谱聚类算法及其代码(Spectral Clustering)
简介
文章将介绍谱聚类(spectral clustering)的基本算法,以及在matlab下的代码实现。介绍内容将包括:
- 从图分割角度直观理解谱聚类
- 谱聚类算法步骤
- 数据以及实现代码
本文将不会涉及细节化的证明和推导,如有兴趣可参考july大神的文章从拉普拉斯矩阵说到谱聚类.
对谱聚类的理解
这一节将从图分割聚类的角度直观理解谱聚类。不过,因为本人是从事社交媒体分析的,将从一种社会关系网络的角度来介绍网络图分割成多个子图的概念。
图的分割
首先将社会关系网络看成是一个整体,每一个个体(user)就是这个网络中的各个节点(node),而连接个体的就是各个节点之间的边(edge)。在不同性质的网络中,边的定义可能有所不同,这里可以简单的理解成个体之间关系的亲密度。如图(1)所示
 图(1)
图(1)
每个个体与其他个体之间都有关系亲密度(也叫做权重,设定范围是[0,1]),可以看到user1,2,3之间关系紧密,user4,5,6关系紧密,而两个小部分是靠着user2和user6来联系的。以现实生活为例,123是A班级同学,456是B班级同学,2和6正好是认识的,关系一般,所以我们可以直观的把2和6之间的边给截断(cut),从而形成两个互不相关的子图,这样就完成了对这个网络的分割。
图的泛化意义
很多时候,并不是说一定要实际生活中是一个网络(network)的事物,才能够用图(graph)模型来表示。图模型只是解决问题的一个模型,可能一个对象既可以用图模型,也可以用非图模型来解决(拓扑,非拓扑)。举个例子,在聚类,我们之前(K-means 聚类算法及其代码实现)讨论过如何将数据点看成是坐标系下的一个个点,然后迭代找出中心点从而聚类。如果以另外一种视角,我们的坐标系中的各个点看成是图的节点,而点与点之间的相似性看成是边的权重,我们同样就构成了一个图模型。所以图与非图是相对来看的,取决于哪个更好解决问题。
谱聚类的意义
谱聚类要做的事情就是完成对图的分割,它想要找到最好的分割方式,来将图分割开来。这种对图的分割,取决于你如何定义这个图。比如,图中的点是什么?图中的边又是怎么确定的?最优分割的标准又是怎么样的?等等。对图本身定义的不同,就会导致不同的分割结果,所以我们为了明确这些东西,在这里以一个实际的定义为准,事先声明,图的定义也可以用其他方式,不过我这里用的就是现在常用的相似度矩阵图模型。
我们要解决的问题是:给定数据{ x1,x2,x3,...,xN },将其分成 K 个类。
而我们将这些数据点都看成是数据的节点,它们之间的相似度定义为边的权重值,相似度矩阵为 W={wij|1≤i≤N,1≤j≤N} ,其中相似性是按照
高斯相似度来计算的,其中 σ 是一个超参数(hyperparameter)。当然其他的相似性(如余弦相似度)也是同样适用的。可以看出,相似度矩阵 W 是一个对称(symmetric)矩阵。为了使某个单节点不会更容易被剔除,我们考虑一个归一化的对角矩阵 D (diagonal),对角线上元素是相似度矩阵一行(列,因为对称行列一样)所有元素的和,即
这样计算。
因为没有给出关于截的概念,所以没有办法给出优化函数的形式,具体内容,还请参考从拉普拉斯矩阵说到谱聚类。
谱聚类算法步骤
这一小节将会给出谱聚类算法的步骤,整体来说,谱聚类算法要做的就是先求出相似性矩阵,然后对该矩阵归一化运算,之后求前 K 个特征向量,最后运用K-means算法分类。
实际上,谱聚类要做的事情其实就是将高维度的数据,以特征向量的形式简洁表达,属于一种降维的过程。本来高维度用k-means不好分的点,在经过线性变换以及降维之后,十分容易求解。下面就给出步骤:
1. 按照式 (1) 计算相似性矩阵 W
2. 将 W 的对角线值,即 W(i,i)=0 ,是为了排除自身的相似度
3. 按照式 (2) 计算归一化矩阵 D
4. 按照式 (3) 计算归一化拉普拉斯图矩阵L
5. 计算L的特征向量,将前 K 个特征值最大的向量按列放置成一个矩阵 X ,即
6. 归一化X形成矩阵Y
7. 对矩阵Y按每行为一个数据点,进行k-means聚类,第 i 行所属的类就是原来 xi 所属的类。
至此就完成了谱聚类的全部过程。但是这里面我们其实忽略了一个很重要的参数 σ ,这个参数是需要初始化的,如何选择 σ 呢?请看下一节实例分析。
谱聚类代码分析
这一节介绍如何用matlab实现谱聚类的算法,数据以及代码可以在我的github上下载。
代码要解决的问题是如图(2)所示的一个分类问题,

图(2)
从图片上面我们可以看到这个数据有两个环,外面的环就是第一类,内部的环就是第二类,这个分类问题,是普通的k-means算法无法解决的。所以我们将使用代码来实现上一节介绍的各个步骤。
首先,我们的数据存在
data中,导入得到数据
allpts.
