应用程序来说是最重要的组件,但从Android系统设计的角度来看,Service对系统层实现来说才最重要的。Service是构建系统的根本,支持整个系统运营的环境framework,本身就是由大量Service来构成的。也就是说,Service反而是构建Activity的基础环境。
Android与其他系统设计最大的不同之处在于,它并不是一种传统的系统环境,而是一种更加开放的系统。传统的图形操作系统里,会有基本环境,会有系统管理组件,应用程序只是作为补充性功能实现。但Android并不如此,Android系统是没有应用程序的,达到了“无边界”系统设计的最高境界,“手里无剑,心中有剑”。整个Android系统的设计使自己扮演着支撑系统的运行环境的角色,不再有基本系统的概念,而变成了一种“有或者无”的应用程序的支撑环境,没有系统组件的概念。而我们所谓的系统应用程序,我们只能称它们为“内置”应用程序,只是服务于黑心移动运营商的一种方式而已。
这种设计的精髓在于,系统本身不会处理交互,而只是提供交互的手段。从前面我们对于应用程序运行环境的分析中,我们可以看到,Android的Framework,提供一部分功能供应用程序调用,而除了这些应用程序直接使用的API实现,其他代码逻辑就会全是由Service构成。当然作为系统实现角度的Service,与应用程序编程里实现的Service是有差别的,更强调共享,但基本构架一样。在过渡到Android系统的解析之前,我们先从应用程序的Service概念入手。
本地简单Service
我们先来在应用程序里写一个简单的Service。打开Eclipse,新建一个Android工程,然后再创建一个新的基于Service基类的类。与Activity的编程方式类似,Service在编程上也是基于回调方式实现的,我们继承基类Service之后所需要做的,就是通过IoC模式替换原来的Service回调的实现:
- import android.app.Service;
- import android.content.Intent;
- import android.os.IBinder;
- import android.util.Log;
- public class LianlabServiceextends Service
- {
- private staticfinal String TAG ="LianlabService";
- @Override
- public void onCreate() {
- super.onCreate();
- Log.v(TAG, "inonCreate()");
- }
- @Override
- public int onStartCommand(Intent intent,int flags,int startId) {
- super.onStartCommand(intent, flags, startId);
- Log.v(TAG, "inonStartCommand()");
- return START_STICKY;
- }
- @Override
- public void onDestroy()
- {
- Log.v(TAG, "inonDestroy().");
- super.onDestroy();
- }
- }
有了Service的具体实现之后,系统并不会自动地识别到这一实现,在Android世界里,一切都通过AndroidManifest.xml来驱动,于是,我们还需要修改AndroidManifest.xml文件,加入Service的定义:
- <applicationandroid:labelapplicationandroid:label="@string/app_name">
- <serviceandroid:nameserviceandroid:name=".LianLabService"/>
- ;/application>
在上面这种方式里实现的Service,可被执行的方式很有限,就是提供一个可执行的线程环境,可以被Intent所驱动,执行onStartCommand()回调。功能有限并不代表无能,在Android系统里,我们可能还经常会碰到这样的需求:比如我们使用GPS里来记录我们行动轨迹时,这时我们很可能需要通过后台的执行的代码来定时检查GPS的定位信息;杀毒或是监控软件可能希望驻留在后台,并可被Intent来驱动开始进行杀毒;我们的聊天或是社交应用,需要在后台定时地与服务发送“心跳”(Heart beat),用来标识自己的在线状态等。这样的例子,大家可以回头到我们画的GPS轨迹跟踪的构成示意图,这样的跟踪软件,必须是通过一个接收启动完成信息的Broadcast Receiver来监听自己是否应该被执行,而接收到到启动完成的Broadcast Intent之后,则必须触发一直在后台运行的TrackerService的执行。
既然我们在上述方式里实现的Service是由Intent驱动的,于是我们的使用这一Service部分的代码也会很简单。在任何可被执行到的代码里使用startService(Intent)就可以完成,我们可以给某个控件注册点击事件支持onClickListener对象,然后覆盖onClick()回调方法:
- public void onClick(Viewv) {
- Intent intent = new Intent(this,
- LianlabService.class);
- startService(intent);
- }
我们这里既然使用到了Intent,也就是说我们还可以通过extras这个Bundle对象给我们这里实现的LianLabService来传递运行的参数。于是,这时我们的代码貌似有了pthread多线程执行效果,通过传参,然后我们会执行一个在另一线程里运行的函数,只是函数是固定的onStartCommand()回调方法。但这只是貌似,并非实际情况,Service的执行与后台线程方式极大不同,Service只是一种代码逻辑的抽象,实际上它还是运行在Activity同一线程上下文环境。
于是,我们并不能用Service来进行任何耗时操作,否则会阻塞主线程而造成应用程序的无法响应错误,也就是臭名昭著的ANR错误。Service仅能用于不需要界面交互的代码逻辑。
本地 Bounded Service
这种使用Intent来驱动执行的Service,可用性有限,并不能完全满足我们对于后台服务的需求。对于后台执行的代码,我们更多的应用情境不光是希望进行后台操作,我们可能还希望能进行交互,可以随时检查后台操作的结果,并能暂停或是重启后台执行的服务,可以在使用某一Service时保证它并不会退出执行,甚至一些提交一些参数到后台来进行复杂的处理。这时,我们可以使用Service的另一个访问方式,使用Binder接口来访问。我们的Service基类还提供这类应用的回调方式,onBind()、onUnbind()和onRebind()。使用Binder来访问Service的方式比Intent驱动的应用情境更底层,onBind()回调主要用于返回一个IBinder对象,而这一IBinder对象是Service的引用,将会被调用端用于直接调用这一Service里实现的某些方法。
同样的Service实现,如果通过IBinder来驱动,则会变成下面的样子:
- import android.app.Service;
- import android.content.Intent;
- import android.os.IBinder;
- import android.util.Log;
- public class LianlabServiceextends Service
- {
- private staticfinal String TAG ="LianlabService";
- @Override
- public void onCreate() {
- super.onCreate();
- Log.v(TAG, "inonCreate()");
- }
- @Override
- public intonStartCommand(Intent intent,int flags,int startId) {
- super.onStartCommand(intent, flags, startId);
- Log.v(TAG, "in onStartCommand()");
- return START_STICKY;
- }
- @Override
- public void onDestroy()
- {
- Log.v(TAG, "inonDestroy().");
- super.onDestroy();
- }
- finalIService.Stub m_binder =newIService.Stub() {
- ...
