深入剖析 iLBC 编码器原理
早在2005年就听说iLBC编解码算法,主要是应用在VOIP 的speech codec,但是一直没有深入研究算法原理,碰巧近期有一些时间可以学习一下它相比基于CELP模型的speech codec的优势。这套代码是浮点的,听朋友说要是转成定点代码会比较有用,只是可能需要的时间会多一点。如果想了解iLBC的一般介绍,如编码速率、应用等,可以参考前面的文章《iLBC编解码相关知识》 ,下面主要是我的一些学习笔记,仅供大家参考。
一、算法整体流程

输入的语音逐帧进行预处理,然后计算LPC系数和残差信号,在残差信号中选择初始状态,并对其进行标量量化,再对剩下的残差信号进行增益/形状矢量量化,最后封包成比特流。
iLBC的每frame/block保持独立编码,这样才能保证在丢包的情况下,保持良好的重建语音质量;而CELP模型的codec往往都需要look head buffer 才能对当前帧进行编码,这样虽然可以使重建语音连接比较平滑,但是在网络传输中一旦发生丢包,则连续性遭到破坏,解码语音的质量就会下降。
在iLBC的编码流程中有三个模块Select Start state、Scalar quantization和CB Search是与CELP模型不同的,下面重点研究这三个模块。
1、起始状态(Start State)
这个概念是iLBC所特有的处理方式,下面以30ms frame mode为例,那么每个frame有6个sub-frame。iLBC在计算完LPC残差信号后,会找出整个帧内具有最高功率的两个连续子帧,来决定起始状态的位置。下图给出了start state 在两个子帧的位置。
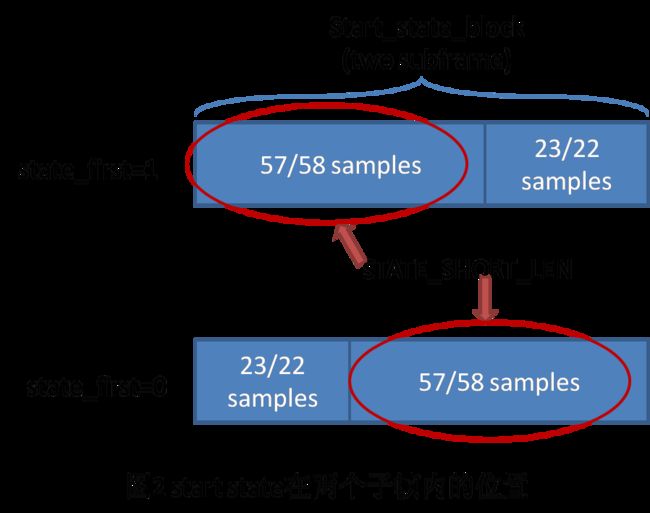
2、对起始状态样点的量化
这里并不对两个子帧的全部sample进行精细量化,只是对从起始状态位置以后的57/58 sample(20ms/30ms frame mode)进行精细量化,所以这57/58 sample的量化需要三个部分:
1)子帧位置;
是指哪两个子帧,如 sub-frame 0,1; 1,2; 2,3; 3,4; 4,5
3bit 量化这五种情况。
2)两个子帧内的前半部分还是后半部分;
1bit 表示 state_first;
3)57/58 sample的标量量化。
这里首先要进行全通滤波,使得样点大小比较平均分布,然后进行能量的归一化,这个scaler factor用6bit标量量化,归一化后的样点动态范围就比较小了,然后对每一个样点都采用3bit 的DPCM量化。
3、码书搜索
这部分是指起始状态量化后,整个frame剩余的样点量化方法。这里主要采用了动态码书的量化方法,码书是由整个frame的样点通过线性组合(加权滤波)和已经量化样点的解码信号组成,具体的流程见图3。
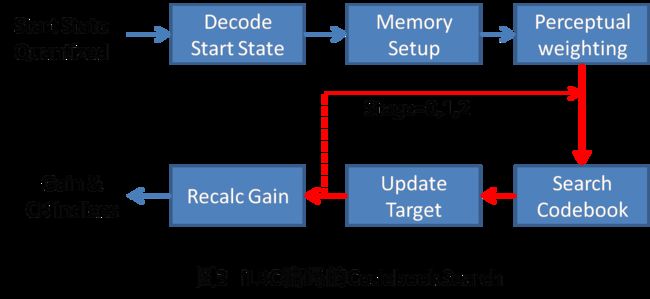
上图首先解码已经量化的Start state,然后构建codebook memory,结合目标矢量进行感知加权滤波,在Codebook内部搜索与目标矢量最接近的矢量,这里采用三阶段的增益/形状矢量量化的方法进行搜索量化,最后调整增益以补偿能量损失。这里主要的重点还是码书的组成、大小以及量化顺序、搜索过程。
例如,图4给出了一个30ms 帧的量化顺序,这里有6个子帧,假设Start state是在1、2子帧之间,并且位置在两个子帧后半部分,那么进行量化的顺序如下:
1)Q0:量化Start State;
2)Q1:两个子帧内除了start state的22/23个样点;
3)Q2,Q3,Q4:Start state的后面每个子帧;
4)Q5:Start state的前面每个子帧;

