linux0.11 块设备驱动与高速缓冲区
好久没继续,心中有愧呀。
一、介绍
块设备驱动中包含了三部分代码:硬盘驱动,ramdisk驱动,软盘驱动。
这三个部分的代码是一致的,采用了相同的处理方式。就是说对底层来说,不同硬件采用不同的方式读取数据,
但上层用同样的接口来处理读写操作。
大致流程:
1:程序要读取数据,首先向缓存区管理程序发出申请,并进入睡眠。
2:缓冲区管理程序在缓冲区中查找是否已经读取过该数据块,是则直接返回数据,并唤醒程序。
否则使用更低级的块读写函数ll_rw_block()函数,从具体的设备上读取。
3:ll_rw_block()函数会向设备驱动程序发出读请求。 具体的做法是,先创建一个请求结构项,
然后插入请求队列。
4:当块设备处理到该请求项时,会将请求数据读出到指定的缓存区块中。
5:设置相关标志,并唤醒程序。
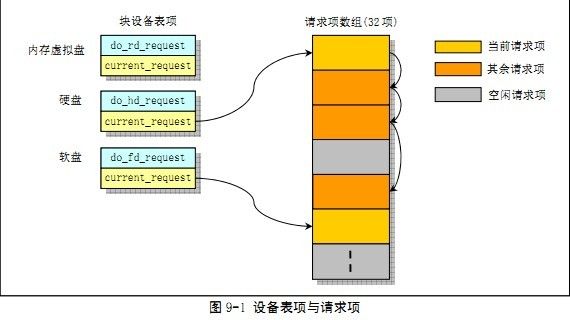
二、请求项、请求队列、缓冲块
当使用ll_rw_block()来读取数据时,它会创建一个请求项,并放入指定设备的请求队列。
struct blk_dev_struct {
void (*request_fn) (void);
struct request *current_request;
};
extern struct blk_dev_struct blk_dev [NR_BLK_DEV];
每个设备对应blk_dev数组中一现,current_request表示该设备的当前请求项,加上struct request中的next字段,便构成一个请求队列。
request_fn表示该设备处理请求项的函数。
在硬盘、ramdisk、软盘的初始化函数:hd_init, rd_init, floppy_init函数中
都有一句blk_dev[MAJOR_NR].request_fn = DEVICE_REQUEST,该语句给对应设备的请求项处理函数进行初始化。
本文以硬盘为例进行说明,因此DEVICE_REQUEST就是do_hd_request函数。
请求项
struct request {
int dev; // 设备号
int cmd; // 命令(读或写)
int errors;
unsigned long sector; // 起始扇区
unsigned long nr_sectors; // 扇区数
char *buffer; // 读或写用到的缓冲区
struct task_struct *waiting; // 等待该请求项的进程
struct buffer_head *bh; // 请求项对应的缓冲区块
struct request *next; // 下一个请求项
}
请求项数组
struct request request[NR_REQUEST]; NR_REQUEST值为32.
