微信公众帐号开发教程第6篇-文本消息的内容长度限制揭秘
相信不少朋友都遇到过这样的问题:当发送的文本消息内容过长时,微信将不做任何响应。那么到底微信允许的文本消息的最大长度是多少呢?我们又该如何计算文本的长度呢?为什么还有些人反应微信好像支持的文本消息最大长度在1300多呢?这篇文章会彻底解除大家的疑问。
接口文档中对消息长度限制为2048
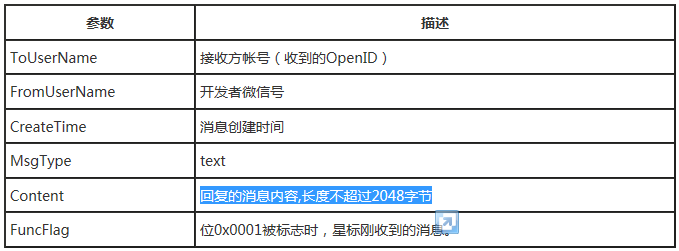
可以看到,接口文档中写的很明确:回复的消息内容长度不超过2048字节。那为什么很多人测试反应消息内容长度在1300多字节时,微信就不响应了呢?我想这问题应该在这部分人没有搞清楚到底该如何计算文本的字节数。
如何正确计算文本所占字节数
计算文本(字符串)所占字节数,大家第一个想到的应该就是String类的getBytes()方法,该方法返回的是字符串对应的字节数组,再计算数组的length就能够得到字符串所占字节数。例如:
- public static void main(String []args) {
- // 运行结果:4
- System.out.println("柳峰".getBytes().length);
- }
1)如果上面的例子运行在默认编码方式为ISO8859-1的操作系统平台上,计算结果是2;
2)如果上面的例子运行在默认编码方式为gb2312或gbk的操作系统平台上,计算结果是4;
3)如果上面的例子运行在默认编码方式为utf-8的操作系统平台上,计算结果是6;
如果真的是这样,是不是意味着String.getBytes()方法在我们的系统平台上默认采用的是gb2312或gbk编码方式呢?我们再来看一个例子:
- public static void main(String []args) throws UnsupportedEncodingException {
- // 运行结果:2
- System.out.println("柳峰".getBytes("ISO8859-1").length);
- // 运行结果:4
- System.out.println("柳峰".getBytes("GB2312").length);
- // 运行结果:4
- System.out.println("柳峰".getBytes("GBK").length);
- // 运行结果:6
- System.out.println("柳峰".getBytes("UTF-8").length);
- }
微信平台采用的编码方式及字符串所占字节数的计算
那么,在向微信服务器返回消息时,该采用什么编码方式呢?当然是UTF-8,因为我们已经在doPost方法里采用了如下代码来避免中文乱码了:
- // 将请求、响应的编码均设置为UTF-8(防止中文乱码)
- request.setCharacterEncoding("UTF-8");
- response.setCharacterEncoding("UTF-8");
- private static String getMsgContent() {
- StringBuffer buffer = new StringBuffer();
- // 每行70个汉字,共682个汉字加1个英文的感叹号
- buffer.append("不知道什么时候开始喜欢这里每个夜里都会来这里看你你长得多么美丽叫我不能不看你看不到你我就迷失了自己好想牵你的手走过风风雨雨有什么困难我都陪你");
- buffer.append("不知道什么时候开始喜欢这里每个夜里都会来这里看你你长得多么美丽叫我不能不看你看不到你我就迷失了自己好想牵你的手走过风风雨雨有什么困难我都陪你");
- buffer.append("不知道什么时候开始喜欢这里每个夜里都会来这里看你你长得多么美丽叫我不能不看你看不到你我就迷失了自己好想牵你的手走过风风雨雨有什么困难我都陪你");
- buffer.append("不知道什么时候开始喜欢这里每个夜里都会来这里看你你长得多么美丽叫我不能不看你看不到你我就迷失了自己好想牵你的手走过风风雨雨有什么困难我都陪你");
- buffer.append("不知道什么时候开始喜欢这里每个夜里都会来这里看你你长得多么美丽叫我不能不看你看不到你我就迷失了自己好想牵你的手走过风风雨雨有什么困难我都陪你");
- buffer.append("不知道什么时候开始喜欢这里每个夜里都会来这里看你你长得多么美丽叫我不能不看你看不到你我就迷失了自己好想牵你的手走过风风雨雨有什么困难我都陪你");
- buffer.append("不知道什么时候开始喜欢这里每个夜里都会来这里看你你长得多么美丽叫我不能不看你看不到你我就迷失了自己好想牵你的手走过风风雨雨有什么困难我都陪你");
- buffer.append("不知道什么时候开始喜欢这里每个夜里都会来这里看你你长得多么美丽叫我不能不看你看不到你我就迷失了自己好想牵你的手走过风风雨雨有什么困难我都陪你");
- buffer.append("不知道什么时候开始喜欢这里每个夜里都会来这里看你你长得多么美丽叫我不能不看你看不到你我就迷失了自己好想牵你的手走过风风雨雨有什么困难我都陪你");
- buffer.append("不知道什么时候开始喜欢这里每个夜里都会来这里看你你长得多么美丽叫我不能不看你看不到你我就迷失了自己好想牵!");
- return buffer.toString();
- }
- public static void main(String []args) throws Exception {
- // 采用gb2312编码方式时占1365个字节
- System.out.println(getMsgContent().getBytes("gb2312").length);
- // 采用utf-8编码方式时占2047个字节
- System.out.println(getMsgContent().getBytes("utf-8").length);
- }
getMsgContent()方法返回的内容正是微信的文本消息最长能够支持的,即采用UTF-8编码方式时,文本消息内容最多支持2047个字节,也就是微信公众平台接口文档里所说的回复的消息内容长度不超过2048字节,即使是等于2048字节也不行,你可以试着将getMsgContent()方法里的内容多加一个英文符号,这个时候微信就不响应了。
同时,我们也发现,如果采用gb2312编码方式来计算getMsgContent()方法返回的文本所占字节数的结果是1365,这就是为什么很多朋友都说微信的文本消息最大长度好像只支持1300多字节,并不是接口文档中所说的2048字节,其实是忽略了编码方式,只是简单的使用了String类的getBytes()方法而不是getBytes("utf-8")方法去计算所占字节数。
Java中utf-8编码方式时所占字节数的计算方法封装
- /**
- * 计算采用utf-8编码方式时字符串所占字节数
- *
- * @param content
- * @return
- */
- public static int getByteSize(String content) {
- int size = 0;
- if (null != content) {
- try {
- // 汉字采用utf-8编码时占3个字节
- size = content.getBytes("utf-8").length;
- } catch (UnsupportedEncodingException e) {
- e.printStackTrace();
- }
- }
- return size;
- }
好了,本章节的内容就讲到这里,我想大家通过这篇文章所学到的应该不仅仅是2047这个数字,还应该对字符编码方式有一个新的认识。