关于抠图的一些文章方法收集
结合深度场景,提取支撑面,是一个人渐进分割的好办法。既然可以利用深度图,那么便最大化利用深度图像;
分割支撑面以后,可以利用抠图算法,把RGB剩余的像素载进行抠图:《"GrabCut" - Interactive Foreground Extraction using Iterated Graph Cuts》
GrabCut函数说明
void grabCut(InputArray img, InputOutputArray mask, Rect rect, InputOutputArraybgdModel, InputOutputArrayfgdModel, intiterCount, intmode=GC_EVAL)
| Parameters: |
|
|---|
函数原型:
void cv::grabCut( const Mat& img, Mat& mask, Rect rect,
Mat& bgdModel, Mat& fgdModel,
int iterCount, int mode )
其中:
img——待分割的源图像,必须是8位3通道(CV_8UC3)图像,在处理的过程中不会被修改;
mask——掩码图像,如果使用掩码进行初始化,那么mask保存初始化掩码信息;在执行分割的时候,也可以将用户交互所设定的前景与背景保存到mask中,然后再传入grabCut函数;在处理结束之后,mask中会保存结果。mask只能取以下四种值:
GCD_BGD(=0),背景;
GCD_FGD(=1),前景;
GCD_PR_BGD(=2),可能的背景;
GCD_PR_FGD(=3),可能的前景。
如果没有手工标记GCD_BGD或者GCD_FGD,那么结果只会有GCD_PR_BGD或GCD_PR_FGD;
rect——用于限定需要进行分割的图像范围,只有该矩形窗口内的图像部分才被处理;
bgdModel——背景模型,如果为null,函数内部会自动创建一个bgdModel;bgdModel必须是单通道浮点型(CV_32FC1)图像,且行数只能为1,列数只能为13x5;
fgdModel——前景模型,如果为null,函数内部会自动创建一个fgdModel;fgdModel必须是单通道浮点型(CV_32FC1)图像,且行数只能为1,列数只能为13x5;
iterCount——迭代次数,必须大于0;
mode——用于指示grabCut函数进行什么操作,可选的值有:
GC_INIT_WITH_RECT(=0),用矩形窗初始化GrabCut;
GC_INIT_WITH_MASK(=1),用掩码图像初始化GrabCut;
GC_EVAL(=2),执行分割。
源代码包含在:sample/cpp/grabcut.cpp
OpenCV函数库里面包含GrabCut的使用:grabcut主要是通过Min Cut: Global minimal enegry in polynomial time实现,具体参考论文
(1):利用图割法:图像分割之(三)从Graph Cut到Grab Cut:http://blog.csdn.net/zouxy09/article/details/8534954
OpenCV中的GrabCut算法是依据《"GrabCut" - Interactive Foreground Extraction using Iterated Graph Cuts》这篇文章来实现的。该算法利用了图像中的纹理(颜色)信息和边界(反差)信息,只要少量的用户交互操作即可得到比较好的分割结果。那下面我们来了解这个论文的一些细节。另外OpenCV实现的GrabCut的源码解读见下一个博文。接触时间有限,若有错误,还望各位前辈指正,谢谢。
GrabCut是微软研究院的一个课题,主要功能是分割和抠图。个人理解它的卖点在于:
(1)你只需要在目标外面画一个框,把目标框住,它就可以完成良好的分割:

(2)如果增加额外的用户交互(由用户指定一些像素属于目标),那么效果就可以更完美:

(3)它的Border Matting技术会使目标分割边界更加自然和perfect:
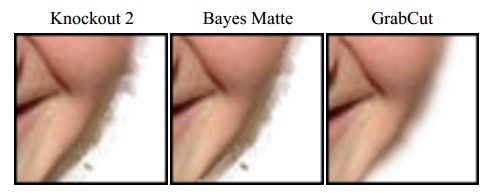
当然了,它也有不完美的地方,一是没有任何一个算法可以放之四海而皆准,它也不例外,如果背景比较复杂或者背景和目标相似度很大,那分割就不太好了;二是速度有点慢。当然了,现在也有不少关于提速的改进。
OK,那看了效果,我们会想,上面这些效果是怎么达到的呢?它和Graph Cut有何不同?
(1)Graph Cut的目标和背景的模型是灰度直方图,Grab Cut取代为RGB三通道的混合高斯模型GMM;
(2)Graph Cut的能量最小化(分割)是一次达到的,而Grab Cut取代为一个不断进行分割估计和模型参数学习的交互迭代过程;
(3)Graph Cut需要用户指定目标和背景的一些种子点,但是Grab Cut只需要提供背景区域的像素集就可以了。也就是说你只需要框选目标,那么在方框外的像素全部当成背景,这时候就可以对GMM进行建模和完成良好的分割了。即Grab Cut允许不完全的标注(incomplete labelling)。
1、颜色模型
我们采用RGB颜色空间,分别用一个K个高斯分量(一取般K=5)的全协方差GMM(混合高斯模型)来对目标和背景进行建模。于是就存在一个额外的向量k = {k1, . . ., kn, . . ., kN},其中kn就是第n个像素对应于哪个高斯分量,kn∈ {1, . . . K}。对于每个像素,要不来自于目标GMM的某个高斯分量,要不就来自于背景GMM的某个高斯分量。
所以用于整个图像的Gibbs能量为(式7):

其中,U就是区域项,和上一文说的一样,你表示一个像素被归类为目标或者背景的惩罚,也就是某个像素属于目标或者背景的概率的负对数。我们知道混合高斯密度模型是如下形式:
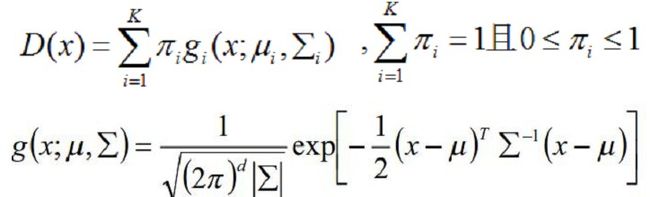
所以取负对数之后就变成式(9)那样的形式了,其中GMM的参数θ就有三个:每一个高斯分量的权重π、每个高斯分量的均值向量u(因为有RGB三个通道,故为三个元素向量)和协方差矩阵∑(因为有RGB三个通道,故为3x3矩阵)。如式(10)。也就是说描述目标的GMM和描述背景的GMM的这三个参数都需要学习确定。一旦确定了这三个参数,那么我们知道一个像素的RGB颜色值之后,就可以代入目标的GMM和背景的GMM,就可以得到该像素分别属于目标和背景的概率了,也就是Gibbs能量的区域能量项就可以确定了,即图的t-link的权值我们就可以求出。那么n-link的权值怎么求呢?也就是边界能量项V怎么求?