每个设备的blk_dev_struct中的current_request指针都指向request中的一项,然后利用struct request的next项,
构成每个设备的请求列表。因此设备的请求列表的请求项都是在请求数组中的。
三、缓冲区管理
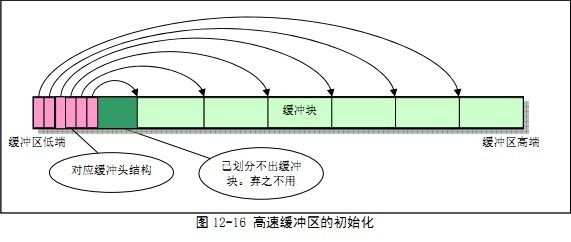
在Linux0.11初始化时,会根据内存大小来初始化高速缓冲区大小。
缓冲区位于end之后,buffer_memory_end值之前。end为内核模块的结束为止。
缓冲区被分成一些缓冲块,每个缓冲块大小为1024字节,即两个扇区。
在缓冲区中还包含一些struct buffer_head结构体(缓冲头结构)
struct buffer_head *start_buffer = (struct buffer_head *) &end。 // 可见struct buffer_head结构体起始于缓冲区的低地址。
在buffer_init函数里会对start_buffer之后的一些buffer_head结构体进行初始化。
最后的结果如下图:
buffer_head结构体:
struct buffer_head {
char *b_data; // 指向缓冲块数据区
unsigned long b_blocknr; // 块号
unsigned short b_dev; // 设备号
unsigned char b_uptodate; // 更新标示:表示数据是否已更新
unsigned char b_dirt; // 修改标志:0--未修改, 1--已修改
unsigned char b_count; // 使用该块的用户数
unsigned char b_lock; // 缓冲区是否被锁定,0--unlocked,1--locked
struct task_struct *b_wait; // 等待缓冲区解锁的进程
struct buffer_head *b_prev; // hash表的前一个
struct buffer_head *b_next; // hash表的后一个
struct buffer_head *b_prev_free; // free表的前一个
struct buffer_head *b_next_free; // free表的后一个
}
这个结构体的最后四个指针,表示了对buffer_head的管理。
通过两种方式对buffer_head进行管理
1:free_list指针,free_list指针指向第一个空闲的缓冲头(buffer_head),全部的空闲buffer_head
通过b_prev_free和b_next_free构成一个双向循环链表。
2:hash数组。
struct buffer_head *hash[NR_HASH], NR_HASH的值为307。对一个正在使用的buffer_head,根据其中的设备号和逻辑块号
计算出该buffer_head的hash值,并把该buffer_head放入hash数组中去,每一个hash数组项,下面是一个双向循环链表。
buffer_head中的b_uptodate和b_dirt
b_dirt表示缓冲块内容是否已被修改。
b_uptodate表示缓冲区内容是否与...............................................
当要请求一个块设备上的数据块时,首先利用请求的设备号和逻辑块号,求hash,然后在相应的hash数组项中查找缓冲块,
看是否需要的数据块已经放入缓冲区中。若没有,就会分配一个新的buffer_head,然后调用ll_rw_block去读取相应的块设备上的数据块。
读取数据首先使用bread。
getblk函数首先调用get_hash_table函数,从hash表中查找指定的(dev,block)是否已经在缓冲区中。
若没有在缓冲区中,则会在free_list中寻找一个空的buffer_head。
空的buffer_head的意思是指buffer_head.b_count值为0,没有被任何进程引用。
但该buffer_head指向的缓冲块可能是b_dirt=1和b_lock=1的。根据这两个值,对每个buffer_head定义了一个优先级。
#define BADNESS(bh) (((bh)->b_dirt<b_lock)
这个宏表明:但b_dirt和b_lock都为1时,该buffer_head为非常BADNESS的。优先选择b_dirt=0和b_lock=0的buffer_head.
当找到一个buffer_head之后,如果它是lock的,就需要等待解锁,如果它是dirt的,则需要将缓冲区的内容写入磁盘。
若没有找到适合的buffer_head,则调用sleep_on(&buffer_wait)进入睡眠。
若最终得到一个buffer_head后:
bh->b_count = 1; // 占用该缓冲块
bh->b_dirt = 0; // 干净的
bh->b_uptodate = 0; // 复位
然后将buffer_head从hash表取出,并移到free_list链表的最后去(最近最少使用算法)
remove_from_queues(bh)
bh->b_dev=dev;
bh->b_blocknr=block;
insert_into_queues(bh);
释放一个buffer_head
sleep_on和wake_up函数。
在getblk中若没有找到可用buffer_head会调用sleep_on进入睡眠。
在brelse释放buffer_head的时候,会调用wake_up唤醒等待的进程。
这是两个很有意思的函数,这里描述下它们如何工作的。
起初buffer_wait指针为NULL: static struct task_struct *buffer_wait = NULL;
