函数调用和尾递归的一点认识
函数调用
在大多数支持块结构的程序设计语言都支持函数或者子程序(函数和子程序的区别在于函数有返回值而子程序没有,在这里我们不区分这两个概念)。在进行函数调用和从函数返回时通常由一个被称为控制栈的运行时刻栈进行管理。每一个活跃的函数在控制栈中都会有一个相对应的活动记录,有时也称为栈帧。活动记录存储着函数调用时传递的参数信息和从函数返回时返回值与控制跳转的信息。
函数的活动记录需要包括下面的信息
- 控制链(control link):指向控制栈中前一个活动记录的指针;
- 访问链(access link):指向源程序中最近的外层块对应的活动记录,用于维护静态作用域(本文中不讨论);
- 返回地址:函数调用结束后被执行的第一条指令地址(本文讨论中将忽略);
- 返回结果地址:存放函数返回值位置的地址;
- 实际参数:函数调用时传递的参数值;
- 局部变量:函数体中声明的局部变量;
- 临时存储区:在函数执行过程中产生的临时结果。
不同语言的不同实现中对上述信息的存放顺序和存放方式可能不一样。在这里我们按照上面说明的顺序来进行讨论。
每当一个函数被调用时,就创建一个相对应的活动记录,并压入控制栈中;而当从一个函数调用结束时,在控制栈中与该函数对应的活动记录(即栈顶的活动记录)就会被弹出控制栈。每个函数所对应的活动记录的大小是不一致的,而堆栈寄存器每次记录的都只是栈顶的活动记录,所以在每个活动记录中需要一个控制链来记录前一个活动记录。
下面我们通过一个例子来简单演示一下函数的活动记录如何被压栈和弹出栈的。
1 int fact (int n) 2 { 3 if (n == 1) { 4 return 1; 5 }else { 6 return n * fact(n – 1); 7 } 8 }
上面是计算一个正整数的阶乘的C语言代码。现在设想要计算表达式fact(3),导致对fact函数的一次调用,则此时将函数调用fact(3)的活动记录压入控制栈中。该活动记录如图1所示,其中
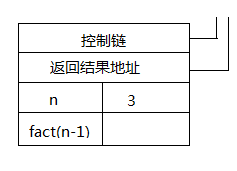
图1
- 控制链,指向执行函数调用fact(3)之前栈顶的活动记录;
- 返回结果地址,指向用于存储函数调用fact(3)的结果的位置;
- 实际参数3;
- 一块临时区域,用于存放n>0时表达式fact(n-1)的中间结果。
当这个活动记录进入栈中之后,计算阶乘的代码开始运行。因为n>0,所以会递归调用fact(2),然后递归调用fact(1)。因此会产生一系列的活动记录,如图2所示。
图 2
在这里,返回值地址指针指向上层活动记录中分配的位置,这样当从fact(1)返回时,返回值会被存储在fact(2)的活动记录中,fact(2)会将该返回值与2相乘返回给fact(3)。
尾递归
尾递归就是在函数调用之后再没有其他计算的递归调用。尾递归调用的返回值可以直接当作包含该尾递归调用的函数的返回值。设想函数f和函数g,f和g可能是不同的函数,也可能是相同的函数。如果函数g调用函数f,并且g不作任何修改直接返回f的返回值,则称g对f的调用是尾递归调用。
典型的尾递归调用的例子是,求两个正整数的最大公约数的欧几里得算法,下面是该算法的一个Scheme语言实现:
1 (define (gcd a b) 2 (if (= b 0) 3 a 4 (gcd b (remainder a b))))
其中,函数remainder是计算其第一个参数除于第二个参数所得到的余数。
前面我们给出的那个计算阶乘的C语言函数则不是一个尾递归调用,因为在递归调用fact(n-1)的返回值还需要乘以n来得到函数调用fact(n)的返回值。其实,我们可以写出一个尾递归调用的阶乘函数,如下所示:
1 int fact_tr(int n, int a) 2 { 3 if (n <= 1) { 4 return a; 5 }else { 6 return fact_tr(n-1, n*a); 7 } 8 }
尾递归的好处在于所有的递归调用可以用一个活动记录来表示,这样无论递归调用的深度有多深,其所占用的内存空间就只是常量的,而不会随着递归深度增加而增加。下面我们将基于函数调用fact_tr(3,1)进行分析,如图3所示是在采用常规活动记录处理方式时,函数调用fact_tr(3,1)运行时某一时刻控制栈的一部分内容:这三个活动记录从上到下分别是函数调用fact_tr(3,1)、fact_tr(2,3)和fact_tr(1,6)的活动记录。
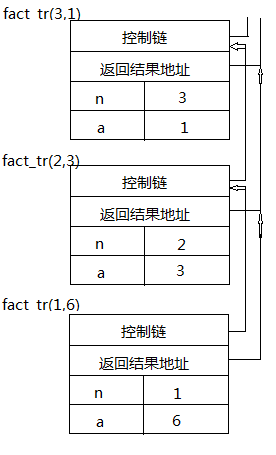
图 3
可见当函数调用fact_tr(1.6)将结果6返回给函数调用fact_tr(2,3),然后fact_tr(2,3)会直接将其返回给fact_tr(3,1),而函数调用fact_tr(3,1)也会将该结果直接返回给前一个活动记录。所以,函数调用fact_tr(1,6)可以跳过fact_tr(2,3)和fact_tr(3,1)的活动记录直接将结果返回。也就是说,此时函数调用fact_tr(2,3)和函数调用fact_tr(3,1)的活动记录没有起作用。实际上,当调用fact_tr(2,3)时,函数调用fact_tr(3,1)的活动记录已经没作用,所以在压入fact_tr(2,3)的活动记录之前,就可将fact_tr(3,1)的活动记录弹出,实际更好的处理是将fact_tr(3,1)的活动记录当作fact_tr(2,3)的活动记录。同理,在调用fact_tr(1,6)时,将fact_tr(2,3)的活动记录当作fact_tr(1,6)的活动记录。
现在很多语言的编译器都采用了一些优化技术,其中包括将尾递归转化为一段循环代码来进行处理,这样就可以避免很多函数调用所消耗的时间和空间,而只是采用修改某些变量的值来实现。例如,在scheme语言的标准中要求scheme的实现必须要支持尾递归机制。
其实,很多非尾递归的函数调用都可以转化为尾递归来实现,不过需要在函数参数传递中添加一些参数来记录某些状态信息,例如上面计算阶乘的非尾递归函数fact转化为尾递归函数fact_tr需要在函数参数中加一个累积器。如果编译器采用了尾递归优化技术,通过这种转化可以在一定程度上实现效率的提升,但同时会增加编程的复杂性而降低程序的易读性。