- }
- @Override
- public IBinderonBind(Intent intent) {
- Log.v(TAG, "inonBind().");
- return mBinder;
- }
- @Override
- public booleanonUnbind(Intent intent) {
- Log.v(TAG, "inonUnbind().");
- return mAllowRebind;
- }
- @Override
- public void onRebind(Intentintent) {
- Log.v(TAG, "inonRebind().");
- }
- }
使用IBinder对象来触发的Service,在访问时的代码实现则变得完全不样了。比如我们同样通过onClick()来操作后台的某些操作,但这时并非通过Intent来完成,而是直接使用某个引用这一Service的IBinder对象来直接调用Service里实现的方法。
- bindService(intent, m_connection, …);
- private ServiceConnection m_connection =new ServiceConnection() {
- private IService onServiceConnected(…, IBinder service) {
- m_service =IService.Stub.asInterface(service);
- }
- }
如果Service里实现了某些方法,比如kill(),在上述代码之后,我们对Service的驱动则会变成代码上的直接调用。在onServiceConnected()回调方法被触发之后,我们始终都可以通过m_service.kill()来访问Service里的kill()方法。而bindService()这方法的调用,则会触发onServiceConnected()事件。
这样就要让人抓狂了,既然如此麻烦,何不直接调用呢?所以,事实上,这里列举的这种代码实现方式,在现实编程里确实不常用。一般而言,如果Service通过IBinder对象来触发,那只会出于一个理由,提供一种可能性,将来可以更灵活地提供给另一进程来访问,这就是我们稍后会说明的Remote Service。
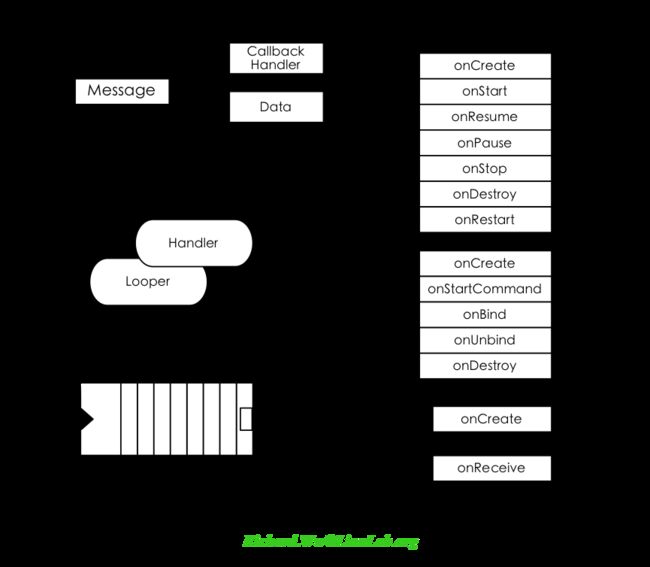
这两种不同的Service的实现方式,将决定Service的不同被调用方式,或者准确地说,将决定Service的不同生命周期。
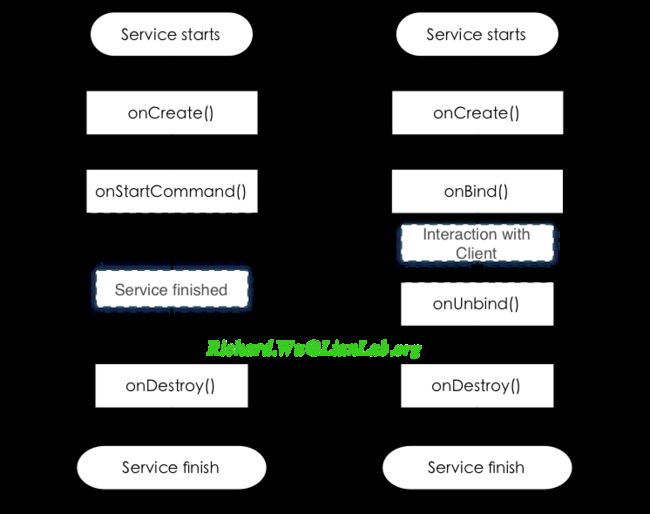
如图所示,Service的进程存活期是处理onCreate()与onDestroy()回调方法之间。onStartCommand()回调是不受控的,每次Intent都将触发执行一次, onStartCommand()执行完则会退出;而使用onBind()来驱动的Service,其活跃区间是onBind()与onUnbind()之间,其活跃周期始终在控制范围内。
Remote Service
得益于Android的进程间模型,无论是系统实现端的开发,还是应用程序的开发者,可认为自己的代码都将在一种安全的环境下执行。但对于在需要共享的场合,又带来了不方便之处,我们不再可以在一个进程里很方便地调用到另一进程里的实现。在上面两种Service实现里,基本上只能自已服务自己,而不能将功能共享给更多地使用者。于是,Android在设计初期,便引入了另一个概念,Remote Service。
Remote Service定义了如何从一个进程,直接访问到另一个进程里实现的方法,这样的机制在通用编程领域被称为RPC,Remote Procedure Call,在Android环境里,因为这样的RPC与Service的概念揉合到了一起,所以被称为Remote Service。
如下图所示,Remote Service基本上算是在Bounded Service实现上的一种拓展。调用端(一般是与用户交互的Activity)会通过bindService()发一个Intent到Service进程,而Service进程会在onBind()回调方法里返回自己的Service处理接口。当调用端得到相应的处理接口,也就是下图所示的Stub.Proxy对象之后,就可以调用远端Stub对象里实现的方法。

当然,由于这种方式需要在每一次调用时都进行一次远程调用,于是实现起来并不简单,甚至可以说是会很麻烦。在上图逻辑里要实现一个Remote Service,在这一Remote Service里实现一个方法,就需要加入多个对象。于是,在Android里引入了AIDL,可以通过AIDL来简化通用代码的处理,在上图中Stub对象、Stub.Proxy对象都将由aidl自动管理。
实现一个Remote Service,基本上可以分三步完成:
- 定义aidl
- 实现被调用的Remote Service(提供可实例化的Stub对象)
- 调用Remote Service
定义AIDL
- packageorg.lianlab.service;
- interface ITaskService {
- int getPid ( );
- }
实现Remote Service
有了AIDL定义之后,我们便可实现这这一接口类的定义,主要是提供一个Stub类的实现,在这个Stub对象里,提供getPid(void)的具体实现。
- private finalITaskService.Stub mTaskServiceBinder =new ITaskService.Stub() {
- public int getPid() {
- return Process.myPid();
- }
- };
于是,当应用程序通过某种方式可以取得ITaskServiceStub所对应的IBinder对象之后,就可以在自己的进程里调用IBinder对象的getPid(),但这一方法实际上会是在别一个进程里执行。虽然我们对于执行IBinder的Stub端代码的执行环境并没有严格要求,可以在一个运行中的进程或是线程里创建一个Stub对象就可以了,但出于通用性设计的角度考虑,实际上我们会使用Service类来承载这个Stub对象,通过这样的方式,Stub的运行周期便被Service的生存周期所管理起来。这样实现的原因,我们可以回顾我们前面所描述的功耗控制部分。当然,使用Service带来的另一个好处是代码的通用性更好,我们在后面将感受到这种统一化设计的好处。
于是,对应于.aidl的具体实现,我们一般会使用一个Service对象把这个Stub对象的存活周期“包”起来。我们可以通过在Service里使用一个 final类型的Stub对象,也可以通过在onBind()接口里进行创建。这两种不同实现的结果是,使final类型的Stub对象,类似于我们的Singleton设计模式,客户端访问过来的总会是由同一个Stub对象来处理;而在onBind()接口里创建新的Stub,可以让我们对每个客户端的访问都新建一个Stub对象。出于简化设计的考虑,我们一般会使用final的唯一Stub对象,于是我们得到的完整的Service实现如下:
- package org.lianlab.services;
- import android.app.Service;
- import android.content.Intent;
- import android.os.IBinder;
- import android.os.Process;
- public class TaskService extends Service {1
- @Override
- public IBinderonBind(Intent intent) {
- if (ITaskService.class.getName().equals(intent.getAction())) {2
- return mTaskServiceBinder;
- }
- return null;
- }
- private finalITaskService.Stub mTaskServiceBinder =new ITaskService.Stub() { 3
- public int getPid() { 4
- return Process.myPid();
- }
- };
- }
- 由于实现上的灵活性,我们一般使用Service来承载一个AIDL的Stub对象,于是这个Stub的存活周期,会由Service的编写方式决定。当我们的Stub对象是在onBind()里返回时,Stub对象的存活周期是Service处于Bounded的周期内;如果使用final限定,则Stub对象的存活周期是Service在onCreate()到onDestroy()之间
- 用于处理bindService()发出Intent请求时的Action匹配,这一行一般会在AndroidManifest.xml文件里对Service对Intent filter设置时使用。我们这种写法,则使这一Service只会对Intent里Action属性是“org.lianlab.services.ITaskService”的bindService()请求作出响应。这一部分我们在后面的使用这一Service的Activity里可以看到
- 创建ITaskService.Stub对象,并实现Stub对象所要求的方法,也就是AIDL的实现。Stub对象可以像我们这样静态创建,也可以在onBind()里动态创建,但必须保证创建在onBind()返回之前完成。在onBind()回调之后,实际上在客户端则已经发生了onServiceConnected()回调,会造成执行出错。
- 实现,这时我们最终给客户端提供的远程调用,就可以在Stub对象里实现。我们可以实现超出AIDL定义的部分,但只有AIDL里定义过的方法才会通过Binder暴露出来,而AIDL里定义的接口方法,则必须完整实现。