如果三个进程A,B,C先后调用了sleep_on,然后进程D调用了wake_up,看看这时会发生什么。
进程A调用sleep_on(&buffer_wait):
tmp = *p // tmp = NULL
*p = current // 此时buffer_wait = current,即进程A
current->state = TASK_UNINTERRUPTIBLE; // 进程A设定为不可调度
schedule() // 调度到其他进程
if (tmp) tmp->state = 0; // tmp=NULL
进程B调用sleep_on(&buffer_wait):
tmp = *p // tmp = 进程A的task_struct
*p = current // buffer_wait = 进程B的task_struct
current->state = TASK_UNINTERRUPTIBLE; // 进程B设定为不可调度
schedule() // 调度到其他进程
if (tmp) tmp->state = 0; // 将进程A设定为可调度
进程C调用sleep_on(&buffer_wait):
tmp = *p // tmp = 进程B的task_struct
*p = current // buffer_wait = 进程C的task_struct
current->state = TASK_UNINTERRUPTIBLE; // 进程C设定为不可调度
schedule() // 调度到其他进程
if (tmp) tmp->state = 0; // 将进程B设定为可调度
进程D调用wake_up(&buffer_wait):
(**P).state=0 // 将进程C设定为可以调度。
因此在下一次schedule()时,进程C可以被执行,当调度到进程C后会继续执行刚才的sleep_on
之后的if(tmp) tmp->state = 0,它会将进程B的状态为可运行状态。当进程B被调度到后,又会将
进程A的状态设为可运行状态。 就像一个链表似的。
四:ll_rw_block()函数
在实际要读取块设备时,最终都会执行到ll_rw_block函数,该函数根据buffer_head生成一个request,并将请求加入设备的请求队列中去。
IN_ORDER(tmp,req)的作用类似于在比较tmp和req这两个请求。
如果tmp请求“小于”req请求,则IN_ORDER为真。
“小于”的意思:
(1)写请求小于读请求。
(2)若请求类型相同,低设备号小于高设备号。
(3)若请求同一设备,低扇区号小于高扇区号。
do_hd_request函数
该函数处理硬盘的请求项。
(1)对于第一个请求项,即硬盘空闲时来了一个请求项。
那么在add_request会直接调用do_hd_request函数来处理该请求项。
(2)对第二个请求项。在do_hd_request处理第一个请求项的过程中,又来了一个请求项。
但do_hd_request完成第一个请求项时,会引发硬盘中断。在硬盘中断的处理函数中,又会调用
do_hd_request处理第二个请求项。
如果这个过程中来了第三个请求项,则do_hd_request处理完第二个请求项之后,会继续处理第三个。
一、介绍
块设备驱动中包含了三部分代码:硬盘驱动,ramdisk驱动,软盘驱动。
这三个部分的代码是一致的,采用了相同的处理方式。就是说对底层来说,不同硬件采用不同的方式读取数据,
但上层用同样的接口来处理读写操作。
大致流程:
1:程序要读取数据,首先向缓存区管理程序发出申请,并进入睡眠。
2:缓冲区管理程序在缓冲区中查找是否已经读取过该数据块,是则直接返回数据,并唤醒程序。
否则使用更低级的块读写函数ll_rw_block()函数,从具体的设备上读取。
3:ll_rw_block()函数会向设备驱动程序发出读请求。 具体的做法是,先创建一个请求结构项,
然后插入请求队列。
4:当块设备处理到该请求项时,会将请求数据读出到指定的缓存区块中。
5:设置相关标志,并唤醒程序。
二、请求项、请求队列、缓冲块
当使用ll_rw_block()来读取数据时,它会创建一个请求项,并放入指定设备的请求队列。
struct blk_dev_struct {
void (*request_fn) (void);
struct request *current_request;
};
extern struct blk_dev_struct blk_dev [NR_BLK_DEV];
每个设备对应blk_dev数组中一现,current_request表示该设备的当前请求项,加上struct request中的next字段,便构成一个请求队列。
request_fn表示该设备处理请求项的函数。
在硬盘、ramdisk、软盘的初始化函数:hd_init, rd_init, floppy_init函数中
都有一句blk_dev[MAJOR_NR].request_fn = DEVICE_REQUEST,该语句给对应设备的请求项处理函数进行初始化。
本文以硬盘为例进行说明,因此DEVICE_REQUEST就是do_hd_request函数。
请求项
struct request {
int dev; // 设备号
int cmd; // 命令(读或写)
int errors;
unsigned long sector; // 起始扇区
unsigned long nr_sectors; // 扇区数
char *buffer; // 读或写用到的缓冲区
struct task_struct *waiting; // 等待该请求项的进程
struct buffer_head *bh; // 请求项对应的缓冲区块
struct request *next; // 下一个请求项
}
请求项数组
struct request request[NR_REQUEST]; NR_REQUEST值为32.