- 计算相似度矩阵 W ,其中向量化是运算可以用式 (5) 来理解。
X = allpts;
N = size(X,1);
squared_X = sum(X.*X,2);
transi_X = X*X'; %x_j * x_i^T;
X_i = repmat(squared_X,1,N); % same value in row
X_j = repmat(squared_X',N,1); % same value in col
E = -(X_i + X_j - 2*transi_X );
W = exp(E/(2*sigsq));
2. 将对角线设为零
W = W - diag(diag(W));diag()既可以取出对角线的元素,也可以将一个向量生成一个对角矩阵。
3. 计算归一化矩阵 D :
D = diag(sum(W'));.
4. 计算拉普拉斯矩阵 L
L =D^(-.5)*W*D^(-.5);.
5. 找特征值特征向量并排序,找前K个
K = 2;
[X,di]=eig(L);
[Xsort,Dsort]=eigsort(X,di);
Xuse=Xsort(:,1:K);因为我这里面只想分成两类,所以K=2. 同时这里的eigsort是另外定义1的函数,如下
% [Vsort,Dsort] = eigsort(V,D)
%
% Sorts a matrix eigenvectors and a matrix of eigenvalues in order
% of eigenvalue size, largest eigenvalue first and smallest eigenvalue
function [Vsort,Dsort] = eigsort(V,D);
eigvals = diag(D);
% Sort the eigenvalues from largest to smallest. Store the sorted
% eigenvalues in the column vector lambda.
[lohival,lohiindex] = sort(eigvals);
lambda = flipud(lohival);
index = flipud(lohiindex);
Dsort = diag(lambda);
% Sort eigenvectors to correspond to the ordered eigenvalues. Store sorted
% eigenvectors as columns of the matrix vsort.
M = length(lambda);
Vsort = zeros(M,M);
for i=1:M
Vsort(:,i) = V(:,index(i));
end;其中一些不必要的注释我就删除了。
6. 归一化X得到矩阵Y
Xsq = Xuse.*Xuse;
divmat=repmat(sqrt(sum(Xsq')'),1,2) Y=Xuse./divmat归一化就是将特征向量长度变成1
7. 进行k-means聚类算法
[c,Dsum,z] = kmeans(Y,2)
kk=c;
c1=find(kk==1);
c2=find(kk==2);kmeans聚类后,找到类别标号,最后简单画一个图(3)显示我们的分类结果
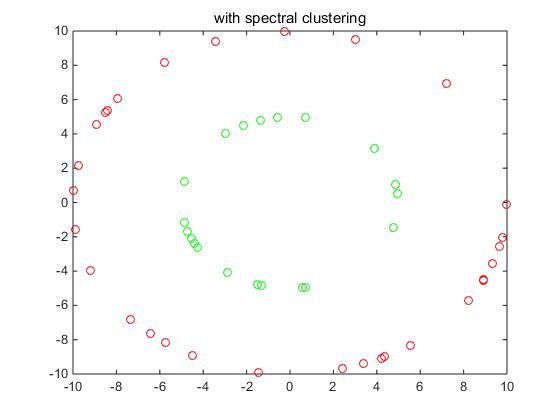
图(3)
这里,我们用两种颜色表示了两种不同的类别,代码中的
sigma可能不同,会导致不同的结果,这个我没有给出,各人根据问题各自设定0.1到10之类,具体可以去 我的github上面下载完整代码和数据。
总结
至此,完成了全部的谱聚类算法的理解,算法具体步骤,以及实际实现代码。谱聚类能够完成k-means不能完成的工作,其基本思想是一个线性空间变换,能够提取出特征向量降维表示原本复杂的数据,从来使用k-means进行一个简单的聚类。涉及到特征向量的算法,还有之后会继续写的PCA算法。
参考文献
- Ng, A. Y., M. I. Jordan, and Y. Weiss (2001) “On Spectral Clustering:
- Shi, J., and J. Malik (1997) “Normalized Cuts and Image Segmentation”
- PRML
http://users.isr.ist.utl.pt/~wurmd/Livros/school/Bishop%20-%20Pattern%20Recognition%20And%20Machine%20Learning%20-%20Springer%20%202006.pdf ↩