有了这样的定义之后,我们还需要在AndroidManifest.xml文件里将Service声明出来,让系统里其他部分可以调用到:
- <application
- …
- <service android:name=".TaskService">
- <intent-filter>
- <action android:name="org.lianlab.services.ITaskService"/>
- </intent-filter>
- </service>
- </application>
在AndroidManifest.xml文件里,会在<application>标签里通过<service>标签来申明这一应用程序存在某个Service实现,在service命名里,如果service的名称与application名称的包名不符,我们还可以使用完整的“包名+类名”这样命名方式来向系统里注册特殊的Service。在<service>标签里,我们也可以注册<intent-filter>来标明自己仅接收某一类的Intent请求,比如我们例子里的action会匹配“org.lianlab.services.ITaskService”,如果没有这样的intent-filter,则任何以TaskService(ComponentName的值是”org.lianlab.services.ITaskService”)为目标的Intent请求会触发TaskService的onBind()回调。当然,我们在<service>标签内还可以定义一些权限,像我们例子里的这个TaskService是没有任何权限限制的。有了这个AndroidManifest.xml文件,我们再来看看客户端的写法。
访问Remote Service
在客户端进行访问时,由于它必须也使用同一接口类的定义,于是我们可以直接将同一.aidl文件拷贝到客户端应用程序的源代码里,让这些接口类的定义在客户端代码里也可以被自动生成,然后客户端便可以自动得到Proxy端的代码。因为我们这里使用了Service,又是通过onBind()返回IBinder的对象引用,这时客户端在使用IBinder之前,需要通过bindService()来触发Service端的onBind()回调事件,这时会通过客户端的onServiceConnected()回调将Stub所对应的Binder对象返回。我们在稍后看AIDL的底层实现时会发现,在此时客户端的Binder对象只是底层Binder IPC的引用,此时我们还需要创建一个基于这一Stub接口的Proxy,于是在客户端会需要调用asInterface()创建Proxy对象,这一Proxy对象被转义成具体的Service,在我们的例子里,客户端此时就得到了ITaskService对象。从这时开始,在客户端里通过ITaskService.getPid()的调用,都会通过Binder IPC将操作请求发送到Service端的Stub实现。于是,我们可以得到客户端的代码,在Android里我们一般用Activity来完成这样的操作,如下代码所示:
- package org.lianlab.hello;
- import android.os.Bundle;
- import android.os.IBinder;
- import android.os.RemoteException;
- import android.app.Activity;
- import android.content.ComponentName;
- import android.content.Context;
- import android.content.Intent;
- import android.content.ServiceConnection;
- import android.util.Log;
- import android.view.View;
- import android.view.View.OnClickListener;
- import android.widget.TextView;
- import org.lianlab.services.ITaskService;1
- import org.lianlab.hello.R;
- public class Helloworld extends Activity
- {
- /** Called when the activity is first created.*/
- ITaskService mTaskService = null; 2
- @Override
- public voidonCreate(Bundle savedInstanceState)
- {
- super.onCreate(savedInstanceState);
- setContentView(R.layout.main);
- bindService(new Intent(ITaskService.class.getName()),mTaskConnection,
- Context.BIND_AUTO_CREATE); 3
- ((TextView) findViewById(R.id.textView1)).setOnClickListener(
- new OnClickListener() {
- @Override
- public void onClick(Viewv) {
- if (mTaskService !=null) {
- try { 4
- int mPid = -1;
- mPid = mTaskService.getPid();
- Log.v("get Pid "," = " +mPid);
- ((TextView)findViewById(R.id.textView1)).setText("Servicepid is" + mPid);
- } catch(RemoteException e) {
- e.printStackTrace();
- }
- }
- else {
- ((TextView)findViewById(R.id.textView1)).setText("Noservice connected");
- }
- }
- });
- }
- privateServiceConnectionmTaskConnection = new ServiceConnection() { 5
- public void onServiceConnected(ComponentName className, IBinder service) {
- mTaskService = ITaskService.Stub.asInterface(service); 6
- }
- public void onServiceDisconnected(ComponentName className) {
- mTaskService = null;
- }
- };
- @Override
- public void onDestroy()
- {
- super.onDestroy();
- if (mTaskService !=null) {
- unbindService(mTaskConnection); 7
- }
- }
- }
- 必须导入远端接口类的定义。我们必须先导入类或者函数定义,然后才能使用,对于任何编程语言都是这样。但我们在AIDL编程的环境下,实际这一步骤变得更加简单,我们并非需要将Service实现的源文件拷贝到应用程序源代码里,也是只需要一个AIDL文件即可,这一文件会自动生成我们所需要的接口类定义。所以可以注意,我们导入的并非Service实现的”org.lianlab.services.TaskService”,而AIDL接口类的”org.lianlab.services.ITaskService”。这种方式更灵活,同时我们在AIDL环境下还得到了另一个好处,那就是可以隐藏实现。
- 对于客户端来说,它并不知道TaskService的实现,于是我们统一使用ITaskService来处理对远程对象的引用。跟步骤1对应,这时我们会使用ITaskService来访问远程对象,就是我们的mTaskService。
- 我们必须先创建对象,才能调用对象里的方法,对于AIDL编程而言,所谓的创建对象,就是通过bindService()来触发另一个进程空间的Stub对象被创建。bindService()的第一参数是一个Intent,这一Intent里可以通过ComponentName来指定使用哪个Service,但此时我们会需要Service的定义,于是在AIDL编程里这一Intent会变通为使用ITaskService作为Action值,这种小技巧将使bindService()操作会通过IntentFilter,帮我们找到合适的目标Service并将其绑定。bindService()的第二个参数的类型是ServiceConnection对象,bindService()成功将使用这样一个ServiceConnection对象来管理onServiceConnected()与onServiceDisconnected()两个回调,于是一般我们会定义一个私有的ServiceConnection对象来作为这一参数,见5。最后的第三个参数是一个整形的标志,说明如何处理bindService()请求,我们这里使用Context.BIND_AUTO_CREATE,则发生bindService()操作时,如果目标Service不存在,会触发Service的onCreate()方法创建。
