基于Hadoop生态圈的数据仓库实践 —— 进阶技术(七)
七、递归
数据仓库中的关联实体经常表现为一种“父—子”关系。在这种类型的关系中,一个父亲可能有多个孩子,而一个孩子只能属于一个父亲。例如,一个人只能被分配到一个部门,而一个部门可能被分配许多人。“父—子”之间是一种递归型树结构,是一种最理想、最灵活的存储层次树的数据结构。本节说明一些递归处理的问题,包括数据装载、树的展开、递归查询、树的平面化等技术实现。为了保持销售订单示例的完整性,本节的实验将会使用另一个与业务无关的通用示例。
1. 建立表并添加实验数据
2. 数据装载
递归树结构的本质是,在任意时刻,每个父—子关系都是唯一的。通常,操作型系统只维护层次树的当前视图,因此,输入数据仓库的数据通常是当前层次树的时间点快照。这就需要由ETL过程来确定发生了哪些变化,以便正确记录历史信息。为了检测出过时的父—子关系,必须通过孩子键进行查询,然后将父亲作为结果返回。在这个例子中,对tree表采用整体拉取模式抽数据,tree_dim表的c_name和c_parent列上使用SCD2装载类型。也就是说,把c_parent当做源表的一个普通属性,当一个节点的名字或者父节点发生变化时,都增减一条新版本记录,并设置老版本的过期时间。这样的装载过程和销售订单的例子并无二致。
(1)建立init_etl_tree.sh、init_etl_tree.sql、regular_etl_tree.sh、regular_etl_tree.sql四个脚本实现tree_dim维度表的初始装载和定期装载。
init_etl_tree.sh文件用于初始装载,其内容如下:
初始时源表数据的递归树结构如下图所示:
执行初始装载
 从查询结果看到,维度表中新增全部11条记录。
从查询结果看到,维度表中新增全部11条记录。
修改源表数据,这次修改了所有节点的名称
 从查询结果看到,现在维度表中共有22条记录,其中新增11条当前版本记录,老版本的11条记录的过期时间字段被设置为'2016-07-26'。
从查询结果看到,现在维度表中共有22条记录,其中新增11条当前版本记录,老版本的11条记录的过期时间字段被设置为'2016-07-26'。
修改源表数据,这次修改了部分节点的名称,并新增了两个节点。

将regular_etl.sql文件中的SET hivevar:cur_date = CURRENT_DATE();行改为SET hivevar:cur_date = '2016-07-28';后,执行定期装载
 从查询结果看到,现在维度表中共有29条记录,其中新增7条当前版本记录(5行因为改名,其中1、3既改名又更新父子关系,2行新增节点),更新了5行老版本的过期时间,被设置为'2016-07-27'。
从查询结果看到,现在维度表中共有29条记录,其中新增7条当前版本记录(5行因为改名,其中1、3既改名又更新父子关系,2行新增节点),更新了5行老版本的过期时间,被设置为'2016-07-27'。
修改源表数据,这次修改了部分节点的名称,并删除了三个节点。
将regular_etl.sql文件中的SET hivevar:cur_date = CURRENT_DATE();行改为SET hivevar:cur_date = '2016-07-29';后,执行定期装载
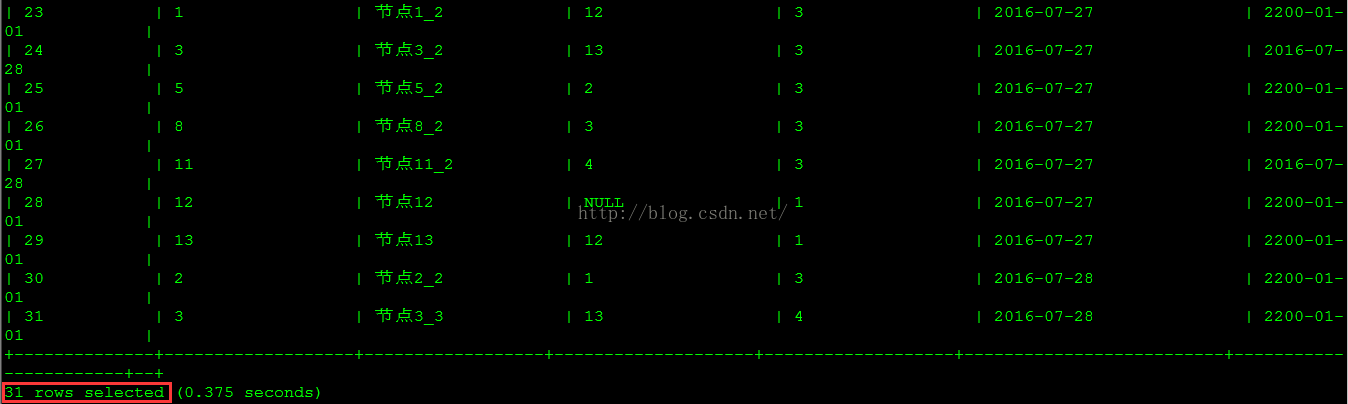
从查询结果看到,现在维度表中共有31条记录,其中新增2条当前版本记录(因为改名),更新了5行老版本的过期时间(2行因为改名,3行因为节点删除),被设置为'2016-07-28'。
装载实验完成后,还原regular_etl.sh脚本,将文件中的SET hivevar:cur_date = DATE_ADD(CURRENT_DATE(),2);行改为SET hivevar:cur_date = CURRENT_DATE();
3. 树的展开
有些BI工具的前端不支持递归,这时递归层次树的数据交付技术就是“展开”(explode)递归树。展开是这样一种行为,一边遍历递归树,一边产生新的结构,该结构包含了贯穿树中所有层次的每个可能的关系。展开的结果是一个非递归的关系对表,该表也可能包含描述层次树中关系所处位置的有关属性。下图展示了一个展开树的例子,图中左侧为原递归树数据,右边为树展开后的数据。
将树展开消除了对递归查询的需求,因为层次不再需要自连接。当按这种表格形式将数据交付时,使用简单的SQL查询就可以生成层次树报表。下面说明树展开的实现。
使用下面的命令将相关jar包复制到HDFS。
4. 查询
Hive本身还没有递归查询功能,但正如前面提到的,使用简单的SQL查询递归树展开后的数据,即可生成层次树报表,例如下面的HiveQL语句实现了从下至上的树的遍历。
5. 递归树的平面化
递归树适合于数据仓库,而非递归结构则更适合于数据集市。前面的递归树展开用于消除递归查询,但缺点在于为检索与实体相关的属性必须执行额外的连接操作。而对于层次树来说,很常见的情况是,层次树元素所拥有的唯一属性就是描述属性(本例中的c_name字段),并且树的最大深度是固定的(本例是4层)。对这种情况,最好是将层次树作为平面化的1NF结或者2NF结构交付给数据集市。这类平面化操作对于平衡的层次树发挥得最好,但将缺失的层次置空可能可能会形成不整齐的层次树,因此它对深度未知的层次树(列数不固定)来说并不是一种有用的技术。下面说明递归树平面化的实现。
