Java垃圾回收机制1
理解java垃圾回收机制有什么好处呢?作为一个软件工程师,满足自己的好奇心将是一个很好的理由,不过更重要的是,理解GC工作机制可以帮助你写出更好的Java应用程序。
这是我个人的主观观点,但我相信一个人精通了GC,往往会是一个更好的Java程序员。如果你对GC感兴趣,那就意味着你有一定大规模应用开发的经验。如果你已经仔细过考虑选择合适的GC算法,这意味着你完全理解你开发的应用程序的功能。当然,这可能不是一个优秀开发者共同标准。然而,很少有人会反对我说的:理解GC是成为一个伟大的Java开发人员的要求。
这是“成为一个Java GC专家”系列文章的第一部分。这次我将讲述GC简介,而在下一篇文章中,我将讨论分析GC状态和来自NHN的GC调优的例子。
本文的目的是用简单的方式向你介绍GC。我希望这篇文章被证明是非常有帮助的。事实上,我的同事已经发表了一些关于Java内部机制的大文章,它们已经在推特变得很流行。你可以去看看。
回到垃圾收集器,在学习GC前,你应该知道一个技术名词:这个词是“stop-the-world。“ 无论你选择哪种GC算法,Stop-the-world都会发生。Stop-the-world意味着JVM停止应用程序,而去进行垃圾回收。当stop-the-world发生时,除了进行垃圾回收的线程,其他所有线程都将停止运行。被中断的任务将在GC任务完成后恢复执行。GC调优往往意味着减少stop-the-world的时间。
分代垃圾收集
在Java代码中,Java语言没有显式的提供分配内存和删除内存的方法。一些开发人员将引用对象设置为null或者调用System.gc()来释放内存。将引用对象设置为null没有什么大问题,但是调用system.gc()方法会大大的影响系统性能,绝对不能这个干。(谢天谢地,我还没看到任何NHN开发者调用这个方法。)
在Java中,由于开发人员没有在代码中显式删除内存,所以垃圾收集器会去发现不需要(垃圾)的对象,然后删除它们,释放内存。这款垃圾收集器是基于以下两个假设而创建的。(称他们为前提条件更好,而不是假设。)
- 绝大多数对象在短时间内变得不可达
- 只有少量年老对象引用年轻对象.
这些假设被称为“弱代假说”。为了发挥这一假设的优势,在HotSpot虚拟机中,物理的将内存分为两个—年轻代(young generation)和老年代(old generation)。
年轻代:新创建的对象都存放在这里。因为大多数对象很快变得不可达,所以大多数对象在年轻代中创建,然后消失。当对象从这块内存区域消失时,我们说发生了一次“minor GC”。
老年代:没有变得不可达,存活下来的年轻代对象被复制到这里。这块内存区域一般大于年轻代。因为它更大的规模,GC发生的次数比在年轻代的少。对象从老年代消失时,我们说“major GC”(或“full GC”)发生了。
我们看一下这幅图。
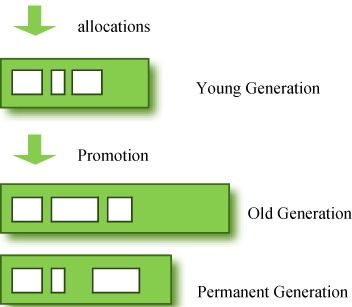
图 1: GC区 & 数据流
上图中的永久代(permanent generation)也称为“方法区(method area)”,他存储class对象和字符串常量。所以这块内存区域绝对不是永久的存放从老年代存活下来的对象的。在这块内存中有可能发生垃圾回收。发生在这里垃圾回收也被称为major GC。
一些人可能想知道:
一个老年代的对象需要引用年轻代的对象,该怎么办?