- 我们这里使用onClickListener对象来触发远程操作,当用户点击时,就会尝试去执行mTaskService.getPid()方法。正如我们看到的,getPid()是一个RPC方法,会在另一个进程里执行,而Exception是无法跨进程捕捉的,如果我们希望在进行方法调用时捕捉执行过程里的异常,我们就可以通过一个RemoteException来完成。RemoteException实际上跟方法的执行上下文没有关系,也并非完整的Exception栈,但还是能帮助我们分析出错现场,所以一般在进行远端调用的部分,我们都会try来执行远程方法然后捕捉RemoteException。
- 如3所述,bindService()会使用一个ServiceConnection对象来判断和处理是否连接正常,于是我们创建这么一个对象。因为这个私有ServiceConnection对象是作为属性存在的,所以实际上在HelloActivity对象的初始化方法里便会被创建。
- 在onServiceConnected()这一回调方法里,将返回引用到远程对象的IBinder引用。在Android官方的介绍里,说是这一IBinder对象需要通过asInterface()来进行类型转换,将IBinder再转换成ITaskService。但在实现上并非如此,我们的Proxy在内部是被拆分成Proxy实现与Stub实现的,这两个实现都使用同一IBinder接口,我们在onServiceConnected()里取回的就是这一对象IBinder引用,asInterface()实际上的操作是通过IBinder对象,得到其对应的Proxy实现。
- 通过bindService()方法来访问Service,则Service的生存周期位于bindService()与unbindService()之间的Bounded区域,所以在bindService()之后,如果不调用unbindService()则会造成内存泄漏,Binder相关的资源无法得到回收。所以在合适的点调用unbindService()是一种好习惯。
这种方式很简单易行,实际上在编程上,AIDL在编程上带来的额外编码上的开销非常小,但得到了灵活性设计的RPC调用。
双向Remote Service
在AIDL编程环境里实际上是支持反向调用的,原理跟我们实现一个Remote Service一样,就是通过把Proxy与Stub反过来,就得到了这样的回调式的aidl编程。唯一的区别是,当我们的Stub在Activity时实现时,我们实际上跟后台线程执行也没有区别,Callback并非是在主线程里执行的,于是不能进行重绘界面的工作。于是,我们必须像后台线程编程一样,使用Handler来处理界面显示处理。
定义AIDL
前面我们说过aidl是可以互相引用的,于是我们可以借用这样的机制,通过引用另一个新增的aidl文件来加强我们前面的单向的TaskService版本。我们先增加一个新的ITaskServiceCallback.aidl文件,与ITaskService保持同一目录:
- package org.lianlab.services;
- onewayinterface ITaskServiceCallback {
- void valueCounted(int value);
- }
在这一定义里,我们新增加了一个ITaskServiceCallback的接口类,基本上与我们前面的ITaskService.aidl一样,在这个接口类里,我们新加了一个valueCounted()方法,这一方法将会被Service所使用。
在这个文件里,唯一与ITaskService.aidl不同之处在于,我们使用了一个oneway的标识符,oneway可以使aidl调用具有异步调用的效果。在默认情况下,基于aidl的调用都会等待远端调用完成之后再继续往下执行,但有时我们可能希望在跨进程调用会有异步执行的能力,我们在发出调用请求后会立即返回继续执行,调用请求的结果会通过其他的callback返回,或是我们干脆并不在乎成功与否,此时就可以使用oneway。当然,从我们前面分析aidl底层进行的工作,我们可以知道,所谓的远程调用,只不过是通过Binder发送出去一个命令而已,所以在aidl里面如果使用了oneway限定符,也就是发送了命令就收工。
然后,我们修改一下我们的ITaskService.aidl,使我们可以使用上这个新加入的回调接口:
- package org.lianlab.services;
- import org.lianlab.services.ITaskServiceCallback;
- interface ITaskService {
- intgetPid (ITaskServiceCallback callback);
- }
在Service端调用回调方法
我们会引用前面定义好的ITaskServiceCallback.aidl文件,通过包名+接口的方式进行引用。为了省事,我们直接在原来的getPid()方法里进行修改,将新定义的ITaskServiceCallback接口类作为参数传递给getPid()接口。于是,在Service端Stub对象里实现的getPid()方法,将可以使用这一回调对象:
- package org.lianlab.services;
- import android.app.Service;
- import android.content.Intent;
- import android.os.IBinder;
- import android.os.Process;
- import android.os.RemoteException;
- public class TaskService extends Service {
- static private int mCount = 0;
- @Override
- public IBinder onBind(Intent intent) {
- if (ITaskService.class.getName().equals(intent.getAction())) {
- return mTaskServiceBinder;
- }
- return null;
- }
- private final ITaskService.Stub mTaskServiceBinder = newITaskService.Stub() {
- public int getPid(ITaskServiceCallback callback) { 1
- mCount ++ ; 2
- try { 3
- callback.valueCounted(mCount); 4
- } catch (RemoteException e) {
- e.printStackTrace();
- }
- return Process.myPid();
- }
- };
- }
加入了回调之后的代码结构并没有大变,只增加了3部分的内容,通过这三部分的内容,我们此时便可以记录我们的getPid()总共被调用了多少次。
- getPid()方法,是通过aidl定义来实现的,否则会报错。所以我们这里新的getPid()会按照aidl里的定义加入ITaskServiceCallback对象作为参数,与ITaskService对象相反,这一对象实际上是由客户端提供给Service端调用的。
- 为了记录下getPid()被调用了多少次,我们使用了一个mCount来进行计数,这一int为static类型,于是在Service生存周期里会始终有效。但这部分的改动与我们的回调改进并无直接关系。
- 在使用回调接口ITaskServiceCall之前,因为这是一个远程引用,我们会需要捕捉Remote Exception,由客户端抛出的异常将在这里被捕获处理。
- 调用ITaskServiceCall里定义的回调方法,将处理发送给客户端。此时,因为是oneway,这时很多就会从回调方法里返回,继续执行原来的getPid(),再将处理结果以返回值的形式发送回客户端。
加入了回调之后,对Service端的实现并没有增加多大的工作量,因为作为回调,实现是放在客户端上来完成的。
在Client端加入回调实现
因为我们的aidl接口已经发生了变动,于是需要将新加的ITaskServiceCall.aidl与改变过的ITaskService.aidl文件拷贝到应用程序工程里。我们再来看一下客户端实现代码需要作怎样的调整:
- package org.lianlab.services;
- import android.os.Bundle;
- import android.os.Handler;
- import android.os.IBinder;
- import android.os.RemoteException;
- import android.app.Activity;
- import android.content.ComponentName;
- import android.content.Context;
- import android.content.Intent;
- import android.content.ServiceConnection;
- import android.view.View;
- import android.view.View.OnClickListener;
- import android.widget.TextView;
- import org.lianlab.services.R;
- public class MainActivity extends Activity {
- ITaskService mTaskService = null;
- private TextView mCallbackText;
- private Handler mHandler = new Handler();
- @Override
- public void onCreate(Bundle savedInstanceState) {