数据仓库中的关联实体经常表现为一种“父—子”关系。在这种类型的关系中,一个父亲可能有多个孩子,而一个孩子只能属于一个父亲。例如,一个人只能被分配到一个部门,而一个部门可能被分配许多人。“父—子”之间是一种递归型树结构,是一种最理想、最灵活的存储层次树的数据结构。本节说明一些递归处理的问题,包括数据装载、树的展开、递归查询、树的平面化等技术实现。为了保持销售订单示例的完整性,本节的实验将会使用另一个与业务无关的通用示例。
1. 建立表并添加实验数据
-- 在MySQL的source库中建立源表
use source;
create table tree
(
c_child int,
c_name varchar(100),
c_parent int
);
create index idx1 on tree (c_parent);
create unique index tree_pk on tree (c_child);
-- 递归树结构,c_child是主键,c_parent是引用c_child的外键
alter table tree add (constraint tree_pk primary key (c_child));
alter table tree add (constraint tree_r01 foreign key (c_parent) references tree (c_child));
-- 添加数据
insert into tree (c_child, c_name, c_parent) values (1, '节点1', null);
insert into tree (c_child, c_name, c_parent) values (2, '节点2', 1);
insert into tree (c_child, c_name, c_parent) values (3, '节点3', 1);
insert into tree (c_child, c_name, c_parent) values (4, '节点4', 1);
insert into tree (c_child, c_name, c_parent) values (5, '节点5', 2);
insert into tree (c_child, c_name, c_parent) values (6, '节点6', 2);
insert into tree (c_child, c_name, c_parent) values (7, '节点7', 3);
insert into tree (c_child, c_name, c_parent) values (8, '节点8', 3);
insert into tree (c_child, c_name, c_parent) values (9, '节点9', 3);
insert into tree (c_child, c_name, c_parent) values (10, '节点10', 4);
insert into tree (c_child, c_name, c_parent) values (11, '节点11', 4);
commit;
-- 在Hive的rds库中建立过渡表
use rds;
create table tree
(
c_child int,
c_name varchar(100),
c_parent int
);
-- 在Hive的dw库中建立相关维度表
use dw;
create table tree_dim
(
sk int,
c_child int,
c_name varchar(100),
c_parent int,
version int,
effective_date date,
expiry_date date
)
CLUSTERED BY (sk) INTO 8 BUCKETS
STORED AS ORC TBLPROPERTIES ('transactional'='true');
2. 数据装载
递归树结构的本质是,在任意时刻,每个父—子关系都是唯一的。通常,操作型系统只维护层次树的当前视图,因此,输入数据仓库的数据通常是当前层次树的时间点快照。这就需要由ETL过程来确定发生了哪些变化,以便正确记录历史信息。为了检测出过时的父—子关系,必须通过孩子键进行查询,然后将父亲作为结果返回。在这个例子中,对tree表采用整体拉取模式抽数据,tree_dim表的c_name和c_parent列上使用SCD2装载类型。也就是说,把c_parent当做源表的一个普通属性,当一个节点的名字或者父节点发生变化时,都增减一条新版本记录,并设置老版本的过期时间。这样的装载过程和销售订单的例子并无二致。
(1)建立init_etl_tree.sh、init_etl_tree.sql、regular_etl_tree.sh、regular_etl_tree.sql四个脚本实现tree_dim维度表的初始装载和定期装载。
init_etl_tree.sh文件用于初始装载,其内容如下:
#!/bin/bash sqoop import --connect jdbc:mysql://cdh1:3306/source?useSSL=false --username root --password myassword --table tree --hive-import --hive-table rds.tree --hive-overwrite beeline -u jdbc:hive2://cdh2:10000/dw -f init_etl_tree.sqlinit_etl_tree.sql文件内容如下:
USE dw; -- 清空表 TRUNCATE TABLE tree_dim; INSERT INTO tree_dim SELECT ROW_NUMBER() OVER (ORDER BY t1.c_child) + t2.sk_max , t1.c_child , t1.c_name , t1.c_parent , 1 , '2016-03-01' , '2200-01-01' FROM rds.tree t1 CROSS JOIN (SELECT COALESCE(MAX(sk),0) sk_max FROM tree_dim) t2;regular_etl_tree.sh文件用于定期装载,其内容如下:
#!/bin/bash sqoop import --connect jdbc:mysql://cdh1:3306/source?useSSL=false --username root --password myassword --table tree --hive-import --hive-table rds.tree --hive-overwrite beeline -u jdbc:hive2://cdh2:10000/dw -f regular_etl_tree.sqlregular_etl_tree.sql文件内容如下:
-- 设置变量以支持事务
set hive.support.concurrency=true;
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.txn.manager=org.apache.hadoop.hive.ql.lockmgr.DbTxnManager;
set hive.compactor.initiator.on=true;
set hive.compactor.worker.threads=1;
USE dw;
-- 设置SCD的生效时间和过期时间
SET hivevar:cur_date = CURRENT_DATE();
SET hivevar:pre_date = DATE_ADD(${hivevar:cur_date},-1);
SET hivevar:max_date = CAST('2200-01-01' AS DATE);
-- 设置CDC的上限时间
INSERT OVERWRITE TABLE rds.cdc_time SELECT last_load, ${hivevar:cur_date} FROM rds.cdc_time;
-- SDC2设置过期
UPDATE tree_dim
SET expiry_date = ${hivevar:pre_date}
WHERE tree_dim.sk IN
(SELECT a.sk
FROM (SELECT sk,
c_child,
c_name,
c_parent
FROM tree_dim WHERE expiry_date = ${hivevar:max_date}) a LEFT JOIN
rds.tree b ON a.c_child = b.c_child
WHERE b.c_child IS NULL OR
( !(a.c_name <=> b.c_name)
OR !(a.c_parent <=> b.c_parent)
));
-- SCD2新增版本
INSERT INTO tree_dim
SELECT
ROW_NUMBER() OVER (ORDER BY t1.c_child) + t2.sk_max,
t1.c_child,
t1.c_name,
t1.c_parent,
t1.version,
t1.effective_date,
t1.expiry_date
FROM
(
SELECT
t2.c_child c_child,
t2.c_name c_name,
t2.c_parent c_parent,
t1.version + 1 version,
${hivevar:pre_date} effective_date,
${hivevar:max_date} expiry_date
FROM tree_dim t1
INNER JOIN rds.tree t2
ON t1.c_child = t2.c_child
AND t1.expiry_date = ${hivevar:pre_date}
LEFT JOIN tree_dim t3
ON t1.c_child = t3.c_child
AND t3.expiry_date = ${hivevar:max_date}
WHERE (!(t1.c_name <=> t2.c_name)
OR !(t1.c_parent <=> t2.c_parent)
)
AND t3.sk IS NULL) t1
CROSS JOIN
(SELECT COALESCE(MAX(sk),0) sk_max FROM tree_dim) t2;
-- 新增的记录
INSERT INTO tree_dim
SELECT
ROW_NUMBER() OVER (ORDER BY t1.c_child) + t2.sk_max,
t1.c_child,
t1.c_name,
t1.c_parent,
1,
${hivevar:pre_date},
${hivevar:max_date}
FROM
(
SELECT t1.* FROM rds.tree t1 LEFT JOIN tree_dim t2 ON t1.c_child = t2.c_child