为了解决这些问题,老年代中有一个被称为“卡表(card table)”的东西,它是一个512 byte大小的块。每当老年代的对象引用年轻代对象时,这种引用会被记录在这张表格中。当垃圾回收发生在年轻代时,只需对这张表进行搜索以确定是否需要进行垃圾回收,而不是检查老年代中的所有对象引用。这张表格用一个叫做“写闸(write barrier)”的东西进行管理。“写闸”是一种装置,对minor GC有更好性能。虽然因为这种机制,会产生一些时间性能开销,但降低了整体的GC时间。
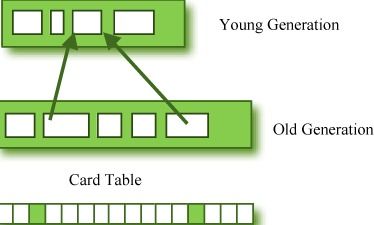
图2: Card Table结构
年轻代组成部分
为了理解GC,我们学习一下年轻代,对象第一次创建发生在这块内存区域。年轻代分为3块。
- Eden区
- 2个Survivor区
年轻代总共有3块空间,其中2块为Survivor区。各个空间的执行顺序如下:
- 绝大多数新创建的对象分配在Eden区。
- 在Eden区发生一次GC后,存活的对象移到其中一个Survivor区。
- 在Eden区发生一次GC后,对象是存放到Survivor区,这个Survivor区已经存在其他存活的对象。
- 一旦一个Survivor区已满,存活的对象移动到另外一个Survivor区。然后之前那个空间已满Survivor区将置为空,没有任何数据。
- 经过重复多次这样的步骤后依旧存活的对象将被移到老年代。
通过检查这些步骤,如你看到的样子,其中一个Survivor区必须保持空。如果数据存在于两个Survivor区,或两个都没使用,你可以将这个情况作为系统错误的一个标志。
经过多次minor GC,数据被转移到老年代过程如下面的图表所示:
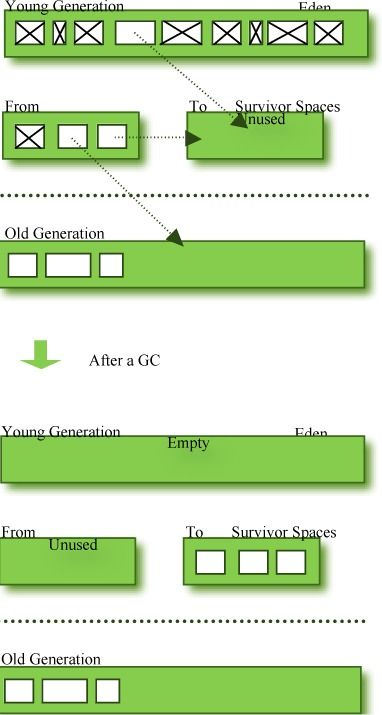
图3: GC前和GC后
请注意,在HotSpot虚拟机中,使用两种技术加快内存的分配。一个被称为“指针碰撞(bump-the-pointer)”,另外一个被称为“TLABs(线程本地分配缓冲)”。
指针碰撞技术跟踪分配给Eden区上最新的对象。该对象将位于Eden 区的顶部。如果之后有一个对象被创建,只需检查Eden区是否有足够大的空间存放该对象。如果空间够用,它将被放置在Eden区,存放在空间的顶部。因此,在创建新对象时,只需检查最后被添加对象,看是否还有更多的内存空间允许分配。然而,如果考虑多线程的环境,则是另外一种情况。为了实现多线程环境下,在Eden 区线程安全的去创建保存对象,那么必须加锁,因此性能会下降。在HotSpot虚拟机中TLABs能够解决这一问题。它允许每个线程在Eden区有自己的一小块私有空间。因为每一个线程只能访问自己的TLAB,所以在这个区域甚至可以使用无锁的指针碰撞技术进行内存分配。
我们已经对年轻代有了一个快速的浏览。你不需要要记住我刚才提到的两种技术。即便你不知道他们,也不会怎么样。但请务必记住:对象第一次被创建发生在Eden区,长期存活的对象被移动到老年代的Survivor区。
老年代GC
当老年代数据满时,基本上会执行一次GC。执行程序根据不同GC类型而变化,所以如果你知道不同类型的垃圾收集器,会更容易理解垃圾回收过程。
在JDK7中,有5种垃圾收集器:
- Serial收集器
- Parallel收集器
- Parallel Old收集器 (Parallel Compacting GC)收集器
- Concurrent Mark & Sweep GC (or “CMS”)收集器
- Garbage First (G1) 收集器
其中,serial 收集器一定不能用于服务器端。这个收集器类型仅应用于单核CPU桌面电脑。使用serial收集器会显着降低应用程序的性能。
现在让我们来了解每个收集器类型。
Serial 收集器 (-XX:+UseSerialGC)