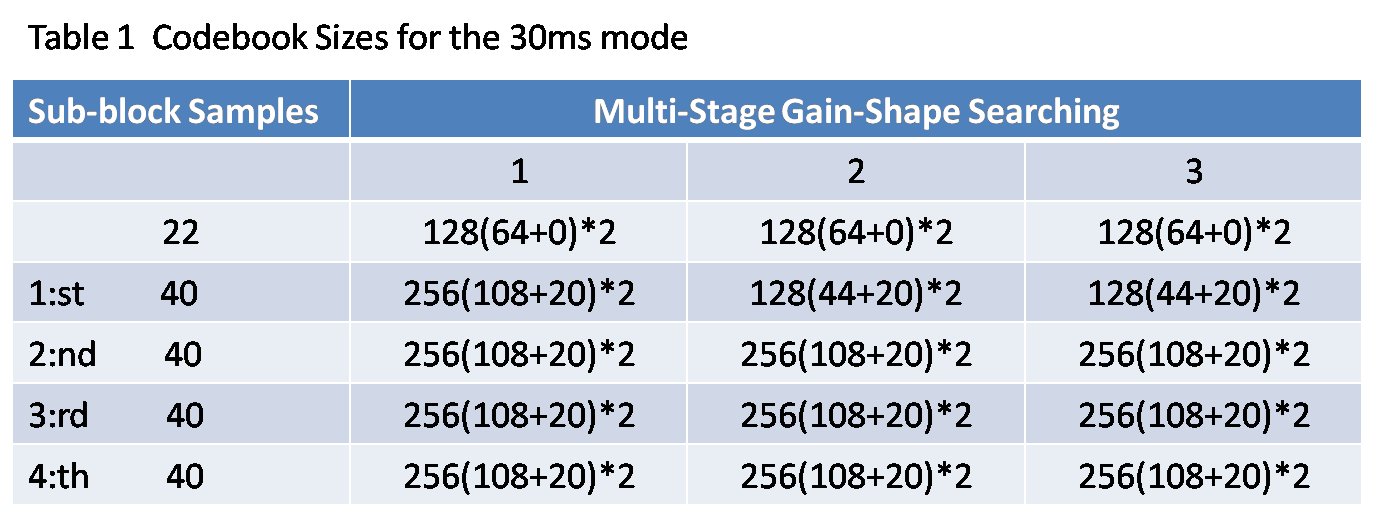
到这里可以知道,目标矢量包括两种长度不同的矢量(除了start state):22/23个样点的矢量和40个样点的子帧矢量,下表给出了对于不同矢量的码书大小。
下图具体给出了量化目标矢量时动态码书的构造,需要注意的有以下几点:
1)不同的目标矢量(22/23、子帧40)对应的码书大小不同,具体数据见参考资料;
2)量化Start State前向的矢量需要对码书进行反转,再进行搜索,如对Q1、Q5进行量化;
3)动态码书的构成是解码的已量化样点而不是原来的经过感知加权的残差信号;
4)码书通过补零长度对齐;

增益/形状矢量量化属于乘积码矢量量化中的一种方法,它的基本思想就是将待量化的矢量的形状和增益分别量化,同时保持它们之间的有机联系,最后将码字相乘就可以得到重构矢量。这种量化方法可以实现高维数的矢量量化,以提高系统的性能。
下表给出了iLBC编码器的比特流定义,值得注意的是在封包前每个参数的bit是分成三个级别的,1表示最重要,2比较重要,3一般重要,因此封包是按照级别处理的,如图先处理级别1,然后级别2,最后级别3,这样提高了抗干扰性: 
二、总结
与传统的CELP模型的speech codec有较大不同,精髓在于帧内的独立编码,同时也利用了长时预测编码(LPC)去除冗余信息和语音信号本身准周期性的特征构造动态码书。与CELP模型codec相比,在丢包率较高的网络情况下,语音质量不会下降很快。对于解码端的丢包补偿算法(packet loss concealment)现在还没有看到,这个技术应该也是iLBC的一个特点。
本文并没有列出详细的数据和语音质量评测,那些都可以在下面得参考资料找到。
参考资料:
《rfc3951.txt》
一家之言,欢迎讨论交流!
转载:http://blog.csdn.net/wanggp_2007/article/details/5114309