WHERE t2.sk IS NULL) t1
CROSS JOIN
(SELECT COALESCE(MAX(sk),0) sk_max FROM tree_dim) t2;
-- 更新时间戳表的last_load字段
INSERT OVERWRITE TABLE rds.cdc_time SELECT current_load, current_load FROM rds.cdc_time;(2)测试装载过程
初始时源表数据的递归树结构如下图所示:
执行初始装载
./init_etl_tree.sh查询维度表数据
select * from dw.tree_dim;结果如下图所示:
修改源表数据,这次修改了所有节点的名称
use source; -- 修改名称 UPDATE tree SET c_name = '节点1_1' WHERE c_child = 1; UPDATE tree SET c_name = '节点2_1' WHERE c_child = 2; UPDATE tree SET c_name = '节点3_1' WHERE c_child = 3; UPDATE tree SET c_name = '节点4_1' WHERE c_child = 4; UPDATE tree SET c_name = '节点5_1' WHERE c_child = 5; UPDATE tree SET c_name = '节点6_1' WHERE c_child = 6; UPDATE tree SET c_name = '节点7_1' WHERE c_child = 7; UPDATE tree SET c_name = '节点8_1' WHERE c_child = 8; UPDATE tree SET c_name = '节点9_1' WHERE c_child = 9; UPDATE tree SET c_name = '节点10_1' WHERE c_child = 10; UPDATE tree SET c_name = '节点11_1' WHERE c_child = 11; COMMIT;将regular_etl.sql文件中的SET hivevar:cur_date = CURRENT_DATE();行改为SET hivevar:cur_date = '2016-07-27';后,执行定期装载
./regular_etl_tree.sh查询维度表数据
select * from dw.tree_dim;结果如下图所示:
修改源表数据,这次修改了部分节点的名称,并新增了两个节点。
use source; /*** 修改名称 ***/ UPDATE tree SET c_name = '节点1_2' WHERE c_child = 1; UPDATE tree SET c_name = '节点3_2' WHERE c_child = 3; UPDATE tree SET c_name = '节点5_2' WHERE c_child = 5; UPDATE tree SET c_name = '节点8_2' WHERE c_child = 8; UPDATE tree SET c_name = '节点11_2' WHERE c_child = 11; /*** 增加新的根节点,并改变原来的父子关系 ***/ INSERT INTO tree VALUES (12, '节点12', NULL); INSERT INTO tree VALUES (13, '节点13', 12); UPDATE tree SET c_parent = 12 WHERE c_child = 1; UPDATE tree SET c_parent = 13 WHERE c_child = 3; COMMIT;此时源表数据的递归树结构如下图所示:
将regular_etl.sql文件中的SET hivevar:cur_date = CURRENT_DATE();行改为SET hivevar:cur_date = '2016-07-28';后,执行定期装载
./regular_etl_tree.sh查询维度表数据
select * from dw.tree_dim;结果如下图所示:
修改源表数据,这次修改了部分节点的名称,并删除了三个节点。
use source; /*** 修改名称 ***/ UPDATE tree SET c_name = '节点2_2' WHERE c_child = 2; UPDATE tree SET c_name = '节点3_3' WHERE c_child = 3; /*** 删除子树 ***/ DELETE FROM tree WHERE c_child = 10; DELETE FROM tree WHERE c_child = 11; DELETE FROM tree WHERE c_child = 4; COMMIT;此时源表数据的递归树结构如下图所示:
将regular_etl.sql文件中的SET hivevar:cur_date = CURRENT_DATE();行改为SET hivevar:cur_date = '2016-07-29';后,执行定期装载
./regular_etl_tree.sh查询维度表数据
select * from dw.tree_dim;结果如下图所示:
从查询结果看到,现在维度表中共有31条记录,其中新增2条当前版本记录(因为改名),更新了5行老版本的过期时间(2行因为改名,3行因为节点删除),被设置为'2016-07-28'。