每个设备的blk_dev_struct中的current_request指针都指向request中的一项,然后利用struct request的next项,
构成每个设备的请求列表。因此设备的请求列表的请求项都是在请求数组中的。
三、缓冲区管理
在Linux0.11初始化时,会根据内存大小来初始化高速缓冲区大小。
缓冲区位于end之后,buffer_memory_end值之前。end为内核模块的结束为止。
缓冲区被分成一些缓冲块,每个缓冲块大小为1024字节,即两个扇区。
在缓冲区中还包含一些struct buffer_head结构体(缓冲头结构)
struct buffer_head *start_buffer = (struct buffer_head *) &end。 // 可见struct buffer_head结构体起始于缓冲区的低地址。
在buffer_init函数里会对start_buffer之后的一些buffer_head结构体进行初始化。
最后的结果如下图:
buffer_head结构体:
struct buffer_head {
char *b_data; // 指向缓冲块数据区
unsigned long b_blocknr; // 块号
unsigned short b_dev; // 设备号
unsigned char b_uptodate; // 更新标示:表示数据是否已更新
unsigned char b_dirt; // 修改标志:0--未修改, 1--已修改
unsigned char b_count; // 使用该块的用户数
unsigned char b_lock; // 缓冲区是否被锁定,0--unlocked,1--locked
struct task_struct *b_wait; // 等待缓冲区解锁的进程
struct buffer_head *b_prev; // hash表的前一个
struct buffer_head *b_next; // hash表的后一个
struct buffer_head *b_prev_free; // free表的前一个
struct buffer_head *b_next_free; // free表的后一个
}
这个结构体的最后四个指针,表示了对buffer_head的管理。
通过两种方式对buffer_head进行管理
1:free_list指针,free_list指针指向第一个空闲的缓冲头(buffer_head),全部的空闲buffer_head
通过b_prev_free和b_next_free构成一个双向循环链表。
2:hash数组。
struct buffer_head *hash[NR_HASH], NR_HASH的值为307。对一个正在使用的buffer_head,根据其中的设备号和逻辑块号
计算出该buffer_head的hash值,并把该buffer_head放入hash数组中去,每一个hash数组项,下面是一个双向循环链表。
buffer_head中的b_uptodate和b_dirt
b_dirt表示缓冲块内容是否已被修改。
b_uptodate表示缓冲区内容是否与...............................................
当要请求一个块设备上的数据块时,首先利用请求的设备号和逻辑块号,求hash,然后在相应的hash数组项中查找缓冲块,
看是否需要的数据块已经放入缓冲区中。若没有,就会分配一个新的buffer_head,然后调用ll_rw_block去读取相应的块设备上的数据块。
读取数据首先使用bread。
- struct buffer_head *bread(int dev, int block) // 参数包括块设备号和数据块号
- {
- struct buffer_head *bh;
-
- if (!(bh=getblk(dev, block))) // 先调用getblk来获得buffer_head
- panic("bread: getblk returned NULLn")
- if (bh->b_uptodate) // bh是有效的,直接返回
- return bh;
- ll_rw_block(READ, bh); // bh无效,则用ll_rw_block调用底层函数来读取数据
- wait_on_buffer(bh); // 等待读取完成
- if (bh->b_uptodate) // bh有效返回
- return bh;
- brelease(bh); // bh无效,释放bh,返回NULL。
- return NULL;
- }
getblk函数首先调用get_hash_table函数,从hash表中查找指定的(dev,block)是否已经在缓冲区中。
若没有在缓冲区中,则会在free_list中寻找一个空的buffer_head。
空的buffer_head的意思是指buffer_head.b_count值为0,没有被任何进程引用。
但该buffer_head指向的缓冲块可能是b_dirt=1和b_lock=1的。根据这两个值,对每个buffer_head定义了一个优先级。
#define BADNESS(bh) (((bh)->b_dirt<b_lock)
这个宏表明:但b_dirt和b_lock都为1时,该buffer_head为非常BADNESS的。优先选择b_dirt=0和b_lock=0的buffer_head.