- super.onCreate(savedInstanceState);
- try {
- bindService(newIntent(ITaskService.class.getName()), mTaskConnection,
- Context.BIND_AUTO_CREATE);
- } catch (SecurityException e) {
- e.printStackTrace();
- }
- setContentView(R.layout.activity_main);
- ((TextView)findViewById(R.id.textView1)).setOnClickListener(new OnClickListener() {
- @Override
- public void onClick(View v) {
- if (mTaskService != null) {
- try {
- int mPid = -1;
- mPid =mTaskService.getPid(mCounter); 1
- ((TextView)findViewById(R.id.textView1))
- .setText("Service pid is " + mPid);
- } catch (RemoteException e){
- e.printStackTrace();
- }
- } else {
- ((TextView)findViewById(R.id.textView1)).setText("No service connected");
- }
- }
- });
- mCallbackText = (TextView) findViewById(R.id.callbackView); 2
- mCallbackText.setText("Clicked 0 times");
- }
- @Override
- public void onDestroy() {
- super.onDestroy();
- if (mTaskService != null) {
- unbindService(mTaskConnection);
- }
- }
- private ServiceConnection mTaskConnection = new ServiceConnection() {
- public void onServiceConnected(ComponentName className, IBinder service){
- mTaskService = ITaskService.Stub.asInterface(service);
- }
- public void onServiceDisconnected(ComponentName className) {
- mTaskService = null;
- }
- };
- private ITaskServiceCallback.Stub mCounter = newITaskServiceCallback.Stub() { 3
- public void valueCounted(final int n) {
- mHandler.post(new Runnable() { 4
- public void run() {
- mCallbackText.setText("Clicked " + String.valueOf(n) + " times");
- }
- });
- }
- };
- }
新加入的回调接口对象,也没给我们带来多大的麻烦,我们最重要是提供一个实例化的ITaskServiceCallback.Stub对象,然后通过getPid()将这一远程对象的引用发送给Service端。之后,Service处理后的回调请求,则会通过Binder会回到客户端,调用在Stub对象里实现的回调方法。所以我们实际增加的工作量,也仅是写一个ITaskServiceCallback.Stub接口类的实现而已:
- 我们需要使用通过getPid(),将ITaskServiceCallback.Stub传递给Service。因为这一对象是用于Service使用的,于是我们必须在使用前先创建,然后再以引用的方式进行传递,像我们代码例子里的mCounter对象。
- 这一部分的改动,只是为了让我们检查效果时更方便,我们通过一个新加的id为callbackView的textView,来显示getPid()被调多次的效果。
- 这是我们真正所需的改动,通过新建一个ITaskServiceCallback.Stub对象,于是当前进程便有了一个Stub实体,用于实现aidl里定义的valueCounted()接口方法,对Binder过来这一接口方法的调用请求作响应。
- valueCounted()是一个回调方法,从编程模型上我们可以类似的看成是由Service进程所执行的代码,于是我们需要通过Handler()来处理显示。当然,在实现上不可能如此神奇,我们可以把一个方法搬运到另一个进程空间里运行,但valueCounted()既然也不是在主线程环境里执行,而是通过线程池来响应Binder请求的,于是跟后台线程的编程方式一样,我们使用Handler来处理回显。Handler本身是一种很神奇的实现机制,它可以弱化编程环境里的有限状态机的硬性限制,也可以使代码在拓展上变得更灵活,我们会在后续内容里加以说明。
从上面的代码可以看出,我们通过aidl创建回调方法好像比我们直接通过aidl写一个Remote Service还要简单。事实上,并非回调创建方便,在原则上,我们本只需要一个Stub对象便可以得到我们想要的RPC能力了,只不过出于管理存活周期的需要,才融入到了Service管理框架里,因为这种Service使用上的需求才带来了一些编程上的开销
AIDL的内部实现
aidl工具的工作原理也很简单, aidl工具的源代码在frameworks/base/tools/aidl里,如果对通过bison来实现编译器感兴趣也可以参考其实现。
而AIDL工具所完成的工作,是将aidl文件转义成一个通用的Java文件,我们实现的内容,便是拓展自这一Java文件里的定义。aidl工具生成的结果,一般与aapt工具生成的结果放在同一目录,在应用程序环境里,aidl生成的结果是一个在gen/包名/目录里与aidl文件前缀名相同的Java文件,我们的例子里会是gen/org/lianlab/services/ITaskService.java,我们可以看一下这个生成文件的内容:
- package org.lianlab.services;
- public interface ITaskService extends android.os.IInterface { 1
- public static abstract class Stub extendsandroid.os.Binderimplements
- org.lianlab.services.ITaskService { 2
- private static final java.lang.String DESCRIPTOR = "org.lianlab.services.ITaskService"; 3
- public Stub() {
- this.attachInterface(this,DESCRIPTOR); 4
- }
- public static org.lianlab.services.ITaskService asInterface(android.os.IBinderobj) { 5
- if ((obj == null)) {
- return null;
- }
- android.os.IInterface iin = (android.os.IInterface)obj.queryLocalInterface(DESCRIPTOR);
- if (((iin != null) && (iin instanceof org.lianlab.services.ITaskService))) {
- return((org.lianlab.services.ITaskService) iin);
- }
- return new org.lianlab.services.ITaskService.Stub.Proxy(obj); 6
- }
- public android.os.IBinder asBinder() {
- return this;
- }
- @Override
- public boolean onTransact(int code, android.os.Parcel data, android.os.Parcel reply,
- int flags)throwsandroid.os.RemoteException { 7
- switch (code) {
- case INTERFACE_TRANSACTION: { 8
- reply.writeString(DESCRIPTOR);
- return true;
- }
- case TRANSACTION_getPid: { 9
- data.enforceInterface(DESCRIPTOR);
- int _result =this.getPid();
- reply.writeNoException();
- reply.writeInt(_result);
- return true;
- }
- }
- return super.onTransact(code, data, reply, flags); 10
- }
- private static class Proxy implements org.lianlab.services.ITaskService { 11