我们在前一段的解释了在年轻代发生的垃圾回收算法类型。在老年代的GC使用算法被称为“标记-清除-整理”。
- 该算法的第一步是在老年代标记存活的对象。
- 从头开始检查堆内存空间,并且只留下依然幸存的对象(清除)。
- 最后一步,从头开始,顺序地填满堆内存空间,将存活的对象连续存放在一起,这样堆分成两部分:一边有存放的对象,一边没有对象(整理)。
serial收集器应用于小的存储器和少量的CPU。
Parallel收集器(-XX:+UseParallelGC)
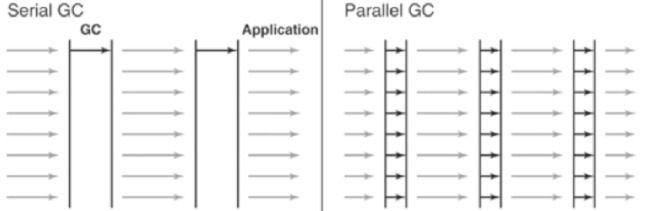
图4: Serial收集器 和 Parallel收集器的差异
从这幅图中,你可以很容易看到Serial收集器 和 Parallel收集器的差异。serial收集器只使用一个线程来处理的GC,而parallel收集器使用多线程并行处理GC,因此更快。当有足够大的内存和大量芯数时,parallel收集器是有用的。它也被称为“吞吐量优先垃圾收集器。”
Parallel Old 垃圾收集器(-XX:+UseParallelOldGC)
Parallel Old收集器是自JDK 5开始支持的。相比于parallel收集器,他们的唯一区别就是在老年代所执行的GC算法的不同。它执行三个步骤:标记-汇总-压缩(mark – summary – compaction)。汇总步骤与清理的不同之处在于,其将依然幸存的对象分发到GC预先处理好的不同区域,算法相对清理来说略微复杂一点。
CMS GC (-XX:+UseConcMarkSweepGC)
图5: Serial GC & CMS GC
CMS垃圾收集器(-XX:+UseConcMarkSweepGC)
如你在上图看到的那样, CMS垃圾收集器比之前我解释的各种算法都要复杂很多。初始标记(initial mark) 比较简单。这一步骤只是查找距离类加载器最近的幸存对象。所以停顿时间非常短。之后的并发标记步骤,所有被幸存对象引用的对象会被确认是否已经被追踪检查。这一步的不同之处在于,在标记的过程中,其他的线程依然在执行。在重新标记步骤会修正那些在并发标记步骤中,因新增或者删除对象而导致变动的那部分标记记录。最后,在并发清除步骤,垃圾收集器执行。垃圾收集器进行垃圾收集时,其他线程的依旧在工作。一旦采取了这种GC类型,由于垃圾回收导致的停顿时间会极其短暂。CMS 收集器也被称为低延迟垃圾收集器。它经常被用在那些对于响应时间要求十分苛刻的应用上。
当然,这种GC类型在拥有stop-the-world时间很短的优点的同时,也有如下缺点:
- 它会比其他GC类型占用更多的内存和CPU
- 默认情况下不支持压缩步骤
在使用这个GC类型之前你需要慎重考虑。如果因为内存碎片过多而导致压缩任务不得不执行,那么stop-the-world的时间要比其他任何GC类型都长,你需要考虑压缩任务的发生频率以及执行时间。
G1 GC
最后,我们来学习一下G1类型。

图6: Layout of G1 GC
如果你想要理解G1收集器,首先你要忘记你所理解的新生代和老年代。正如你在上图所看到的,每个对象被分配到不同的网格中,随后执行垃圾回收。当一个区域填满之后,对象被转移到另一个区域,并再执行一次垃圾回收。在这种垃圾回收算法中,不再有从新生代移动到老年代的三部曲。这个类型的垃圾收集算法是为了替代CMS 收集器而被创建的,因为CMS 收集器在长时间持续运行时会产生很多问题。
G1最大的好处是他的性能,他比我们在上面讨论过的任何一种GC都要快。但是在JDK 6中,他还只是一个早期试用版本。在JDK7之后才由官方正式发布。就我个人看来,NHN在将JDK 7正式投入商用之前需要很长的一段测试期(至少一年)。因此你可能需要再等一段时间。并且,我也听过几次使用了JDK 6中的G1而导致Java虚拟机宕机的事件。请耐心的等待它更稳定吧。