装载实验完成后,还原regular_etl.sh脚本,将文件中的SET hivevar:cur_date = DATE_ADD(CURRENT_DATE(),2);行改为SET hivevar:cur_date = CURRENT_DATE();
3. 树的展开
有些BI工具的前端不支持递归,这时递归层次树的数据交付技术就是“展开”(explode)递归树。展开是这样一种行为,一边遍历递归树,一边产生新的结构,该结构包含了贯穿树中所有层次的每个可能的关系。展开的结果是一个非递归的关系对表,该表也可能包含描述层次树中关系所处位置的有关属性。下图展示了一个展开树的例子,图中左侧为原递归树数据,右边为树展开后的数据。
将树展开消除了对递归查询的需求,因为层次不再需要自连接。当按这种表格形式将数据交付时,使用简单的SQL查询就可以生成层次树报表。下面说明树展开的实现。
-- 建立展开后的目标表 use rds; create table tree_expand ( c_child int, c_parent int, distance int );许多关系数据库都提供递归查询的功能,例如在Oracle中,就可以使用下面的代码展开递归树。
-- Oracle实现
insert into tree_expand (c_child, c_parent, distance)
with rec (c_child, c_parent, distance) as (
select c_child, c_child, 0
from tree
union all
select r.c_child, s.c_parent, r.distance + 1
from rec r
join tree s
on r.c_parent = s.c_child
where s.c_parent is not null
)
select * from rec; 目前Hive还没有递归查询功能,但可以使用UDTF来实现。下面的代码取自 https://www.pythian.com/blog/recursion-in-hive/(原来的代码中缺少import部分),它使用Scala语言实现了一个UDTF用于展开树。关于UDTF的API说明,参考 https://hive.apache.org/javadocs/r0.10.0/api/org/apache/hadoop/hive/ql/udf/generic/GenericUDTF.html。
package UDF
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF
import org.apache.hadoop.hive.serde2.objectinspector.primitive
import org.apache.hadoop.hive.serde2.objectinspector.{ObjectInspectorFactory, StructObjectInspector, ObjectInspector, PrimitiveObjectInspector}
class ExpandTree2UDTF extends GenericUDTF {
var inputOIs: Array[PrimitiveObjectInspector] = null
val tree: collection.mutable.Map[String,Option[String]] = collection.mutable.Map()
override def initialize(args: Array[ObjectInspector]): StructObjectInspector = {
inputOIs = args.map{_.asInstanceOf[PrimitiveObjectInspector]}
val fieldNames = java.util.Arrays.asList("id", "ancestor", "level")
val fieldOI = primitive.PrimitiveObjectInspectorFactory.javaStringObjectInspector.asInstanceOf[ObjectInspector]
val fieldOIs = java.util.Arrays.asList(fieldOI, fieldOI, fieldOI)
ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames, fieldOIs);
}
def process(record: Array[Object]) {
val id = inputOIs(0).getPrimitiveJavaObject(record(0)).asInstanceOf[String]
val parent = Option(inputOIs(1).getPrimitiveJavaObject(record(1)).asInstanceOf[String])
tree += ( id -> parent )
}
def close {
val expandTree = collection.mutable.Map[String,List[String]]()
def calculateAncestors(id: String): List[String] =