- private android.os.IBindermRemote; 12
- Proxy(android.os.IBinder remote) {
- mRemote = remote;
- }
- public android.os.IBinder asBinder() {
- return mRemote;
- }
- public java.lang.StringgetInterfaceDescriptor() {
- return DESCRIPTOR;
- }
- public int getPid() throws android.os.RemoteException { 13
- android.os.Parcel _data =android.os.Parcel.obtain();
- android.os.Parcel _reply =android.os.Parcel.obtain();
- int _result;
- try {
- _data.writeInterfaceToken(DESCRIPTOR);
- mRemote.transact(Stub.TRANSACTION_getPid,_data, _reply, 0);
- _reply.readException();
- _result = _reply.readInt();
- } finally {
- _reply.recycle();
- _data.recycle();
- }
- return _result;
- }
- }
- static final int TRANSACTION_getPid = (android.os.IBinder.FIRST_CALL_TRANSACTION + 0); 14
- }
- public int getPid() throwsandroid.os.RemoteException;
- }
上述生成的ITaskService.java文件,在类图上大致由如下的关系来构成:
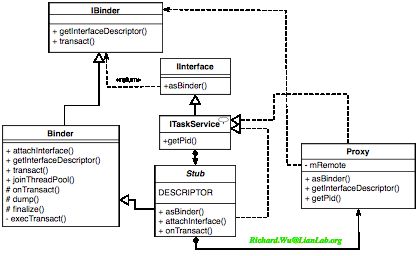
IInterface接口类在Binder框架里是两边访问的基础,只通过asBinder访问一个IBinder对象。在Proxy模式里核心接口类Interface部分的功能,实际上则由拓展IInterface的自定义的ITaskService来完成,通过同一接口,客户端会得到Proxy对象,而Service会得到Stub对象。在Android环境里,Proxy只是Stub类的一部分,这是Proxy在实现上的一种变体,从而强调Stub作为实现上的重要性,Proxy需要依赖于其对应的Stub接口的存在。我们可以详细分析一下,这些自动生成的代码的含义:
- 定义一个ITaskService接口类,继承自同样是接口类的IInterface。IInterface接口类的作用很简单,就是能够通过asBinder()方法返回一个IBinder接口对象。IBinder本质上也是接口类,不过比IInterface要复杂,这一接口用来细分出一些Binder通信上的接口,从而基于同一接口,在发送端实现发送代码transact(),在接收端实现接收代码onTransact()。像我们前面看到的所有Binder对象,其实都是继承自这一接口,于是使用Binder对象天生是跨进程对象,所以有继承自Binder的类,被创建后都会是具备跨进程能力的远程对象。从这里的实现,我们也可以看到,IBinder与Binder 的接口与实现抽离,可以使用我们可以灵活地使用统一的IBinder接口访问到不同进程空间里的Binder对象。ITaskService接口类,实际上很简单,就是定义一个抽象类Stub,以及aidl里定义的接口方法。
- 定义一个抽象类Stub,同时继承Binder类,并实现ITaskService接口。继承Binder,使Stub对象将成为跨进程的远程对象,而实现ITaskService接口,则使Binder IPC通信里发生的ITaskService相关的操作,都将转发到Stub对象的onTransact()方法里处理。作为抽象类的Stub,于是它不可能单独被实例化,必须通过实现抽象类里缺失的方法来得到一个实质的类,因为我们的ITaskService接口类只需要getPid()实现,于是我们的Stub所缺失的也只有这一方法。
- Stub里会包含一个静态、final类型的字符串DESCRIPTOR,这一字符串用于Binder通信时的标识。DESCRIPTOR在aidl翻译时会使用aidl接口类的名字,所以这一字符串是不会重复的。
- 在Stub对象的初始化方法里,会调用attachInterface()将DESCRIPTOR注册到Binder对象里,于是当一个完整实现的Stub对象被创建时,以它的接口类名为标识的信息就会注册到Binder通信里,从而Binder IPC里以 DESCRIPTOR为目标的消息就会传到这一Stub实现里。
- asInterface()是提供给客户端来调用的方法。在基于aidl的编程里,客户端通过onServiceConnected()会取回一个IBinder引用,而我们通过Stub对象的asInterface()方法,就可以取回一个客户端可用的Proxy实例。这是Android的技巧所在,通过onServiceConnected()返回的,只是一个IBinder引用,在进程空间不会存在具体的对象,因为通过一个接口类ITaskService是无法得到具体的对象的,于是通过这个asInterface()的所谓类型转换,实质却是通过这次调用创建了一个Proxy对象。于是客户端有了Proxy对象,向Service端的Stub端对象发送命令,这样RPC交互便建立起来了。
- 在建立起与Stub对象通信的过程前,本地IInterface为空引用,于是创建一个Stub.Proxy对象。在后面的Stub.Proxy实现部分,我们可以看到在Stub.Proxy对象被创建后,调用ITaskService的方法,实际上会通过不同的接口方法实现,发送Binder命令到远端。
- 对于Stub端代码的实现,我们前面也分析过,就是通过把IPC消息取出来解析,找到需要执行哪个方法来响应具体的调用请求。在Android环境里,这些操作统一由onTransact()方法来完成。在Java里对于异常的捕捉与处理很重要,而我们所有的远程方法调用,实际都会是在onTransact()作用域里来完成,于是我们在这里抛出RemoteException,远程调用上任何的异常信息都将在这时会集中到一起,通过Binder抛到客户端处理。
- INTERFACE_TRANSACTION,值为1,这是Binder跨进程交互的最基本通信接口,用于查询这一接口是否存活。这一TRANSACTION在处理上就比较简单,只是将自己的DESCRIPTOR写入Binder返回给客户端。
- TRANSACTION_getPid,对于aidl里定义的每个方法,最终都会将当前Binder通信的命令+1,从而可以拓展出新的命令请求,于是这个值在客户端环境和Service端环境都是统一的。在通过Binder接收这样的Binder命令之后,就会调用具体的Stub里实现的方法,比如我们实现的getPid(),然后再将返回值通过Binder传回给客户端。
- 这是IoC设计模式的又一次应用。在Android源代码里,我们经常看到这样成功实施的设计模式反复被使用,简直让人怀疑这整套系统都是由一个人设计实现。在Stub类里,实际上继承了Binder类然后又覆盖掉了onTransact()方法,而在覆盖掉的onTransact()方法里又回调到父类Binder的onTransact()方法,实际上就拓展了Binder的执行能力,但又保持了原有的接口方法。
- 定义客户端调用所需要的Proxy类。Proxy与Stub一样,都继承自ITaskService,于是也会跟Stub通过ITaskService接口类的定义来共享接口方法。
- 在这里,我们就可以看到接口与实现分享的好处了,我们的代码通过IBinder接口来访问某一对象,于是在Service实现里得到的Stub,而在客户端得到的是Stub.Proxy对象。这样的特点在继承于Binder的远程对象里也是如此,Binder对象同时存在客户端的请求代码与Service端的响应代码,而在客户端与Service端都使用IBinder接口来访问Binder时,就可以得到不同的实现。
- 这是我们Proxy部分的代码实现,比如我们例子里定义的是getPid()的接口方法,在这里就会有一个getPid的Proxy接口方法实现。在这一方法里,会通过Binder通信,将TRANSACTION_getPid的命令发送到标识为DESCRIPTOR的响应请求的部分。对应于我们前面描述的onTransact()实现,我们就会知道,后续动作就是触发远程的getPid()被执行到。消息发送会是阻塞操作,当代码得以继续时,远程代码肯定已经执行完成,这时就会通过Binder将远程发过来的返回结果读出来,返回给调用getPid()的部分。当然,远程的onTransact()实际上还有可能通过Binder将RemoteException抛出来,于是我们这里也将读取这些Exception,再转发给上层异常捕捉代码。
- 所有的Binder所能收发的命令,都是按INTERFACE_TRANSACTION + n的方法加入系统里的,这样拓展起来很灵活。由于都是基于同一ITaskService.java来提供这些命令定义,于是客户端与Service端是共享这些命令定义的。
总而言之,这些代码,就将客户端与Service端的代码,分别通过Stub与Stub.Proxy两个类来创建,通过这两个对象的引入,无论是调用RPC,还是提供RPC实现,都变得只是拓展一下原有的基本实现即可。这时就基本上达到我们前面描述过的基于Binder进行RPC通信的需求:

而在远程交互的实现上,我们基于AIDL的Remote Service,就会以如下的形式进行交互:

在编译阶段,idl文件里定义的接口会通过aidl工具翻译得到一个ITaskService.java文件,保存到gen供应用程序引用。这一ITaskService.java文件里会具体实现发送请求的Proxy接口类与提供实现并将执行结果返回的Stub接口类。在发生aidl调用时:
- 客户端调用bindService(),以某个Intent作为参数。这一Intent里会通过Action将请求发送到Service实现,于是触发Service实现的onBind()回调。
- Service里实现onBind()会返回一个IBinder引用,通过触发客户端的onServiceConnected()回调方法,传递给客户端。实际上,在建立Binder通信之前的这些跨进程通信都是由ActivityManager来完成的,并不是直接跟Binder打交道,而是由Intent来触发。
- 取回IBinder引用之后,通过ITaskService.Stub.asInterface()方法,这一Binder会被转换成Proxy对象。当然,我们从底层已经看到,这个所谓的转换,实质上是创建了一个ITaskService.Stub.Proxy对象。
- 当我们需要从客户端进程访问到服务端进程时,实际上,都是通过已经取得的Stub.Proxy对象里的getPid()方法,将一个执行的请求通过Binder发送给Service里实现的Stub对象。
- Stub对象通过自己的onTransact()方法,读取发送到自己进程的Binder命令,根据不同Binder命令执行不同的远程方法,然后将执行完的结果通过Binder返回给客户端。
当然,此时我们得到了基本的跨进程调用方法的能力,这跟我们普通的编程模型一致了,像我们的一般的编程,都是从一个main()函数开始,调用不同的代码逻辑,最终得到一个大的复杂的可执行程序。但这并非全部,在现实的编程环境里,我们还需要实现一些回调式的编程,主要用于一些直接调用不太合适的情境。比如我们需要在后台做某些比较耗时的操作,像下载、登录等,如果直接调用再取返回值,此时,我们得到的结果就很悲惨,会需要等待函数执行完成之后才能继续执行,需要等待很长时间。在Android的单线程编程模型里,这种情况会更严重,我们Activity运行在主线程里,如果通过aidl调用到一个耗时操作,就会阻塞到主线程的执行,从而产生ANR错误。
这种方式实现的,只是单向调用,虽然我们也可以在发起调用的部分取得返回值,但只是一种单向的函数式调用。如果我们需要实现双向调用怎么做呢?我们不光会调用到远程代码里,也可以提供一种回调接口,让被调用方回调回来,就像是C语言里的回调函数,这样,远程调用的世界就完整了,见后续内容。
RPC,以及为什么需要这么复杂的处理
我们可以先来了解一下RPC的实现。
跨进程访问,实际上并非Android环境才需要,这是所有跨进程软件设计里的必须项。这种交互性的跨进程需求,跟我们传统的C/S(客户端/服务器)构架类似,客户端使用IPC访问服务,而服务器端则实现具体的代码逻辑,通过IPC提供服务。如下所示

进程1提供客户端功能,而进程2提供服务器功能,在进程1里调用RPCFunc(1,2),实际上会触发到进程2里的RPCFunc1Impl1(1,2)的执行。
- 需要通过IPC机制在底层把这样的访问实现出来,这样在客户端进程空间里可以找到RPCFunc1Stub()的定义,用于将函数调用解析为基于IPC的请求消息
- 在RPCFunc1Stub()实现里,会将访问请求转义成具体的进程间通信的消息,再发送出去
- 服务器端则会RPCFunc1Skel()来监听所有的请求,然后再具体调用请求转发到自己实现的RPCFunc1Impl()
- 当RPCFunc1Impl()执行完成之后,反将结果返回到RPCFuncSkel()
- 返回的值则会再次经由进程间通信,再传回给客户端
- 然后在客户端RPCFunc1()的return语言里返回
这样,从进程1的代码上来看,好像是完成了一次从RPCFunc1()到RPCFunc1Impl()的远程过程调用(RPC),但在内容实现上,则是经历了1-6这样6个步骤的串行操作。之说以说是串行,因为这6个步骤会顺序进行,进程1的执行RPCFunc1()这一函数时,直到第6步执行完成之前,都会被阻塞住。
通过通过串行实现后的这种特殊C/S框架,因为跟我们传递的函数调用类似,只是提供了跨进程的函数调用,于是根据这样的行为特征,我们一般会叫它们为远程过程调用(Remote Procedure Call,简称RPC)。支撑起RPC环境的是IPC通信机制,我们也知道套接字(Socket)也是IPC机制一种,而TCP/IP是Socket机制的一部分,于是很自然的,RPC也天生具备跨网络的能力,在实际的部署里,RPC一般会是网络透明的,通过RPC来进行访问的那端,并不会知道具体实现RPC的会是本地资源或是网络上的资源。RPC是实现复杂功能的基础,特别是一些分布式系统设计里,比如我们Linux环境里的网络文件系统NFS、AFS等,都是基于RPC,还有更高级一点,像我们的Corba环境、J2EE环境和WebService,都会使用RPC的变种。
拥有了RPC通信能力之后,我们在编程上的局限性便大为减小,我们的代码可以很灵活地通过多进程的方式进行更安全的重构,而且还可以进行伸缩度非常良好的部署。这点对于Android来说,尤为重要,因为我们的Android系统就是构建在基于多进程的“沙盒”模型之上的。在Android环境里,不存在基于网络来进行RPC的需求,而是使用高性能的面向对象式的Binder,于是,我们的RPC,需要通过RPC来构建。于是,简单的RPC通信流程,在Android系统里,则可以通过IBinder对象引用来完成,得到如下的实现逻辑:

我们会通过IBinder,来实现从一个进程来访问另一个进程的对象,得到远程对象的引用之后,虽然在进程1里我们像是真正通过这一IBinder来访问远程对象的某些方法,比如doXXX()方法,但实际上后续的执行逻辑则会被转到Binder IPC来发送访问进程,进程1在进入doXXX()方法之后,就会进入IBinder是否有返回的检测循环。当然此时由于IBinder设计上的精巧性,此时进程实际上会休眠到/dev/binder设备的休眠队列里。而提供RPC的进程2则相反,它启动后会一直在IPC请求上进行循环监听,当有IPC请求过来之后,则会将doXXX()的访问请求解析出来,访问这一方法,在访问完成之后,再将调用doXXX()的结果通过IBinder返回给发出调用请求的进程1。这时,会唤醒进程1继续往下执行,从IPC上取回调用的返回值,然后再执行doXXX()之后的代码。
通过这种RPC机制,在Android系统里,就可以更灵活地来设计交互过程,更方便地在多进程环境里进行低耦合化设计。在RPC交互的Server端的实现,可以灵活地根据自己的实现或是调用上的需求,开放出来一部分的自己实现的接口,从而给多个Client端提供服务。
由于Binder能够支持RPC,则基于代码有可能会变得异常复杂,于是,在实际的编程过程里,我们也还需要其他的辅助手段。比如,在实际的实现里,我们都会存在大量的RPC访问:

在这种大量的RPC实现里,会有大量地处理RPC调用的重复代码,比如RPC的发送部分,Server端实现的IPC解析与分发部分。这些重复代码是没有意义的,而且在实际过程里,这种重复代码也将会是错误的源头。想像一下,如果上图所描述的RPC有100个,此时,我们将需要实现一个多大的switch()跳转。还有一个设计上的问题,当然我们使用固化的switch()来处理这种大量分支跳转,则我们的代码在设计上会被固化,我们不能灵活地重构我们的代码。
于是,我们在实现Service时,我们先会使用Proxy模式来进行重构。标准的Proxy模式构成如下:
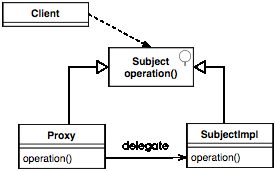
对于同一Subject接口类,会被拆分成Proxy与具体实现的SubjectImpl类,方法的实现在SubjectImpl类里完成,而Proxy类所实现的则是将某些方法调用转发到SubjectImpl类。当客户端通过统一的Subject对象进行访问时,实际上是通过Proxy类来完成这转发。这样,接口访问与接口的实现则会隔离开,只通过基本的接口类Subject进行交互,从而降低了设计上的耦合性。
在Android的跨进程调用里使用Proxy模式,则得到如下的示意图:

Android里使用的Proxy模式,也是通过一个接口类IInterface派出来具体一个Proxy类和一个Stub类,由Proxy来提供访问接口的解析能力,而具体实现由Stub类来提供。于是,我们可以不再使用底层的IBinder来访问远程对象Service,而是通过一个抽象的接口类IInterface来进行访问。对应于每个IInterface抽象类,会派生出两个不同类,BpXXX和Stub,BpXXX用来提供Proxy功能,Stub类来提供具体实现。BpXXX,它的命名是Binder + Proxy + XXX的简写,XXX是指代具体的Service名字,比如Battery。通过这种模式重构成出来的实现就会将我们的接口的访问与实现完成的抽离开来,我们的应用程序进程里会各有一个BpXXX对象,而服务器里会有一个Stub对象,BpXXX与Stub通过IInterface来统一所能进行交互的接口方法,在应用程序里通过一个BpXXX,则可以访问到Service里实现的Stub对象的方法。于是,我们的服务器则只需要专注于方法的提供,通过继承Stub对象,然后实现IInterface接口类里定义的方法。