边界项和之前说的Graph Cut的差不多,体现邻域像素m和n之间不连续的惩罚,如果两邻域像素差别很小,那么它属于同一个目标或者同一背景的可能性就很大,如果他们的差别很大,那说明这两个像素很有可能处于目标和背景的边缘部分,则被分割开的可能性比较大,所以当两邻域像素差别越大,能量越小。而在RGB空间中,衡量两像素的相似性,我们采用欧式距离(二范数)。这里面的参数β由图像的对比度决定,可以想象,如果图像的对比度较低,也就是说本身有差别的像素m和n,它们的差||zm-zn||还是比较低,那么我们需要乘以一个比较大的β来放大这种差别,而对于对比度高的图像,那么也许本身属于同一目标的像素m和n的差||zm-zn||还是比较高,那么我们就需要乘以一个比较小的β来缩小这种差别,使得V项能在对比度高或者低的情况下都可以正常工作。常数γ为50(经过作者用15张图像训练得到的比较好的值)。OK,那这时候,n-link的权值就可以通过式(11)来确定了,这时候我们想要的图就可以得到了,我们就可以对其进行分割了。
2、迭代能量最小化分割算法
Graph Cut的算法是一次性最小化的,而Grab Cut是迭代最小的,每次迭代过程都使得对目标和背景建模的GMM的参数更优,使得图像分割更优。我们直接通过算法来说明:
2.1、初始化
(1)用户通过直接框选目标来得到一个初始的trimap T,即方框外的像素全部作为背景像素TB,而方框内TU的像素全部作为“可能是目标”的像素。
(2)对TB内的每一像素n,初始化像素n的标签αn=0,即为背景像素;而对TU内的每个像素n,初始化像素n的标签αn=1,即作为“可能是目标”的像素。
(3)经过上面两个步骤,我们就可以分别得到属于目标(αn=1)的一些像素,剩下的为属于背景(αn=0)的像素,这时候,我们就可以通过这个像素来估计目标和背景的GMM了。我们可以通过k-mean算法分别把属于目标和背景的像素聚类为K类,即GMM中的K个高斯模型,这时候GMM中每个高斯模型就具有了一些像素样本集,这时候它的参数均值和协方差就可以通过他们的RGB值估计得到,而该高斯分量的权值可以通过属于该高斯分量的像素个数与总的像素个数的比值来确定。
2.2、迭代最小化
(1)对每个像素分配GMM中的高斯分量(例如像素n是目标像素,那么把像素n的RGB值代入目标GMM中的每一个高斯分量中,概率最大的那个就是最有可能生成n的,也即像素n的第kn个高斯分量):
![]()
(2)对于给定的图像数据Z,学习优化GMM的参数(因为在步骤(1)中我们已经为每个像素归为哪个高斯分量做了归类,那么每个高斯模型就具有了一些像素样本集,这时候它的参数均值和协方差就可以通过这些像素样本的RGB值估计得到,而该高斯分量的权值可以通过属于该高斯分量的像素个数与总的像素个数的比值来确定。):
![]()
(3)分割估计(通过1中分析的Gibbs能量项,建立一个图,并求出权值t-link和n-link,然后通过max flow/min cut算法来进行分割):
![]()
(4)重复步骤(1)到(3),直到收敛。经过(3)的分割后,每个像素属于目标GMM还是背景GMM就变了,所以每个像素的kn就变了,故GMM也变了,所以每次的迭代会交互地优化GMM模型和分割结果。另外,因为步骤(1)到(3)的过程都是能量递减的过程,所以可以保证迭代过程会收敛。
(5)采用border matting对分割的边界进行平滑等等后期处理。
2.3、用户编辑(交互)
(1)编辑:人为地固定一些像素是目标或者背景像素,然后再执行一次2.2中步骤(3);
(2)重操作:重复整个迭代算法。(可选,实际上这里是程序或者软件抠图的撤销作用)
总的来说,其中关键在于目标和背景的概率密度函数模型和图像分割可以交替迭代优化的过程。更多的细节请参考原文。
(2):利用MeanShift算法:
Meanshift简介:http://blog.csdn.net/crzy_sparrow/article/details/7352994
算法介绍:http://blog.csdn.net/carson2005/article/details/7337432
OpenCV里面有了自带的例子,可以直接使用!:http://blog.csdn.net/H349117102/article/details/8964266
No48. meanshift_segmentation.cpp
meanshift图像分割。三个参数spatialRad、colorRad和maxPyrLevel可调。
MeanShift算法详细介绍:http://www.cnblogs.com/liqizhou/archive/2012/05/12/2497220.html
Mean Shift算法,一般是指一个迭代的步骤,即先算出当前点的偏移均值,移动该点到其偏移均值,然后以此为新的起始点,继续移动,直到满足一定的条件结束.
1. Meanshift推导
给定d维空间Rd的n个样本点 ,i=1,…,n,在空间中任选一点x,那么Mean Shift向量的基本形式定义为:

Sk是一个半径为h的高维球区域,满足以下关系的y点的集合,
![]()
k表示在这n个样本点xi中,有k个点落入Sk区域中.
以上是官方的说法,即书上的定义,我的理解就是,在d维空间中,任选一个点,然后以这个点为圆心,h为半径做一个高维球,因为有d维,d可能大于2,所以是高维球。落在这个球内的所有点和圆心都会产生一个向量,向量是以圆心为起点落在球内的点位终点。然后把这些向量都相加。相加的结果就是Meanshift向量。
如图所以。其中黄色箭头就是Mh(meanshift向量)。
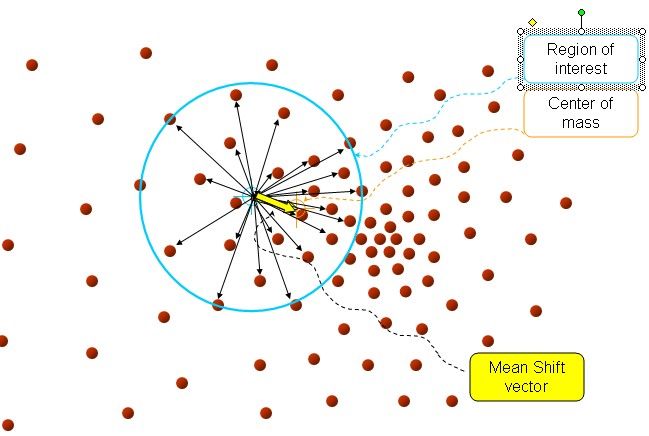
再以meanshift向量的终点为圆心,再做一个高维的球。如下图所以,重复以上步骤,就可得到一个meanshift向量。如此重复下去,meanshift算法可以收敛到概率密度最大得地方。也就是最稠密的地方。
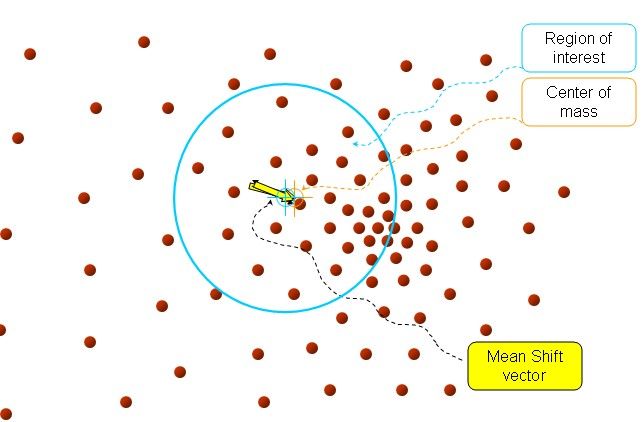
最终的结果如下:

Meanshift推导:
把基本的meanshift向量加入核函数,核函数的性质在这篇博客介绍:http://www.cnblogs.com/liqizhou/archive/2012/05/11/2495788.html
那么,meanshift算法变形为
(1)
解释一下K()核函数,h为半径,Ck,d/nhd 为单位密度,要使得上式f得到最大,最容易想到的就是对上式进行求导,的确meanshift就是对上式进行求导.
(2)
令:

K(x)叫做g(x)的影子核,名字听上去听深奥的,也就是求导的负方向,那么上式可以表示

对于上式,如果才用高斯核,那么,第一项就等于fh,k
第二项就相当于一个meanshift向量的式子:

那么(2)就可以表示为
下图分析![]() 的构成,如图所以,可以很清晰的表达其构成。
的构成,如图所以,可以很清晰的表达其构成。

要使得![]() =0,当且仅当
=0,当且仅当![]() =0,可以得出新的圆心坐标:
=0,可以得出新的圆心坐标:
(3)
上面介绍了meanshift的流程,但是比较散,下面具体给出它的算法流程。
- 选择空间中x为圆心,以h为半径为半径,做一个高维球,落在所有球内的所有点xi
- 计算
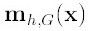 ,如果<ε(人工设定),推出程序。如果>ε, 则利用(3)计算x,返回1.
,如果<ε(人工设定),推出程序。如果>ε, 则利用(3)计算x,返回1.
2.meanshift在图像上的聚类:
真正大牛的人就能创造算法,例如像meanshift,em这个样的算法,这样的创新才能推动整个学科的发展。还有的人就是把算法运用的实际的运用中,推动整个工业进步,也就是技术的进步。下面介绍meashift算法怎样运用到图像上的聚类核跟踪。
一般一个图像就是个矩阵,像素点均匀的分布在图像上,就没有点的稠密性。所以怎样来定义点的概率密度,这才是最关键的。
如果我们就算点x的概率密度,采用的方法如下:以x为圆心,以h为半径。落在球内的点位xi 定义二个模式规则。
(1)x像素点的颜色与xi像素点颜色越相近,我们定义概率密度越高。
(2)离x的位置越近的像素点xi,定义概率密度越高。
所以定义总的概率密度,是二个规则概率密度乘积的结果,可以(4)表示

(4)
其中:![]() 代表空间位置的信息,离远点越近,其值就越大,
代表空间位置的信息,离远点越近,其值就越大,![]() 表示颜色信息,颜色越相似,其值越大。如图左上角图片,按照(4)计算的概率密度如图右上。利用meanshift对其聚类,可得到左下角的图。
表示颜色信息,颜色越相似,其值越大。如图左上角图片,按照(4)计算的概率密度如图右上。利用meanshift对其聚类,可得到左下角的图。
|
|
|
|
|
|




如有问题,可在线讨论。作者:BIGBIGBOAT/Liqizhou