tree(id) match { case Some(parent) => id :: getAncestors(parent) ; case None => List(id) }
def getAncestors(id: String) = expandTree.getOrElseUpdate(id, calculateAncestors(id))
tree.keys.foreach{ id => getAncestors(id).zipWithIndex.foreach{ case(ancestor,level) => forward(Array(id, ancestor, level)) } }
}
} 将这段代码编译成jar包后,就可以提供给Hive使用。这里生成的jar文件名为Test-0.0.1-SNAPSHOT.jar。
使用下面的命令将相关jar包复制到HDFS。
hdfs dfs -put Test-0.0.1-SNAPSHOT.jar /tmp/ hdfs dfs -put scala-library.jar /tmp/执行下面的HiveQL进行测试。
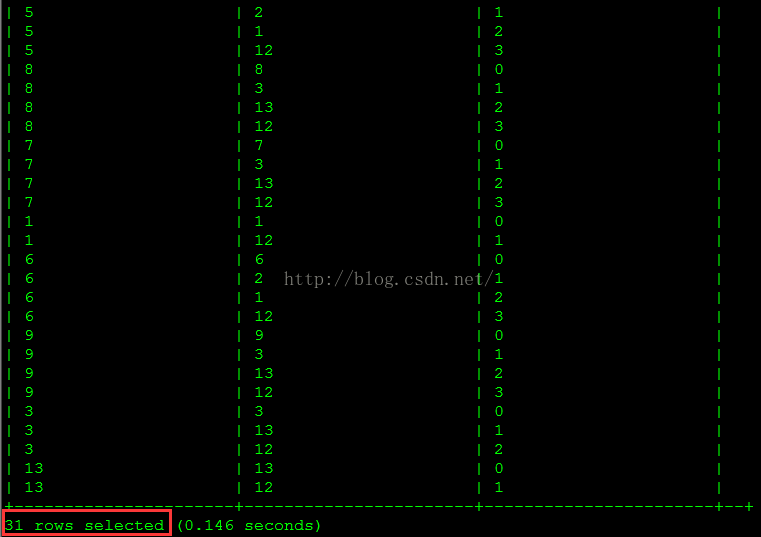
-- 添加运行时jar包 add jar hdfs://cdh2:8020/tmp/Test-0.0.1-SNAPSHOT.jar; add jar hdfs://cdh2:8020/tmp/scala-library.jar; -- 建立函数 create function expand_tree as 'UDF.ExpandTree2UDTF'; -- 使用UDTF生成展开后的数据 insert overwrite table rds.tree_expand select expand_tree(cast(c_child as string), cast(c_parent as string)) from rds.tree; -- 查询树展开后的数据 select * from rds.tree_expand;查询结果如下图所示。
4. 查询
Hive本身还没有递归查询功能,但正如前面提到的,使用简单的SQL查询递归树展开后的数据,即可生成层次树报表,例如下面的HiveQL语句实现了从下至上的树的遍历。
select c_child, concat_ws('/',collect_set(cast(c_parent as string))) as c_path from tree_expand group by c_child; 查询结果如下图所示。
5. 递归树的平面化
递归树适合于数据仓库,而非递归结构则更适合于数据集市。前面的递归树展开用于消除递归查询,但缺点在于为检索与实体相关的属性必须执行额外的连接操作。而对于层次树来说,很常见的情况是,层次树元素所拥有的唯一属性就是描述属性(本例中的c_name字段),并且树的最大深度是固定的(本例是4层)。对这种情况,最好是将层次树作为平面化的1NF结或者2NF结构交付给数据集市。这类平面化操作对于平衡的层次树发挥得最好,但将缺失的层次置空可能可能会形成不整齐的层次树,因此它对深度未知的层次树(列数不固定)来说并不是一种有用的技术。下面说明递归树平面化的实现。
-- 建立展开后的目标表 use rds; create table tree_complanate ( c_0 int, c_0_name varchar(100), c_1 int, c_1_name varchar(100), c_2 int, c_2_name varchar(100), c_3 int, c_3_name varchar(100) );下面的语句生成递归树平面化后的数据,每个叶子节点一行。
insert overwrite table rds.tree_complanate
select t0.c_0 c_0,t1.c_name c_0_name,
t0.c_1 c_1,t2.c_name c_1_name,
t0.c_2 c_2,t3.c_name c_2_name,
t0.c_3 c_3,t4.c_name c_3_name
from (select list[3] c_0,list[2] c_1,list[1] c_2,list[0] c_3
from (select c_child,split(c_path,'/') list
from (select c_child, concat_ws('/',collect_set(cast(c_parent as string))) as c_path
from tree_expand
group by c_child) t) t
where size(list) = 4) t0
inner join (select * from tree) t1 on t0.c_0= t1.c_child
inner join (select * from tree) t2 on t0.c_1= t2.c_child
inner join (select * from tree) t3 on t0.c_2= t3.c_child
inner join (select * from tree) t4 on t0.c_3= t4.c_child; 查询数据
select c_0, c_0_name, c_1, c_1_name, c_2, c_2_name, c_3, c_3_name from rds.tree_complanate;
查询结果如下图所示。