我们可以注意到,实际上,IInterface<XXX>接口、BpXXX与Stub,这三者在我们图中是被一个Framework的范围之内,当然最好这部分通过Proxy设计模式重构过的访问模式之后,重复性的代码都可以被通用化的代码实现,以减小工作。但这不现实,我们无法预测出某个被RPC化的对象会提供哪些方法,我们在系统里唯一可能比较明确的部分是IInterface这样的接口。这时,如果我们使用某种特殊工具,将IInterface对于接口访问方法(客户端与服务器所统一出来的远程调用方法)使用某种中间语言描述出来,这时,我们就可以得到我们想要减小重复代码的目的了,这样的工具就是IDL,在Android里被进一步简化成了Android版的 IDL,于是被称为AIDL。
IDL,全称是接口定义语言(Interface Definition Language),也是通过制定UML规范的OMG组织提出的交互的接口规范。IDL,是把RPC调用的实现,通过一种抽象的接口语言IDL定义出来,从面可以实现跨平台、跨语言、跨网络的调用环境。既然这种IDL语言只是一种规范,于是针对不同软件开发框架会提供不同的IDL解析工具,就好像HTML是一种规范,而浏览器与HTTP服务器可以有各种不同实现一样。几乎每种开发环境,都会构建出自己的一套IDL工具,从而实现不一样的交互性开发需求。比如我们最常用的可能会是Windows上的COM/DCOM接口,专用于Windows平台里的跨进程跨网络环境的开发;而像Mozilla或是OpenOffice这样软件环境里的IDL支持,IDL存在的意义更多地则是着眼于多语言支持,可以实现更加方便的插件开发,虽然也提供跨进程支持,但不是重点,更加不支持网络。最强大的IDL的应用环境CORBA(通用对象请求代理框架,Common Object Request Broker Architecture)则着眼于完整的跨平台计算环境的提供,从而支持多语言多平台跨网络,可以将异构型计算环境合并成统一计算环境,Java EE也会使用CORBA作为其网络交互的底层机制。
这些不同IDL工具所能起到的作用倒是很类似的,就是将标准的IDL语言,转化成自己平台开发语言的基类实现,然后再由调用端和实现端分别实现具体的接口。比如我们前面举的RPC的例子,如果使用IDL的C语言绑定,则会像是下面的这个样子:
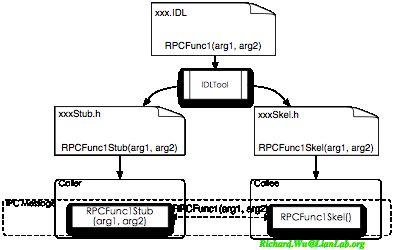
IDL文件里定义接口方法,xxx.idl文件里会定义接口RPCFunc1。而IDL通过特定IDL工具翻译之后,会生成针对客户端的xxxStub.h,和针对服务器端的xxxSkel.h,然后我们可以通过这两个头文件,会定义其具体所要求的客户端的RPCFunc1Stub()的实现和服务器端的RPCFunc1Skel()实现。实现完成的结果就是我们会得一个基于IPC的跨进程调用RPCFunc1(arg1,arg2)。当然,如果是有多语言支持,这时我们还会生成不同语言支持下的版本,比如在面向对象的语言环境里会生成xxxStub和xxxSkel基类,我们可以继承基类,然后再改写这特定的方法。
如果是在跨语言支持、跨网络、跨平台的环境里,IDL生成的客户端与服务器端实现还是会由于复杂的应用程序情境而需要我们自已在具体实现里进行定制,比如处理面向对象与面向过程之间、网络与单机环境之间、操作系统之间、大小端等诸多方面的差异性。而我们的Android则要简单得多,我们对于IDL的需求仅只是解决跨进程调用时的问题,只需要支持Java语言的绑定,只需要在Android环境里运行,只需要单机环境支持。于是,IDL本身,可以被大幅度简化,于是便有AIDL。
AIDL就是Android里的IDL,只提供Java环境支持,只针对Android环境,只应用于单机环境。引入了AIDL之后的Proxy模型,则几乎可以开始进行“傻瓜”式的RPC编程了。AIDL的作用如下图所示:
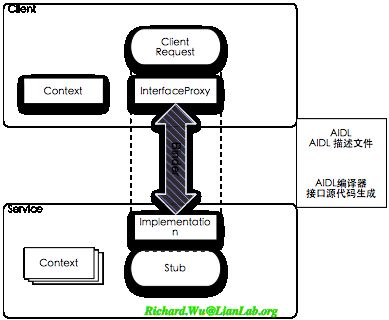
针对于前面看到的Interface、Proxy、Stub三个类的代码重复问题,在AIDL里得到了很好的解决方案,有了AIDL之后,这三个类的定义是由AIDL工具转义自动生成的代码。我们在系统里会有.aidl文件,这是一种简化过的面向Java的IDL文件,在这一文件里定义调用方与被调用方所统一使用的接口方法。AIDL文件会通过AIDL编译工具编译成Interface、Proxy、Stub三个基类的定义,当然这三个类在Binder环境里会是,IInterface<XXX>,BpXXX,与XXX.Stub,这些是自动生成的,不需要修改。应用程序这端会通过Interface定义,直接访问远端的Stub,但实际上底层会通过BpXXX这个Proxy类来完成转发。而我们实现的部分,只需要在Service类里继承并实现Stub类的拓展接口即可。于是,我们便可以很方便地基于Binder得到了RPC的多进程交互的能力。
通过AIDL来编跨进程的Remote Service,是Android里提供的一种功能强大,但编写简单的一种编程模型。我们需要通过Java编程,透过Binder IPC来给系统里的其他部分,或是应用程序共享某些功能接口时,必须通过AIDL来进行编程。所以AIDL不光是对于应用程序的编程很重要,对于Android系统层开发也很重要,而AIDL在编程上并没有带来很大的开销,并不是特别复杂。我们先来看一下Android里的AIDL编程。
AIDL的语法
AIDL的语法其实很简单,基本上我们可以把它看成Java语言里一种类似于C头文件的格式,它只包括方法的定义,但不包含实现。它大部分是定义一个或者多个的接口方法,通过对这些接口方法的抽象定义,会定义方法的参数列表与返回值。这种定义方法的AIDL是AIDL解析时的入口,但为了支持数据类型的拓展,它还支持通过Parcelable接口类来拓展数据类型的支持。这是因为AIDL在语法上仅支持Java的基本数据类型和一些Android环境里的基本类,这样可以使用AIDL整个环境的实现和自动生成的代码都可以变得简单,AIDL不直接支持的数据类型,则需要通过引用其他的AIDL定义来导入进来。
AIDL支持数据类型:
- Java的基本数据类型(元数据类型,Primitive JavaProgramming Language Types),像int, boolean等。
- 以下几种基本类:
- String
- List
- Map
- CharSequences
- 通过AIDL导入其他AIDL文件里定义的内容,一般用于导入其他的接口类
- 通过AIDL导入的其他Parcelable的接口类,用于导入AIDL所不能支持的数据类型
- AIDL只能用于定义方法,不能用于定义类结构,虽然也会导入Parcelable接口定义,但Parcelable只是描述存在某个类,并不会描述类的结构
- AIDL在参数上会使用in, out, inout三种描述符,主要是用于通过Binder传递时指定单向入,单向出,和双向传递。我们可以从后面的Parcel看到,在跨进程间传递数据还是有开销的,通过这种指定方式可以有更高效率。比如in、out会指定只在收发两端进行一次复制,inout则需要进行双向复制,从客户端复制到服务端,然后在调用完成后再从服务端发送回客户端。我们可以根据参数用途进行具体指定,如果不加指定,参数默认为in类型。
有了这样数据类型支持之后,实际上AIDL,可以应用于几乎任何情境。我们定义一个AIDL文件时,可以通过在Eclipse的应用程序工程里加入.aidl文件,将这一文件放在src/包名/的目录下,这样ADT工具会自动使用AIDL工具来编译这一文件,也可以手工添加这样的文件,然后使用Android.mk文件指定AIDL工作来进行编译。最后AIDL都会将编译结果放在gen目录里(跟R.java的保存位置一样)。
定义一个AIDL文件很简单,基本上可以认为是把Java定义里的属性与实现部分去掉,把得到的文件命名为.aidl即可。出于命名的规范性,一般我们把要需要抛出接口的类定义之前加大写的I(Interface的首字母),比如我们希望声明一个远程接口类TaskService,我们一般会定义一个叫ITaskService.aidl的文件。当然,既然aidl作用于Java,于是我们也需要指定包名,以限定该接口类的域名空间,这时跟Java语言一致,使用package加包名。
packageorg.lianlab.service
然后在这一行之后,通过一个interface定义我们需要抛出来的接口类,这一般会与我们.aidl文件名是一致的,比如我们前面的ITaskService.aidl,则我们会使用interface ITaskService{},然后再在ITaskService的作用域内,定义我们需要使用的方法。最后我们得到的.aidl文件,大概会是这个样子:
- packageorg.lianlab.service;
- interfaceITaskService {
- int getPid ( );
- }
是不是很简单?其实对应于Java实现,因为aidl文件里只是定义接口类里的方法,于是不需要额外的引用,所以内容会很简单。因为我们现在需要的这两个远程接口方法,都只使用最基本的数据类型,如果是需要使用aidl支持的数据类型以外的类,则我们还会需要引用其他的aidl文件,将这些新的数据定义导入我们当前的aidl定义,这时我们会使用import语句来导入这样的aidl定义。
所以综合一下,AIDL基本语法便是由package、import、interface这样格式构成,然后再在interface里定义所需要使用的方法。使用import来引用各个aidl文件里定义的接口类,则避免了接口类的重复定义,而通过import引用Parcelable接口类,则使AIDL能够很灵活方便地传递复杂数据结构。唯一需要注意的是,AIDL的解析工具在实现上很简单,并没有复杂的容错性检查,在编写AIDL时我们需要注意格式问题,比如intgetPid(void);则是不对的格式。
稍后来看到,我们怎么样针对这么简单几行的AIDL文件编写一个Remote Service,提供这个特殊的getPid()远程调用。