当找到一个buffer_head之后,如果它是lock的,就需要等待解锁,如果它是dirt的,则需要将缓冲区的内容写入磁盘。
若没有找到适合的buffer_head,则调用sleep_on(&buffer_wait)进入睡眠。
若最终得到一个buffer_head后:
bh->b_count = 1; // 占用该缓冲块
bh->b_dirt = 0; // 干净的
bh->b_uptodate = 0; // 复位
然后将buffer_head从hash表取出,并移到free_list链表的最后去(最近最少使用算法)
remove_from_queues(bh)
bh->b_dev=dev;
bh->b_blocknr=block;
insert_into_queues(bh);
释放一个buffer_head
- void brelse(struct buffer_head *buf)
- {
- if (!buf)
- return ;
- wait_on_buffer(buf); // buf is locked
- if (!(buf->b_count--))
- panic(....)
- wake_up(&buffer_wait); // wake_up等待buffer的进程。与getblk中的sleep_on(&buffer_wait)相对应。
- }
sleep_on和wake_up函数。
在getblk中若没有找到可用buffer_head会调用sleep_on进入睡眠。
在brelse释放buffer_head的时候,会调用wake_up唤醒等待的进程。
这是两个很有意思的函数,这里描述下它们如何工作的。
- void sleep_on(struct task_struct **p)
- {
- struct task_struct *tmp;
-
- if (!p)
- return ;
- if (current == &(init_task.task))
- panic("task[0] trying to sleep");
- tmp = *p;
- *p = current;
- current->state = TASK_UNINTERRUPTIBLE;
- schedule();
- if (tmp)
- tmp->state = 0;
- }
- void wake_up(struct task_struct **p)
- {
- if (p && *p) {
- (**p).state = 0;
- *p = NULL;
- }
- }
如果三个进程A,B,C先后调用了sleep_on,然后进程D调用了wake_up,看看这时会发生什么。
进程A调用sleep_on(&buffer_wait):
tmp = *p // tmp = NULL
*p = current // 此时buffer_wait = current,即进程A
current->state = TASK_UNINTERRUPTIBLE; // 进程A设定为不可调度
schedule() // 调度到其他进程
if (tmp) tmp->state = 0; // tmp=NULL
进程B调用sleep_on(&buffer_wait):
tmp = *p // tmp = 进程A的task_struct
*p = current // buffer_wait = 进程B的task_struct
current->state = TASK_UNINTERRUPTIBLE; // 进程B设定为不可调度
schedule() // 调度到其他进程
if (tmp) tmp->state = 0; // 将进程A设定为可调度
进程C调用sleep_on(&buffer_wait):
tmp = *p // tmp = 进程B的task_struct
*p = current // buffer_wait = 进程C的task_struct
current->state = TASK_UNINTERRUPTIBLE; // 进程C设定为不可调度
schedule() // 调度到其他进程
if (tmp) tmp->state = 0; // 将进程B设定为可调度
进程D调用wake_up(&buffer_wait):
(**P).state=0 // 将进程C设定为可以调度。
因此在下一次schedule()时,进程C可以被执行,当调度到进程C后会继续执行刚才的sleep_on
之后的if(tmp) tmp->state = 0,它会将进程B的状态为可运行状态。当进程B被调度到后,又会将
进程A的状态设为可运行状态。 就像一个链表似的。
四:ll_rw_block()函数
在实际要读取块设备时,最终都会执行到ll_rw_block函数,该函数根据buffer_head生成一个request,并将请求加入设备的请求队列中去。
- void ll_rw_block(int rw, struct buffer_head *bh)
- {
- unsigned int major;
- if ((major=MAJOR(bh->b_dev)) >= NR_BLK_DEV || !(blk_dev[major].request_fn)) {
- printk("Trying to read nonexistent block-devicenr");
- return;
- }
- make_request(major, rw, bh); // 生成请求
- }
- static void make_request(int major,int rw, struct buffer_head * bh)
- {
- struct request * req;
- int rw_ahead;
-
- /* WRITEA/READA is special case - it is not really needed, so if the */
- /* buffer is locked, we just forget about it, else it's a normal read */
- if ((rw_ahead = (rw == READA || rw == WRITEA))) {
- if (bh->b_lock)
- return;
- if (rw == READA)
- rw = READ;
- else
- rw = WRITE;
- }
- if (rw!=READ && rw!=WRITE)
- panic("Bad block dev command, must be R/W/RA/WA");
- lock_buffer(bh); // 首先要锁定buffer
- if ((rw == WRITE && !bh->b_dirt) || (rw == READ && bh->b_uptodate)) {
- unlock_buffer(bh);
- return;
- }
- repeat:
- // 在请求数组request中,将后面的用来读,前面的用来写。
- if (rw == READ)
- req = request+NR_REQUEST;
- else
- req = request+((NR_REQUEST*2)/3);
- // 寻找空闲的请求项。req->dev == -1时,请求项为空闲的。
- while (--req >= request)
- if (req->dev<0)
- break;
- // 没有空闲的请求项,则等待。
- if (req < request) {
- if (rw_ahead) {
- unlock_buffer(bh);
- return;
- }
- sleep_on(&wait_for_request);
- goto repeat;
- }
- /* 初始化请求项的值 */
- req->dev = bh->b_dev;
- req->cmd = rw;
- req->errors=0;
- req->sector = bh->b_blocknr<<1;
- req->nr_sectors = 2;
- req->buffer = bh->b_data;
- req->waiting = NULL;
- req->bh = bh;
- req->next = NULL;
- add_request(major+blk_dev,req); // 将请求项放入设备的请求队列中
- }
- static void add_request(struct blk_dev_struct * dev, struct request * req)
- {
- struct request * tmp;
-
- req->next = NULL;
- cli();
- if (req->bh)
- req->bh->b_dirt = 0;
- if (!(tmp = dev->current_request)) { // 如果设备当前没有请求项,则将current_request设为req
- dev->current_request = req; // 并执行dev->request_fn处理请求。
- sti();
- (dev->request_fn)();
- return;
- }
- // 将请求插入请求队列,电梯算法
- for ( ; tmp->next ; tmp=tmp->next)
- if ((IN_ORDER(tmp,req) ||
- !IN_ORDER(tmp,tmp->next)) &&
- IN_ORDER(req,tmp->next))
- break;
- // 将请求插入tmp之后。
- req->next=tmp->next;
- tmp->next=req;
- sti();
- }
如果tmp请求“小于”req请求,则IN_ORDER为真。
“小于”的意思:
(1)写请求小于读请求。
(2)若请求类型相同,低设备号小于高设备号。
(3)若请求同一设备,低扇区号小于高扇区号。
do_hd_request函数
该函数处理硬盘的请求项。
(1)对于第一个请求项,即硬盘空闲时来了一个请求项。
那么在add_request会直接调用do_hd_request函数来处理该请求项。
(2)对第二个请求项。在do_hd_request处理第一个请求项的过程中,又来了一个请求项。
但do_hd_request完成第一个请求项时,会引发硬盘中断。在硬盘中断的处理函数中,又会调用
do_hd_request处理第二个请求项。
如果这个过程中来了第三个请求项,则do_hd_request处理完第二个请求项之后,会继续处理第三个。
以此类推。
http://blog.chinaunix.net/uid-24631445-id-3753834.html